강의 자료 : https://learn.deeplearning.ai/courses/building-evaluating-advanced-rag/lesson/1/introduction
Advanced Techniques for RAG
1. sentence-window retrieval
2. auto-merging retrieval
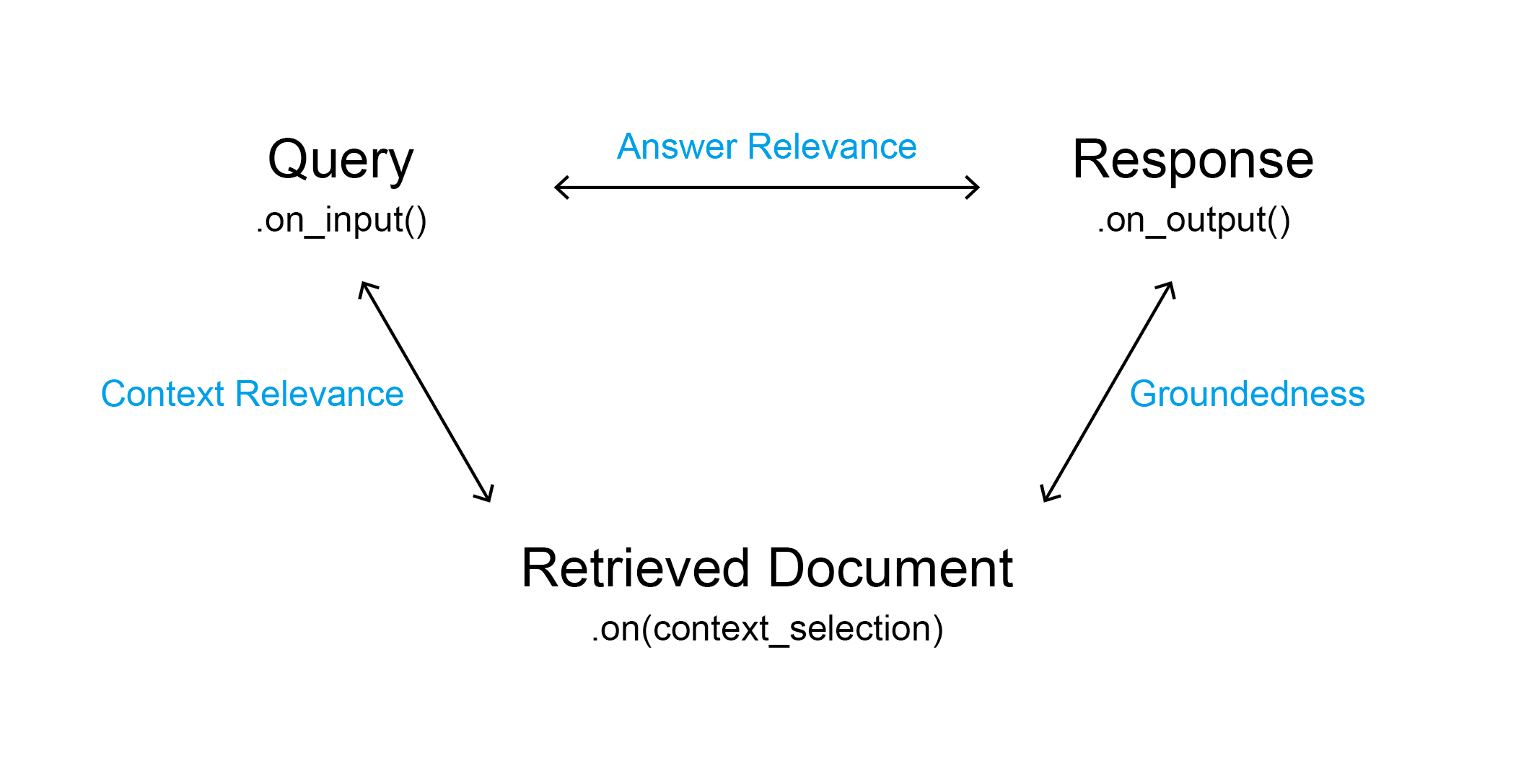
Evaluation of LLM QA System
1. context relevance
2. groundedness
3. answer relevance
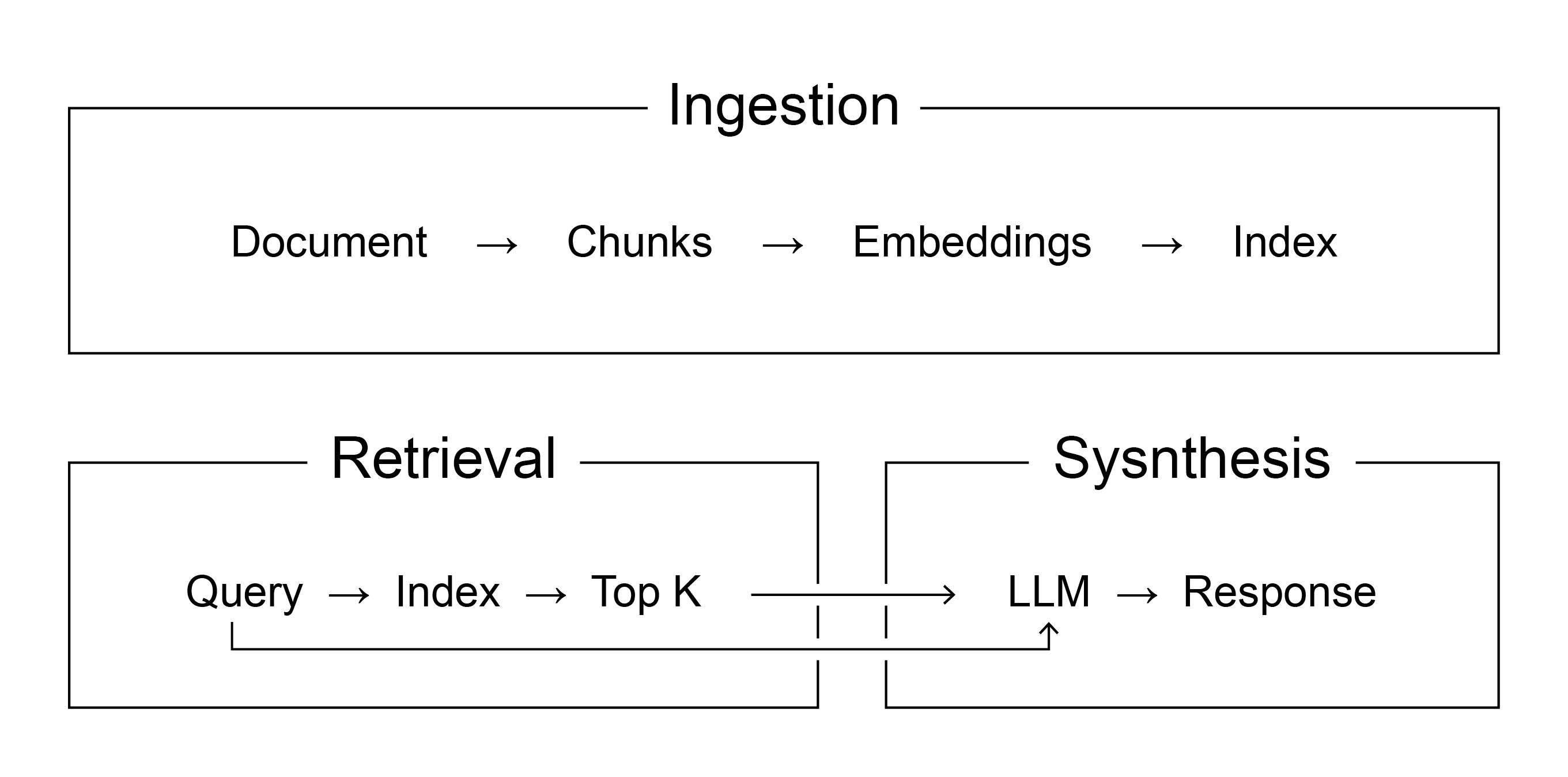
Advanced RAG pipeline
!pip install llama_index trulens_eval
from llama_index import ServiceContext, StorageContext
Part 1. Advanced RAG pipeline
from llama_index import SimpleDirectoryReader, Document
documents = SimpleDirectoryReader().load_data()
# type(documents)
# <class 'list'>
# type(documents[0])
# <class 'llama_index.schema.Document'>
document = Document(text="\n\n".join([doc.text for doc in documents]))
SimpleDirectoryReader 로 load 할 경우 여러 개의 llama.index.schema.Document로 쪼개지기 때문에 Document로 하나로 합쳐줘야 함.
