Upstage AI Lab 2기
2024년 3월 12일 (화) Day_062
내일
[PyTorch] (3-6) RNN 구현.ipynb
[PyTorch] (3-4) DNN 구현(3).ipynb
현재 밀린 인강
DNN 구현
RNN구현
디버깅
파이토치 라이트닝
오늘 들어야 하는 강의
하이드라
파이토치 라이트닝과 하이드라
오늘의 todo
전이학습이란
timm과 Hugging Face
디버깅
파이토치 라이트닝
하이드라
파이토치 라이트닝과 하이드라
[PyTorch] (4-1) 전이학습이란
전이학습을 하기 위해서는 pretrained 모델이 필요
pretrained 모델이란? : 대규모 데이터셋을 기반으로 학습된 모델
task에 대한 일반적 지식을 가지고 있음
foundation model
전이학습 pretrained 모델의 지식을 다른 task에 활용하는 것
1. fine-tuning
pretrained model을 그대로 쓰거나
pretrained model에 레이어를 추가
pretrained model 부분도 같이 training 할수도 있고 freeze 시킬 수도 있음
2. domain adaptation
domain이란? 데이터가 속하는 분포
그 외 :
multi-task learning - 하나의 모델, 여러개의 classifier
zero-shot learning - 완전히 다른 task로 학습한 모델을 새로운 task에서 잘 작동하도록
one/few-shot learning - zero-shot learning과 비슷하지만 몇 개의 예시를 줌
전이 학습 전략
1. 도메인이 비슷할 때
- dataset이 비교적 작을 때 : 마지막 classifier만 추가 학습 (나머지 freeze)
- dataset이 비교적 클 때 : pre-trained의 일부 또는 전체까지도 추가 학습하는 것을 선택할 수도 있음.
2. 도메인이 매우 다를 때
- dataset이 작으면 학습이 어려움 - 전이학습에 부적
- dataset이 꽤 클 때 - 꽤 많은 레이어를 학습해야 함. (pre-trained model이 꽤 많이 수정되어야 함)
Learning Rate 전략
- pretrained model을 크게 업데이트 하면 pretrained model의 일반적 지식을 전이 학습의 대상인 dataset에 오버피팅 시키는 결과를 초래
- ∴ 일반적인 지식을 크게 업데이트 하지 않기 위해서 pretraining 할 때보다 훨씬 작은 lr로 학습시켜야 함.
but. pretrained model 을 freeze할 경우, learning rate의 영향을 받지 않는다는 것을 명심
pretrained model을 customize하고자 하는 수요 증대
timm (Pytorch Image Model) : CV 분야
import timm
timm.list_models() - 제공되는 모델 리스트를 볼 수 있음
timm.create_model("model이름", pretrained=True) 로 사전학습 모델의 weight를 불러올 수 있음.
Hugging Face : (초기에는) NLP 분야, 최근에는 CV, multi-modal, audio 등까지 확장
gradio : demo page를 만들 수 있는 라이브러리까지 제공?
모델 예시 참고, pip install로 라이브러리 설치
[PyTorch] (4-2) timm과 Hugging Face를 통한 전이학습
!pip install timm==0.9.2 -q
import timm
timm.list_models()
timm.list_models() 를 다 불러오면 너무 기니까 쿼리를 입력해서 원하는 모델에 대한 리스트만 볼 수도 있음.
timm.list_models('resnet*')
but, 이 모델들이 다 pretrained weight를 갖고 있는 것이 아님
timm.list_models('resnet50', pretrained=True)

model = timm.create_model('resnet50', pretrained=True)
model2 = timm.create_model('resnet50', pretrained = True, num_classes = 10) # 마지막 output class 개수 10개로 조정
model2 # num class 를 임의로 조정하면 fc layer 의 weight가 초기화됨num_classes = 10 으로 수정하면 마지막 fc layer가 수정이 되고
random initialization으로 weight도 초기화 되어 생성됨.



