# 01. 프로젝트 소개 : Scientific Knowledge Question Answering
Task : InformationRetrieval
Evaluation Metric : MAP(Mean Average Precision)
프로젝트 기간 : June 13th, 2024 - July 3rd, 2024 (19:00)
Given Dataset :
- documents.jsonl : 4272개의 document data (Ko-H4 데이터 중 MMLU, ARC 데이터 기반으로 생성)
- eval.jsonl : 220개의 자연어 query (멀티턴 대화 20개, 일상대화 20개 포함)
# 02. EDA
1. documents.jsonl
key : "docid", "src", "content"
"src" 의 형태는 출처__분야__train/validation/test 로 구성되어 있음을 알 수 있었다.
예) ko_mmlu__conceptual_physics__test 또는 ko_ai2_arc__ARC_Challenge__validation
doc_df["src_"] = doc_df["src"].apply(lambda x : x.split("__")[0])
doc_df["src_subcat"] = doc_df["src"].apply(lambda x : x.split("__")[1])
'ko_mmlu' : 52.08 %
'ko_ai2_arc' : 47.92 %
주어진 데이터를 기반으로 category를 분석한 결과 21개의 category를 도출하였다.
['nutrition', 'conceptual_physics', 'ARC_Challenge', 'human_sexuality', 'virology', 'human_aging', 'high_school_biology', 'high_school_physics', 'college_biology', 'computer_security', 'anatomy', 'college_physics', 'medical_genetics', 'electrical_engineering', 'college_medicine', 'college_chemistry', 'astronomy', 'college_computer_science', 'global_facts', 'high_school_chemistry', 'high_school_computer_science']
