Upstage AI Lab 2기
2024년 5월 7일 (화) Day_100
CH3. Encoder Model (BERT)
Part1. Transfer Learning이란
Transfer Learning
: 특정 도메인으로부터 학습된 모델을 비슷한 도메인 task 수행에 재사용하는 방법.
= Pre-training + Fine-tuning
Pre-training : 도메인에 대한 전반적인 특징을 학습
Fine-tuning : Pre-trained parameter를 task에 맞춰 조정
note : pre-trained 모델은 한개만 있으면 되고, task의 개수 만큼 fine-tuned model 있음. 레이블링 없는 데이터 활용 가능
ELMo(Embeddings from Language Models)
(before ELMo : Word2vec, GloVe 단어임베딩 - 위치정보x, 다의어 반영x, 문맥반영x)
ELMo : 문장 전체 input, 2개 층으로 이루어진 순방향 LSTM과 역방향 LSTM을 독립적으로 학습

Upper LSTM : 문맥 정보 학습
Lower LSTM : 문법 정보 학습
→ Contextualized Word Embedding : concat hidden layers from forward LSTM & backward LSTM
: 이전 토큰과 이후 토큰에 대한 정보가 반영되고 단어의 순서에 따라 임베딩 값이 달라지기 때문에 문맥정보를 반영
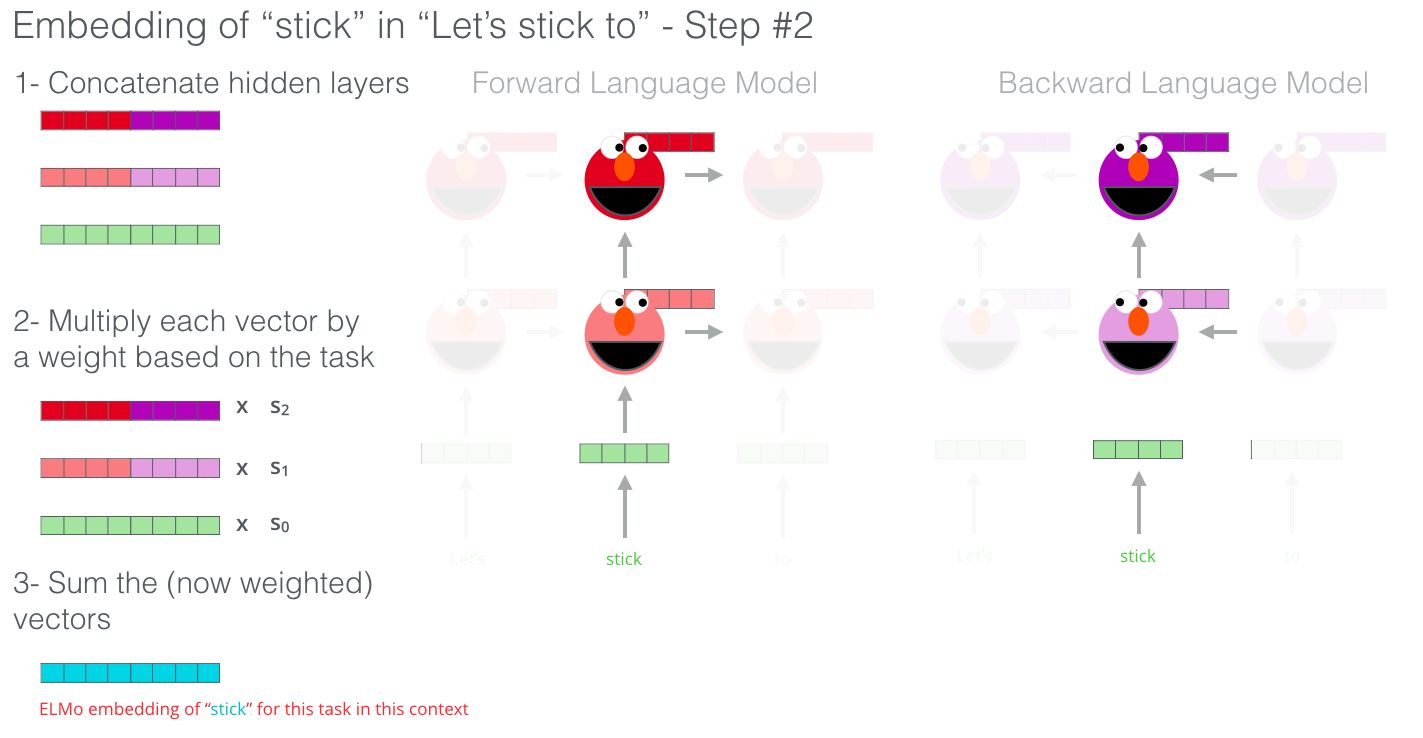
task 에 맞도록 가중치 조정 - 문맥이 중요할 경우 upper LSTM 가중치 ↑, 구조가 중요할 경우 lower LSTM 가중치 ↑, 순방향과 역방향 LSTM에 대한 가중치도 조정.
ELMo 의 장점 : 다의어 정보 표현 가능, ELMo 임베딩 만으로도 성능 향상 가능.
NLP에서는 PLM(Pretrained Language Model) 활용이 대세