Epoch [7/100], Train Loss: 0.1407, Train Accuracy: 0.9509 Valid Loss: 0.5916, Valid Accuracy: 0.8291

Full Fine tuning model accuracy : 0.8137
마지막 fc layer 만 fine tuning
for para in model.parameters(): # 모든 layer freeze 하기
para.requires_grad = False
for para in model.fc.parameters(): # fc layer 만 학습하기
para.requires_grad = True
para.requires_grad = False -> 학습을 시키지 않겠다.

Epoch [4/100], Train Loss: 1.6291, Train Accuracy: 0.4402 Valid Loss: 3.4171, Valid Accuracy: 0.4495

Only FC Layer Fine tuning model accuracy : 0.4408
lr = 1e-1 # learning rate 높게 설정
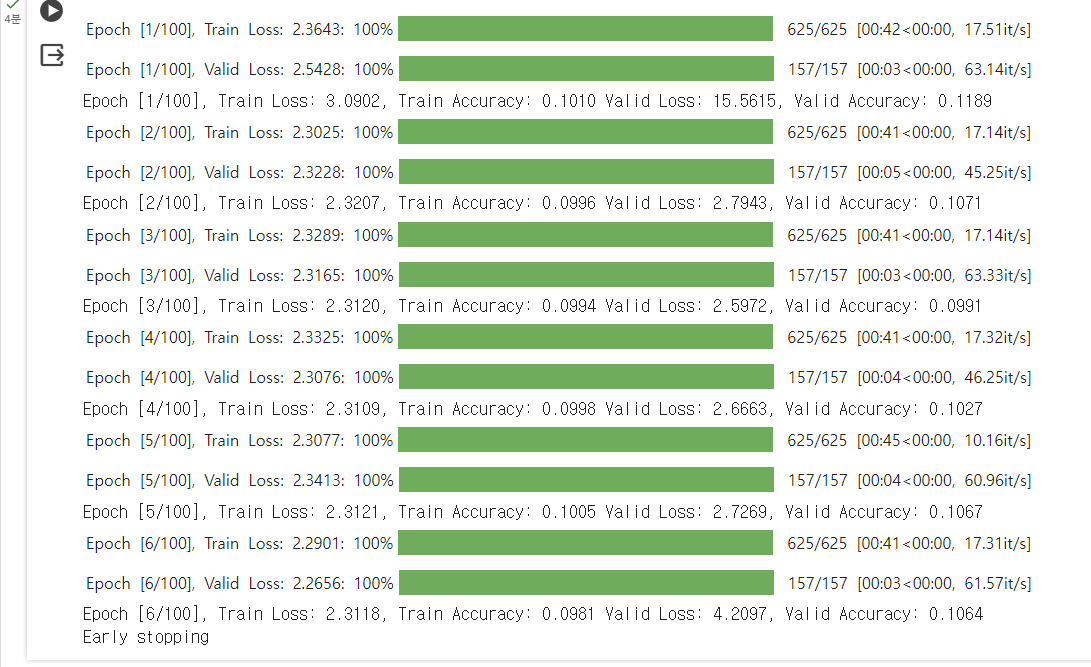
Epoch [6/100], Train Loss: 2.3118, Train Accuracy: 0.0981 Valid Loss: 4.2097, Valid Accuracy: 0.1064
Large learning rate model accuracy : 0.1022
- pretrained model의 기존 학습을 muddled up 한 느낌.