1. Ingestion Pipeline
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import OpenAI
service_context = ServiceContext.from_defaults(
llm = OpenAI(model = "", temperature = 0.1),
embed_model = "" # huggingface model
)
index = VectorStoreIndex.from_documents(
[document],
service_context = service_context
)(강의에서는 임베딩 모델로 "BAAI/bge-small-en-v1.5"모델을 로컬에 저장해서 사용함)
VectorStoreIndex.from_documents() → chunking, embedding, indexing을 한 번에!
query_engine = index.as_query_engine()
tru_recorder = TruLlama(
query_engine,
app_id = "Direct Query Engine",
)
for question in eval_questions:
with tru_recorder as recording:
response = query_engine.query(question)
records, feedback = tru.get_records_and_feedback(app_ids=[])Part 2. RAG Triad of metrics
[What is feedback function?]
A feedback function provides a score (from 0 to 1) after reviewing an LLM app's inputs, outputs and intermediate results.
How to evaluate RAG systems
1. Context Relevance : How good is the retrieval?
2. Groundedness
3. Answer Relevance : Is the final response relevant to the query?
from trulens_eval import Tru
tru = Tru()
tru.reset_database()
llm은 completion step에 사용됨
tru.reset_database()
→ will be used to record prompts, responses, intermediate results of llamaindex app as well as results of evaluations
→ initialize feedback functions
from trulens_eval import OpenAI as fOpenAI
provider = fOpenAI()provider → will be used to implement the different feedback functions and evaluations (꼭 LLM을 써야하는 것은 아님!)
Structure of Feedback Functions
from trulens_eval import OpenAI as fOpenAI
from trulens_eval import Feedback
provider = fOpenAI()
f_qa_relevance = (
Feedback(provider.relevance, # feedback function method
name = "Answer Relevance"
)
.on_input()
.on_output()
)
1. Answer Relevance : Is the final response relevant to the query?
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name = "Answer Relevance"