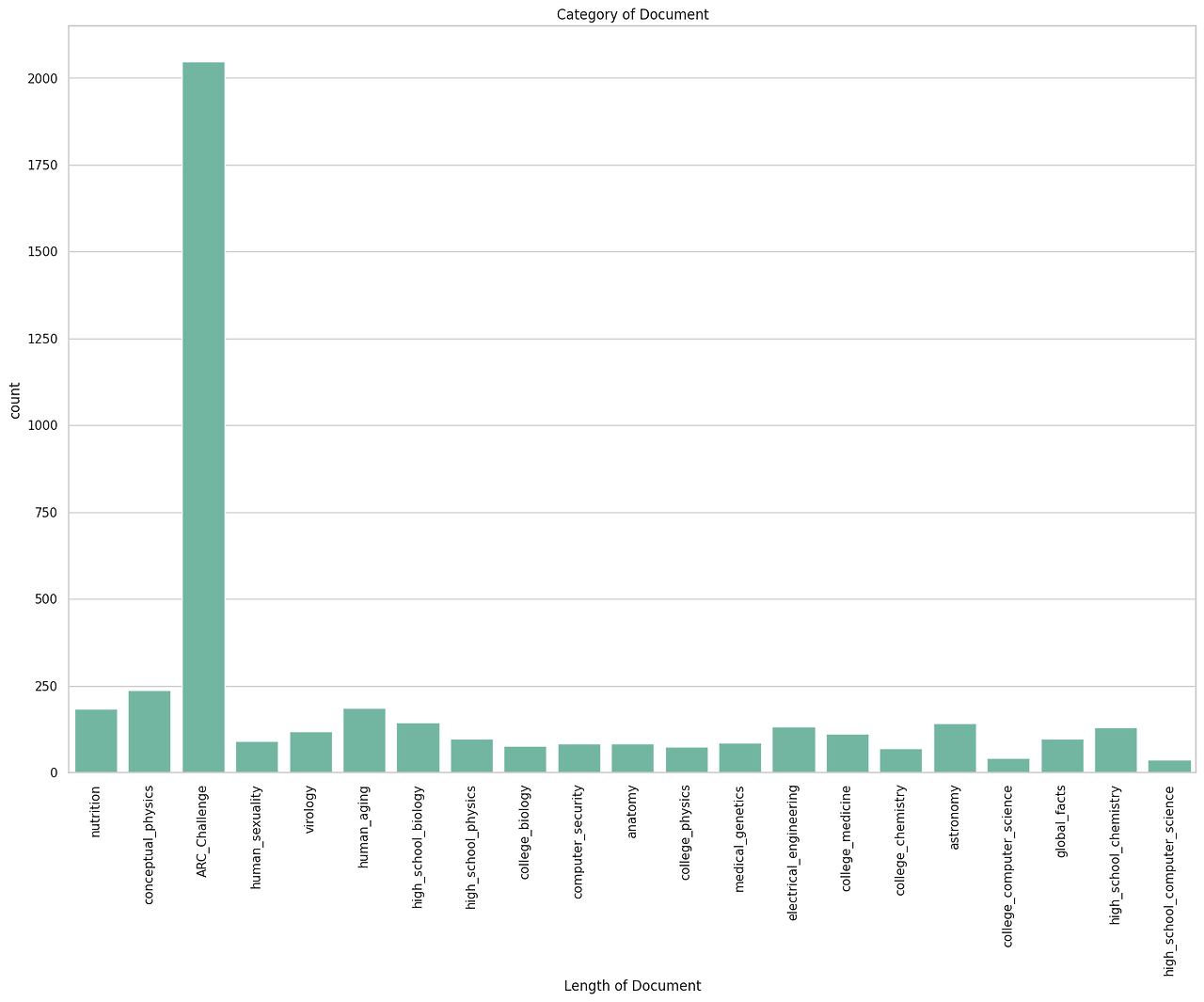
위 그림과 같이 MMLU 데이터는 세부 카테고리가 명시되어 있지만 ARC 데이터는 세부 카테고리가 명시되지 않고 ARC_Challenge로 되어 있음을 알 수 있었다.
for index, row in doc_df.iterrows():
if (row["src_subcat"] == 'conceptual_physics') or (row["src_subcat"] == 'high_school_physics') or (row["src_subcat"] == 'college_physics'):
doc_df.at[index, 'src_subcat'] = "physics"
elif (row["src_subcat"] == 'high_school_biology') or (row["src_subcat"] == 'college_biology'):
doc_df.at[index, 'src_subcat'] = "biology"
elif (row["src_subcat"] == 'college_computer_science') or (row["src_subcat"] == 'high_school_computer_science'):
doc_df.at[index, 'src_subcat'] = 'computer_science'
elif (row["src_subcat"] == 'college_chemistry') or (row["src_subcat"] == 'high_school_chemistry'):
doc_df.at[index, 'src_subcat'] = 'chemistry'
conceptual_physics, high_school_physics, college_physics 등을 한개의 분야(physics)로 통합할 경우 'ARC_Challenge' 외 15개 분야가 있음을 알 수 있었다.
['nutrition', 'physics', 'human_sexuality', 'virology', 'human_aging', 'biology', 'computer_security', 'anatomy', 'medical_genetics', 'electrical_engineering', 'college_medicine', 'chemistry', 'astronomy', 'computer_science', 'global_facts']