lr = 1e-5 # 기존보다 더 작게 설정
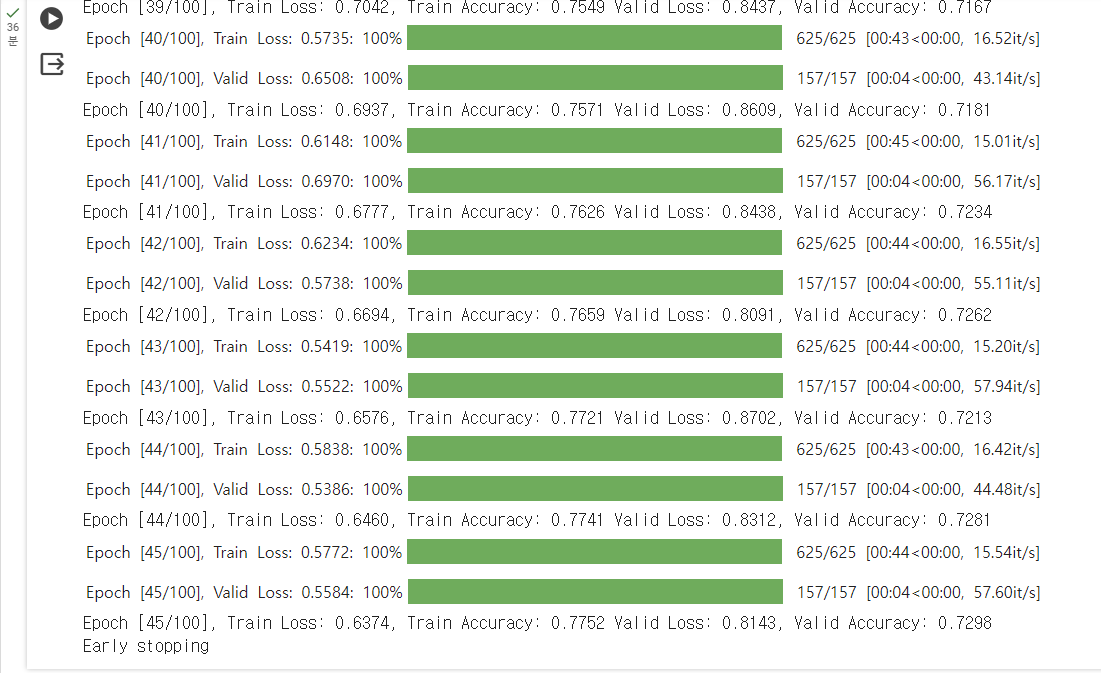
Epoch [45/100], Train Loss: 0.6374, Train Accuracy: 0.7752 Valid Loss: 0.8143, Valid Accuracy: 0.7298
Small learning rate model accuracy : 0.7193
Full Fine tuning model accuracy : 0.8137
Only FC Layer Fine tuning model accuracy : 0.4408
Large learning rate model accuracy : 0.1022
Small learning rate model accuracy : 0.7193
이로부터 알 수 있는 것은 적정한 learning rate를 찾는것이 중요하다.
- 너무 크게 줄 경우 거의 학습이 안 됐다고 볼 수 있다.