).on_input().on_output()
2. Context Relevance : How good is the retrieval?
from trulens_eval import TruLlama
context_selection = TruLlama.select_source_nodes().node.text
f_qs_relevance = (
Feedback(provider.qs_relevance, name = "Context Relevance")
.on_input()
.on(context_selection) # intermediate results
.aggregate(np.mean)
)
provider.qs_relevance 대신 provider.qs_relevance_with_cot_reasons 를 써도 됨
(TruLlama = TruLens + LlamaIndex)
3. Groundedness
from trelens_eval.feedback import Groundedness
from trulens_eval import Feedback
grounded = Groundedness(groundedness_provider = provider)
f_groundedness = (
Feedback(grounded.grounded_measure_with_cot_reasons, name = "Groundedness")
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
4. Evaluation of RAG Application
from trulens_eval import TruLlama, FeedbackMode
tru_recorder = TruLlama(
sentence_window_engine, # engine to use
app_id = "", # specify id to track versions
feedbacks = [f_qa_relevance, f_qs_relevance, f_groundedness]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
records, feedback = tru.get_records_and_feedback(app_ids=[])
records에 NaN이 뜬 경우 - API failure
tru.get_leaderboard(app_ids=[])
tru.run_dashboard()
Part 3. Sentence-window Retrieval
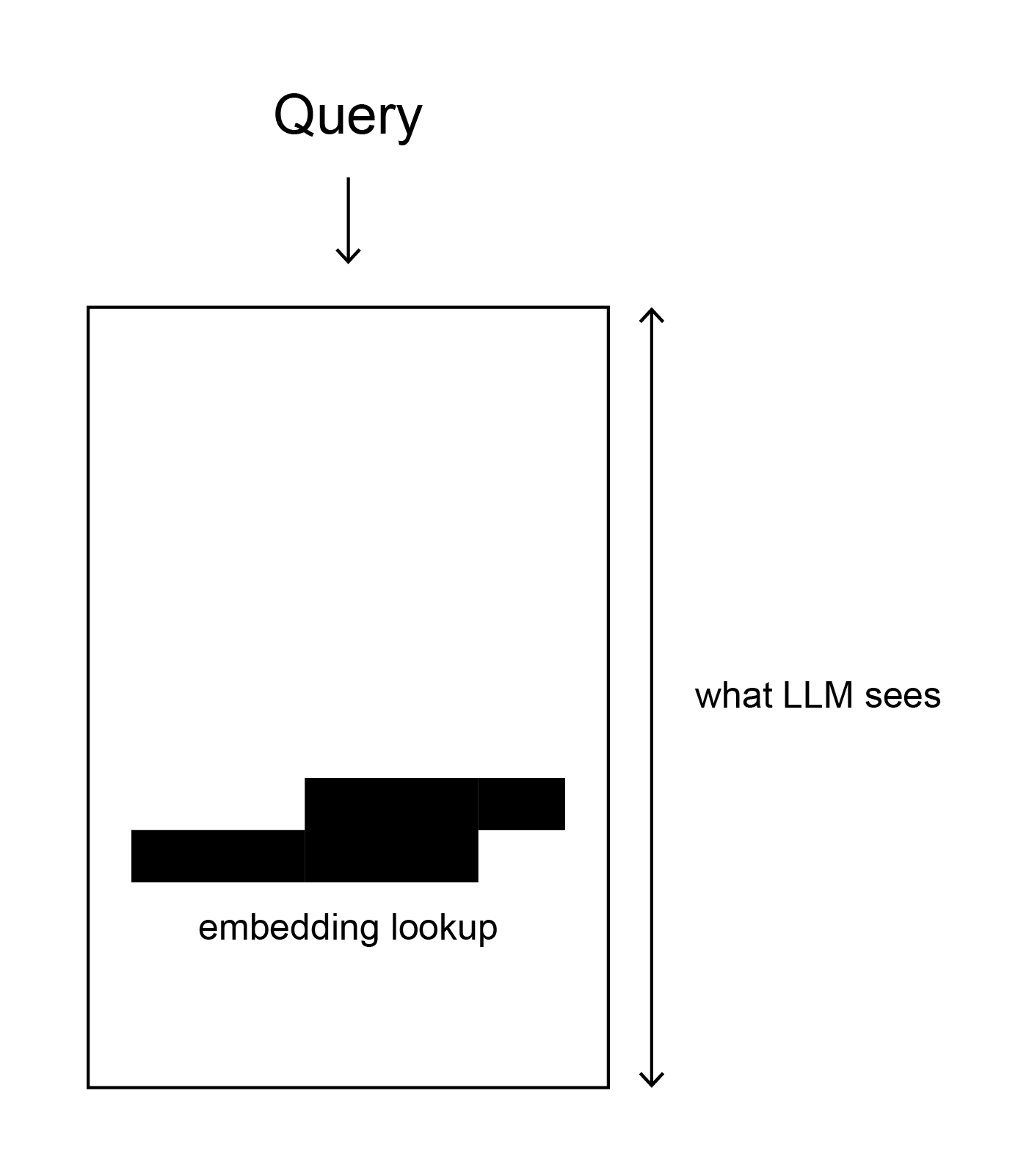
Embedding based retrieval works well with smaller text chunks
but! LLM need more context (i.e. bigger chunks) to synthesize answer
let LLM have more context, yet retrieve more granular information → improve retrieval & synthesis
∴ embed & retrieve small chunks(i.e. more granular chunks) → replace with a larger window of sentences around the original sentences.
from llama_index.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_siz=3,
window_metadata_key = "window",
original_text_metadata_key = "original_text",
)SentenceWindowNodeParser → split a document into individual sentences and then augment each sentence with surrounding context.