2. eval.jsonl
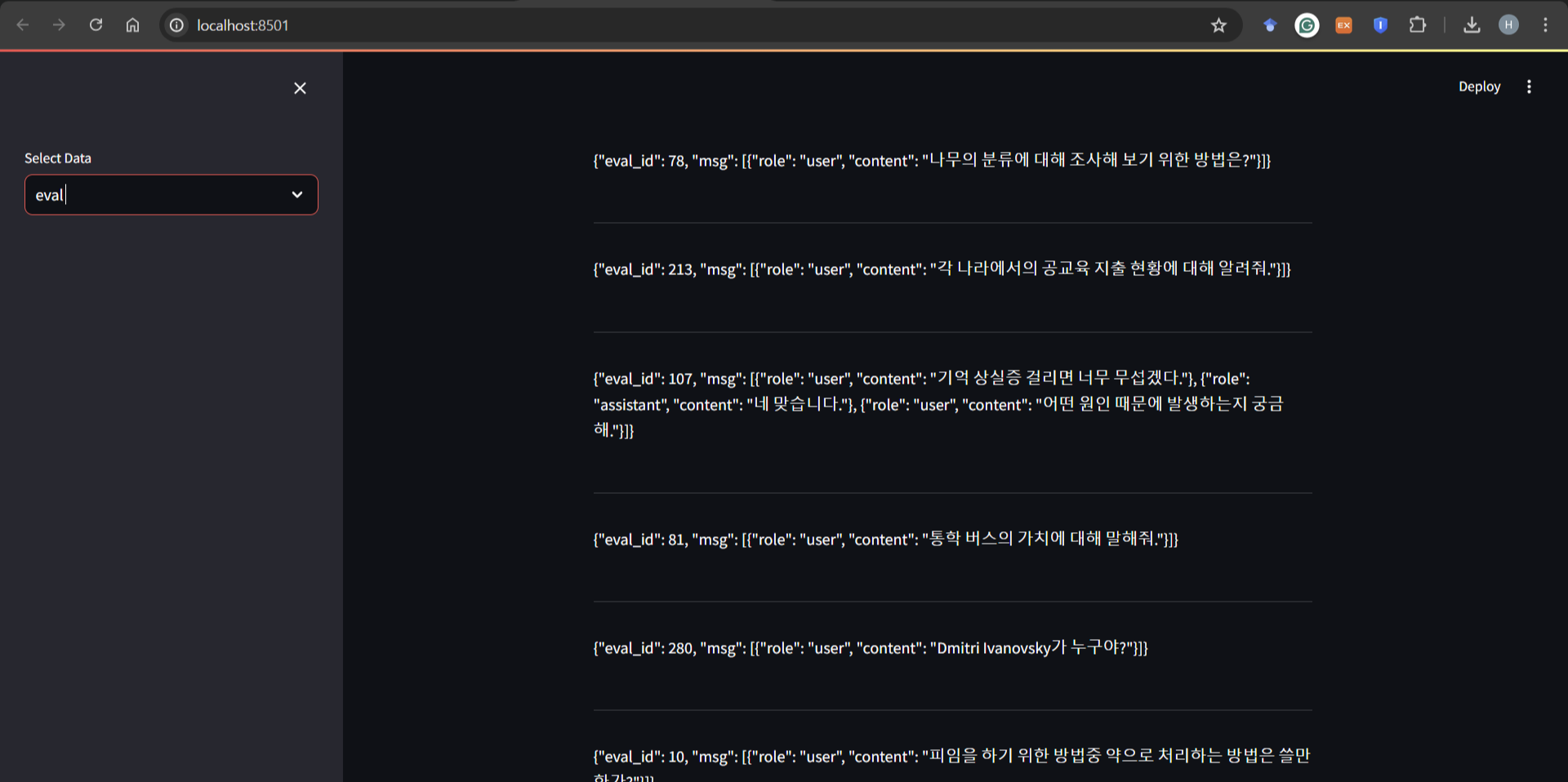
streamlit을 활용하여 220개의 eval 데이터를 읽어봄. 추후 query 추출 및 retrieval에서 잘 작동하고 있는지 여부를 확인하기 위해 20개의 멀티턴 대화와 20개의 일상대화 인덱스를 확인하였다.
chitchat_eval_ids = [276, 261, 283, 32, 94, 90, 220, 245, 229, 247, 67, 57, 2, 227, 301, 222, 83, 64, 103, 218]
multiturn_eval_ids = [107, 42, 43, 97, 243, 66, 98, 295, 290, 68, 86, 89, 306, 39, 33, 249, 54, 3, 44, 278]

# 03. Generating query from documents
본 대회는 이전 대회들과 달리 데이터가 train, validation, test의 형식으로 주어지지 않았다.
또한 220개 쿼리 중 과학(사회과학 분야 포함) 상식에 관한 쿼리는 200개 뿐이고 top3까지만으로 채점하기 때문에 evaluation에 활용되는 데이터는 600개 이하이고, 베이스라인만 실행할 경우 최소 3600 여개의 다큐먼트가 활용되지 못 한다. 따라서 주어진 데이터를 활용할 수 있는 방법이 두가지가 있는데, ① 쿼리-다큐먼트 페어를 만들어서 colBERT 학습에 사용하는 것과, ② validation set을 구성해서 (이 방법 또한 답지로써 쿼리와 다큐먼트 페어가 필요하다.) 프롬프트 혹은 function 정의에 대해 자체 검수 후 전체 파이프라인을 돌리는 방법이 있다.
어떤 쪽을 선택하든 간에 다큐먼트로부터 쿼리를 생성하는 스텝이 필요하였다. 생성된 쿼리는 다큐먼트를 분류하는 용도로도 사용이 가능하였다.
##개선점
: Query Generation은 다큐먼트에 대한 EDA가 완료 되기 전에 수행이 되어 query.jsonl에서 few shot을 임의로 뽑아서 넣어주었다. 시간 여유가 있었다면 few shot을 랜덤 샘플하고 퀄리티 컨트롤에 조금 더 신경을 썼으면 좋았을 것이다.