Part2. BERT 이해하기
BERT(Bidirectional Encoder Representation from Transformers)
: Transformer의 인코더만으로 구성
하나의 모델이 양방향으로 읽어 나가며 임베딩 수행 + transformer 이용하여 단어간 관계(attention) 파악
(chatGPT 이전 대세)
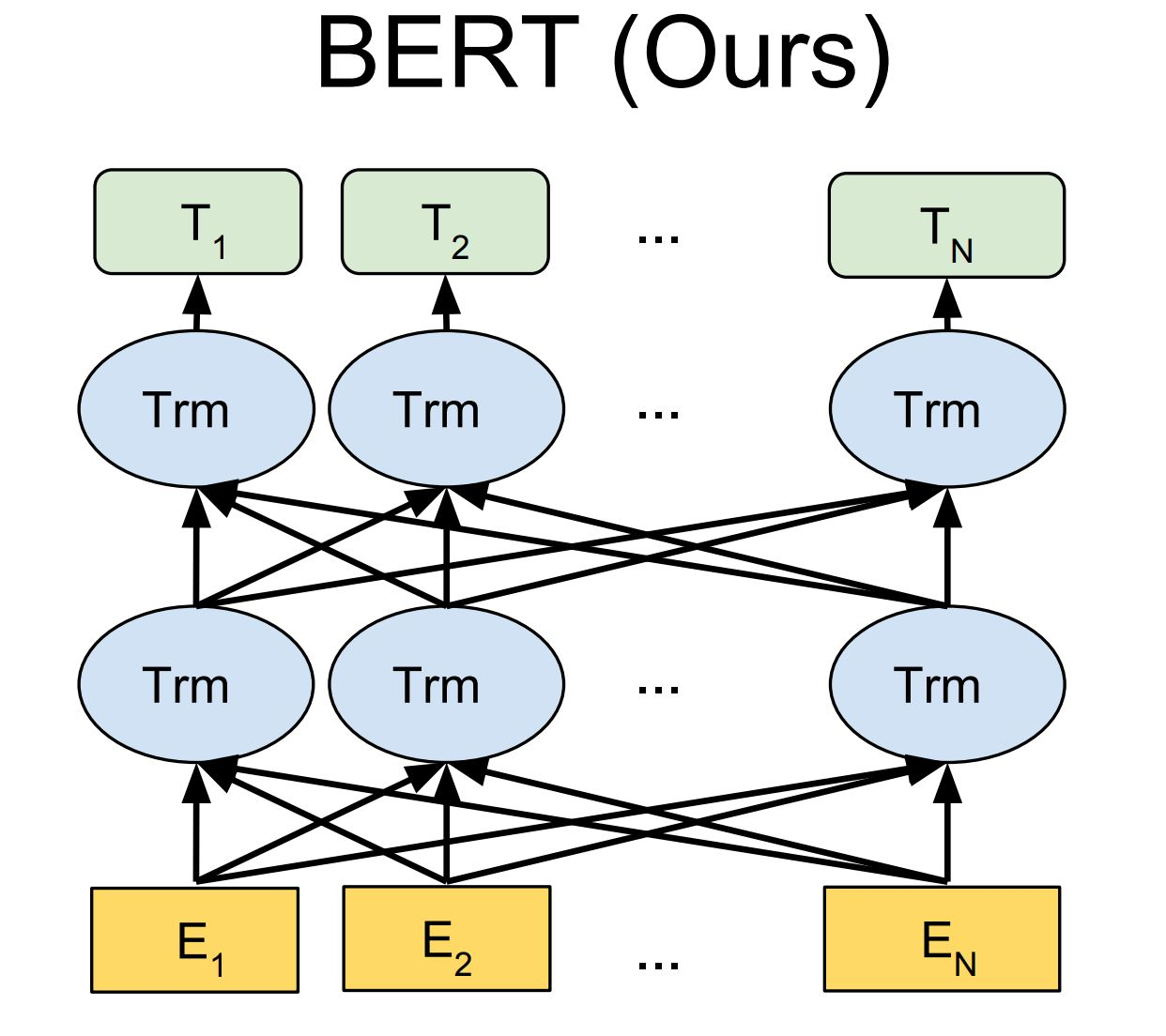
BERT-Base : 12 layers of transformer encoder with 12 self-attention heads, 768 hidden units per layer
BERT-Large : 24 layers of transformer encoder with 16 self-attention heads
입력 임베딩
[CLS] : 모든 문장의 첫 번째 토큰
[SEP] : 서로 다른 문장 구별 + Segment Embeddings 추가 가능
Position Embeddings