Hugging Face
BERT 훈련시키기 위한 모델 전처리 : input data의 문장 시작을 [CLS] 토큰으로 표시, 문장의 끝을 [SEP] 토큰으로 표시
train['review'] = train['review'].apply(lambda x: f'[CLS] {x} [SEP]')
val['review'] = val['review'].apply(lambda x: f'[CLS] {x} [SEP]')
test['review'] = test['review'].apply(lambda x: f'[CLS] {x} [SEP]')
train['review'] = train['review'].apply(lambda x : f'[CLS] {x} [SEP]')
val['review'] = val['review'].apply(lambda x : f'[CLS] {x} [SEP]')
test['review'] = test['review'].apply(lambda x : f'[CLS] {x} [SEP]')
# 각 문장들만 추출
train_sentences = train['review'].values
val_sentences = val['review'].values
test_sentences = test['review'].values
# 정답값 추출
train_label = train['sentiment'].values
val_label = val['sentiment'].values
test_label = test['sentiment'].values
train_sentences = train['review'].values
val_sentences = val['review'].values
test_sentences = test['review'].values
train_label = train['sentiment'].values
val_label = val['sentiment'].values
test_label = test['sentiment'].values
pretrained model에서 사용했던 tokenizer를 사용해야 함
# BERT의 tokenizer로 문장을 토큰으로 분리
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-cased') # 기존에 학습된 BERT tokenizer 불러오기
from transformer import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
train_tokenized_texts = list(map(lambda x: tokenizer.tokenize(x), train_sentences))
val_tokenized_texts = list(map(lambda x: tokenizer.tokenize(x), val_sentences))
test_tokenized_texts = list(map(lambda x: tokenizer.tokenize(x), test_sentences))
train_tokenized_texts = list(map(lambda x : tokenizer.tokenize(x), train_sentences))
val_tokenized_texts = list(map(lambda x : tokenizer.tokenize(x), val_sentences))
test_tokenized_texts = list(map(lambda x : tokenizer.tokenize(x), test_sentences))
# 입력 토큰의 최대 시퀀스 길이
MAX_LEN = 128
# 토큰을 숫자 인덱스로 변환
train_input_ids = list(map(lambda x: tokenizer.convert_tokens_to_ids(x), train_tokenized_texts)) # convert_tokens_to_ids로 정수 형태로 변환해주기
val_input_ids = list(map(lambda x: tokenizer.convert_tokens_to_ids(x), val_tokenized_texts))
test_input_ids = list(map(lambda x: tokenizer.convert_tokens_to_ids(x), test_tokenized_texts))
MAX_LEN = 128
train_input_ids = list(map(lambda x : tokenizer.convert_tokens_to_ids(x), train_tokenized_texts))
val_input_ids = list(map(lambda x : tokenizer.convert_tokens_to_ids(x), val_tokenized_texts))
test_input_ids = list(map(lambda x : tokenizer.convert_tokens_to_ids(x), test_tokenized_texts))
but 여기까지만 하면 input 길이가 제각각 (input 마다 토큰 개수가 다름)
dataloader를 통해서 미니배치 단위로 잘라줄 때 input sample 마다 길이가 다르면 묶어줄 수가 없음.
zero padding을 해줌으로써 모든 input sample의 길이를 맞춰줌
def zero_padding(id_list,max_len):
return np.array([i[:max_len] if len(i) >= max_len else i + [0] * (max_len - len(i)) for i in id_list])
def zero_padding(id_list, max_len):
return np.array([i[:max_len] if len(i) >= max_len else i + [0] * (max_len - len(i)) for i in id_list])
BERT는 padding인지 아닌지 페어해주는 mask가 필요함.
train_inputs = torch.tensor(train_input_ids) # train set의 input token id들
train_labels = torch.tensor(train_label) # train set의 label들
train_masks = torch.tensor(train_masks) # train set의 mask
validation_inputs = torch.tensor(val_input_ids) # valid set의 input token id들
validation_labels = torch.tensor(val_label) # valid set의 label들