퀄리티 컨트롤과 함께 프롬프트에 대한 검증도 같이 진행하였으면 더 좋았을 것이다.


# 04. Making Validation Data
대회 시작 전에 마침 다양한 영상으로 NLP 분야 현업자들의 강의를 봤던 참이라 NLP 분야 현업에서는 validation data의 설정에 대한 고민을 많이 하고 있는 것으로 알고 있다.
게다가 초반에는 제출 횟수가 5회였고, 대회를 기획한 강사님과 멘토님들이 왜 valid data가 없는지에 대해 고민해보라고 하였다.
이를 현업에서 하듯이 validation data를 직접 구성해보면서 validation의 비율과 퀄리티 컨트롤에 대해 직접 고민해보라는 의도로 이해하였다. 또한 제출 횟수 제한으로 인하여 모든 경우의 수를 제출해보기는 어려우므로 validation data를 만들어 로컬에서 확인한 뒤 제출해보는 것이 의미가 있을 것이라고 판단하였다.
(원본 작업 노션 링크 : https://www.notion.so/hyj89han/3b07b0d593b949b688d2da32237360ef)
Validation Data를 만들기 위해서 다음과 같은 단계로 접근하였다.
- Step1. 주어진 다큐먼트로부터 쿼리를 생성
- 추가 단계 : ARC_Challenge와 같이 다큐먼트의 주제가 세분화 되지
- Step2. 다큐먼트 EDA를 참고하여 쿼리 레이블링 (using LLM)
- Step3. 쿼리의 레이블을 참고하여 비율을 맞춰 답안지 생성
# Step1. ARC_Challenge 세분화
앞선 작업에서 documents.jsonl로부터 생성해둔 쿼리가 있었기 때문에 비용을 감안하여 document에 대한 classification은 generated query를 넣어서 진행하였다.

##개선점
: Generated query에 대한 퀄리티 컨트롤이 선행되었으면 좋았을 것 같으며, 앞서 EDA 단계에서 진행한 것과 같이 documents의 수가 적은 분야에 대해 검토하고 통합이 필요한 카테고리는 통합한 뒤 진행하였으면 좋았을 것이다.
# Step2. Query Labeling (using LLM)
참고사항 : 모든 작업을 수행하기 전, 기본적으로 LLM (특히 GPT)이 한국어 성능이 좋지 않기 때문에, 만약을 위해 한국어 다큐먼트와 쿼리에 대한 번역본을 만들어 두었다.