Pretraining BERT
MLM(Masked Language Model) + NSP(Next Sentence Prediction)
→ 레이블이 필요 없어 다량의 데이터 사용 가능 → pretraining이 가능해짐!
note : 제약조건없는 양방향 학습 → multi-layer 구조상 간접참조, 올바른 학습 불가
MLM(Masked Language Model)
- 문장에서 무작위 단어 마스킹, 마스킹 된 토큰 예측하는 방식으로 학습. 단어 간 관계.
(각 문장의 토큰 중 15% → 80% [MASK]로 치환, 10% 다른 단어 치환, 10% 보존)
NSP(Next Sentence Prediction)
- 두 문장의 관련성 예측. 문장과 문장의 관계 또는 document 전체에 대한 정보 파악.
(두 문장을 [SEP]토큰으로 이어붙임. 50%는 실제, 50%는 데이터에서 임의로 선택)
BERT로 수행가능한 downsream tasks
(classifier = FNN+softmax)

1. Single Sentence Classification : 문장의 종류 분류. [CLS]의 임베딩 벡터를 classifier layer에 입력

2. Sentence Pair Classification : [SEP]로 이어진 두 문장 간 관계 분류. [CLS]의 임베딩 벡터를 classifier layer에 입력

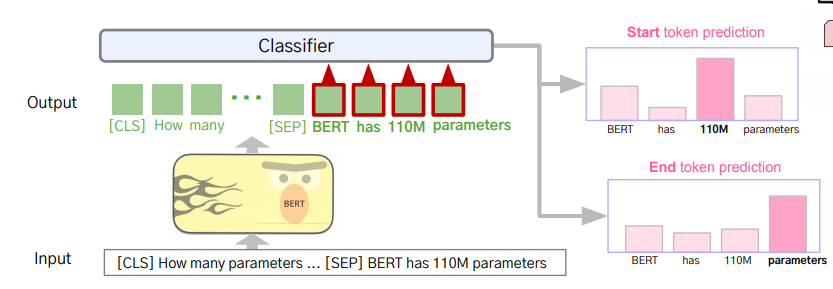
3. Question Answering : 문장 내 정답 위치 예측. [SEP] 이후 토큰들에 대해 Start token과 End token 예측
4. Single Sentence Tagging : 모든 토큰에 대해 태그(개체명/품사) 예측

5. BERT as Embedding via Feature Extraction

Part3. Tokenizer 이해하기
Tokenizer : 입력 문장을 토큰 단위로 분해, 사전에 매칭하여 id로 입력
토큰화 품질 ∝ pre-training 결과
Subword Tokenizer : 단어를 하위 단어로 분리·전처리, OOV(Out-Of-Vocabulary)/희귀단어/신조어 등의 문제 완화
1. BPE(Byte Pair Encoding) : character 단위로 분해 → 가장 많이 등장한 pair를 vocab에 update
2. WordPiece : BERT에 사용, 전체 글자 중 쌍으로 등장하는 빈도수가 높은 문자열 우선 병합. 학습데이터 환경 고려.
참고자료:
https://jalammar.github.io/illustrated-bert/
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day101] NLP - Decoder Model (GPT) (이론) (0) | 2024.05.07 |
|---|---|
| Upstage AI Lab 2기 [Day100] NLP (실습) (0) | 2024.05.07 |
| Upstage AI Lab 2기 [Day100] NLP (0) | 2024.05.06 |
| Upstage AI Lab 2기 [Day095] CV - Generation (0) | 2024.04.29 |
| Hydra (0) | 2024.04.16 |