validation_masks = torch.tensor(val_masks) # valid set의 mask
test_inputs = torch.tensor(test_input_ids) # test set의 input token id들
test_labels = torch.tensor(test_label) # test set의 label들
test_masks = torch.tensor(test_masks) # test set의 mask
train_inputs = torch.tensor(train_input_ids)
train_labels = torch.tensor(train_label)
train_masks = torch.tensor(train_masks)
validation_inputs = torch.tensor(val_input_ids)
validation_labels = torch.tensor(val_label)
validation_masks = torch.tensor(val_masks)
test_inputs = torch.tensor(test_input_ids)
test_labels = torch.tensor(test_label)
test_masks = torch.tensor(test_masks)
class EmotionData(torch.utils.data.Dataset): # custom 데이터셋 구성
def __init__(self, inputs, masks, labels):
self.inputs = inputs
self.masks = masks
self.labels = labels
def __len__(self):
return len(self.inputs)
def __getitem__(self,idx):
inputs_value = self.inputs[idx]
masks_value = self.masks[idx]
labels_value = self.labels[idx]
return inputs_value, masks_value, labels_value
class EmotionData(torch.utils.data.Dataset):
def __init__(self, inputs, masks, labels):
self.inputs = inputs
self.masks = masks
self.labels = labels
def __len__(self):
return len(self.inputs)
def __getitem__(self, idx):
inputs_value = self.inputs[idx]
masks_value = self.masks[idx]
labels_value = self.labels[idx]
return inputs_value, masks_value, labels_value
[PyTorch] (3-4) DNN 구현(3)
(자연어 처리)
custom dataset 구축에 focus
dataset : Medium Dataset
task : next word prediction
크롤링 된 데이터셋이라 전처리 필수. 원치 않는 특수문자가 많이 있을 수 있음 -> no-break space
no-break space : 단어나 문장 사이 공백이 줄바꿈으로 인해 분리해서 인식되지 않도록 사용되는 공백
re 라이브러리와 unicode를 이용해서 전처리
정규 표현식
참고자료 :
re 라이브러리 : 정규 표현식 모듈 - 특정 규칙이 있는 텍스트 데이터를 빠르게 정제
1) 정규 표현식 문법
| 특수문자 | |
| . | 한 개의 임의의 문자 (\n 제외) |
| ? | 앞의 문자가 0개 또는 1개 |
| * | 앞의 문자가 0개 이상 |
| + | 앞의 문자가 1개 이상 |
| ^ | 뒤의 문자열로 시작 |
| $ | 앞의 문자열로 끝 |
| {num} | num만큼 반복 |
| {num1, num2} | num1 이상 num2 이하만큼 반복 이것으로 ?, *, + 대체 가능 |
| {num, } | num 이상만큼 반복 |
| [ ] | [ ] 안의 문자들 중 한개의 문자와 매치 [a-z]처럼 범위 지정 가능 [a-zA-Z]는 알파벳 전체를 의미 - 문자열에 알파벳이 존재하면 매치o |
| [^문자] | 해당 문자를 제외한 문자를 매치 |
| | | A|B -> A 또는 B |
(나중에 마저 이해하기)
def cleaning_text(text):
cleaned_text = re.sub( r"[^a-zA-Z0-9.,@#!\s']+", "", text) # 특수문자 를 모두 지우는 작업을 수행합니다.
cleaned_text = cleaned_text.replace(u'\xa0',u' ') # No-break space를 unicode 빈칸으로 변환
cleaned_text = cleaned_text.replace('\u200a',' ') # unicode 빈칸을 빈칸으로 변환
return cleaned_text
def cleaning_text(text):
cleaned_text = re.sub(r"[^a-zA-Z0-9.,@#!\s']+", "", text)
# 특수문자 모두 삭제
cleaned_text = cleaned_text.replace(u'\xa0', u' ')
# No-break space를 유니코드 빈칸으로 변환
cleaned_text = cleaned_text.replace('\u200a', ' ')
#유니코드 빈칸을 빈칸으로 변환
return cleaned_text
모델에게 자연어를 input으로 넣어줄 수 없기 때문에 숫자로 바꾸는 과정 필요
이 과정을 위해 tokenizer로 tokenizing을 우선 진행
then 숫자로 변환하는 과정이 필요
(07:48)
[PyTorch] (3-6) RNN 구현
next word prediction을 진행
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day067] ML Advanced - CH02. 파생 변수 생성 ~ CH03. 변수 선택 (0) | 2024.03.18 |
|---|---|
| Upstage AI Lab 2기 [Day066] ML Advanced - CH01. 데이터 전처리 (0) | 2024.03.18 |
| Upstage AI Lab 2기 [Day061] (0) | 2024.03.11 |
| Upstage AI Lab 2기 [Day060] (0) | 2024.03.08 |
| Upstage AI Lab 2기 [Day060] (0) | 2024.03.08 |