Test on window_size
import os
from llama_index.llms import OpenAI
from llama_index import ServiceContext, VectorStoreIndex, StorageContext, load_index_from_storage
sentence_context = ServiceContext.from_defaults(
llm = OpenAI(model="", temperature=0.1),
embed_model = "",
node_parser = node_parser,
)
if not os.path.exists("./sentence_index"):
sentence_index = VectorStoreIndex.from_documents(
[document], service_context = sentence_context
)
sentence_index.storage_context.persist(persist_dir = "./sentence_index")
else:
sentence_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir = "./sentence_index"),
service_context = sentence_context,
)
persist : save permanently
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor, SentenceTransformerRerank
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
rerank = SentenceTransformerRerank(top_n=2, model="BAAI/bge-reranker-base")
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=6,
node_postprocessors=[postproc, rerank],
)
top_n = 2, top_k = 6
Evaluation : Test on sentence_window_size
- Gradually increase the window size from 1.
- Tradeoff between token usage/cost vs. context relevance/groundedness
(note: context relevance와 groundedness 가 같이 커지다가 어느 시점부터 groundedness가 떨어지는 지점이 있음.)
from trulens_eval import Tru
def run_evals(eval_questions, tru_recorder, query_engine):
for question in eval_questions:
with tru_recorder as recording:
response = sentence_window_engine.query(question)
Tru().reset_database()
run_evals(eval_questions, tru_recorder_1, sentence_window_engine_1) # test on window size 1Part 4. Auto-merging retrieval
Define a hierarchy of smaller chunk nodes linked to parent chunk nodes
→ retrieve child nodes and merge into parent node
(If the set of smaller chunks linked to a parent chunk exceeds the threshold, them "merge" smaller chunks into the bigger parent chunk.)
from llama_index.node_parser import HierarchicalNodeParser
node_parser = HierarchicalNodeParser.from_defaults(chunk_sizes = [2048, 512, 128])
# chunk size should be in decreasing order
nodes = node_parser.get_nodes_from_documents([document])
# get all nodes(leaf, intermediate, parent)
auto_merging_context = ServiceContext.from_defaults(
llm = OpenAI(model="", temperature),
embed_model = "",
node_parser = node_parser,
)
if not os.path.exists("./merging_index"):
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
automerging_index = VectorStoreIndex(
leaf_nodes,
storage_context = storage_context,
service_context = auto_merging_context,
)
automerging_index.storage_context.persist(persist_dir = "./merging_index")
else:
automerging_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir = "./merging_index")
service_context = auto_merging_context,
)automerging_index = VectorStoreIndex(leaf_nodes, storage_context = storage_context, service_context = auto_merging_context)
leaf_nodes만 임베딩 모델로 임베딩하고 underlying knowledge는 storage_context, service_context 로 전달함.
set large top_k for leaf nodes. if a majority of child nodes are retrieved, replace with parent nodes
rerank after merging
top 12 -> merge -> top 10 -> rerank -> top 6
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index.retrievers import AutoMergingRetriever
from llama_index.query_engine import RetrieverQueryEngine
automerging_retriever = automerging_index.as_retriever(similarity_top_k = 12)
retriever = AutoMergingRetriever(
automerging_retriever,
automerging_index.storage_context,
verbose = True
)
rerank = SentenceTransformerRerank(top_n = 6, model = "")
automerging_engine = RetrieverQueryEngine.from_args(
automerging_retriever, node_postprocessors = [rerank]
)RetrieverQueryEngine -> retrieval & synthesis
How to evaluate automerging retriever
1. auto_merging_index_0 : 2 levels of nodes, chunk_sizes = [2048, 512]
2. auto_merging_index_1 : 3 layers of hierarchy, chunk_sizes = [2048, 512, 128] -> 처리한 토큰이 절반이 됨
-> context relevance가 살짝 올라감, 아마도 merging이 조금 더 잘 돼서
test with different hierarchical structures (num of levels, children) & chunk sizes
automerging is complementary to sentence-window retrieval
https://learn.deeplearning.ai/accomplishments/7df6e1b6-da1e-4d56-a2ea-806db3113cf4?usp=sharing
next step : data pipeline, retrieval, strategy, LLM prompts