Query의 경우에는 영어 번역본을 바탕으로 classification을 수행하였다.
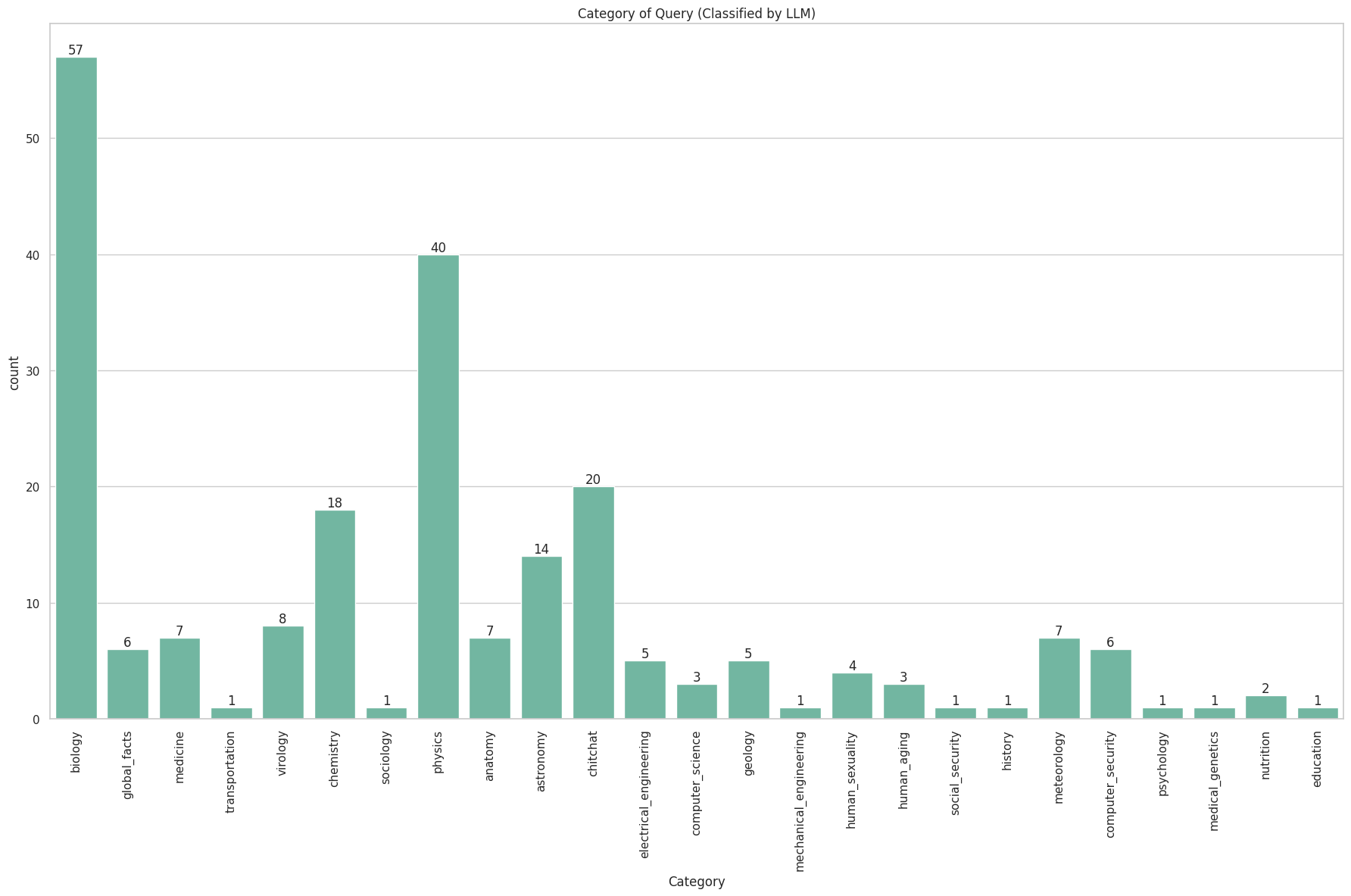
# Step3. 쿼리의 레이블과 비율을 맞춰 답안지 생성
시간 관계상 쿼리 중 가장 큰 비율을 차지하는 biology, physics와 이 시점에서 가장 답지를 잘 생성 못하고 있었던 컴퓨터 관련 분야( computer_science, computer_security)에 대해서만 valid data를 구성하였다.
다큐먼트로부터 query를 생성했으므로 generated query에 대한 top1은 원문 다큐먼트로 구성하였다.
##개선점
: valid data 구성을 완료하지 못 한점이 아쉽고, 시간관계상 valid data 구성에 대한 퀄리티 컨트롤 및 직접 로컬에서 실험 수행과 함께 valid data 기준으로 평가하는 작업까지는 진행하지 못 하였다.
또한 top1 외에도 generated query 혹은 document에 대해 similarity를 기반으로 top2, top3까지 추출하고 싶었으나 시간관계상 이 단계까지는 진행하지 못 하였다.
# 05. Trial&error with Training ColBERT
(논문 참고 자료에 대한 정리 : https://www.notion.so/hyj89han/ColBERT-Efficient-and-Effective-Passage-Search-via-Contextualized-Late-Interaction-over-BERT-ad08413fb1db4f8b8e5794aa0292c9c1)
4200여개의 다큐먼트가 주어졌으나 200여개의 과학상식 질문에 대하여 top3가 모두 다르다는 가정하에도 600개 데이터 밖에 활용되지 않는 셈이다. 즉, 최소 3600여개의 데이터가 활용되지 않게 되는데, 주어진 task에 맞춰 성능을 높이려면 retrieve에 쓰이는 모델에 대한 학습이 필요할 것으로 생각하였다. 시간관계상 규모가 큰 언어모델에 대해 학습을 시키기는 어려울 것으로 판단, 팀 내에서 colbert vector를 사용해 성능을 끌어올렸기 때문에 colbert를 주어진 데이터에 맞게 학습을 시켜보고 싶었다.

그러나 콜버트를 학습시키려면 <query, qositive document, negative document>로 구성된 triple data로 학습 데이터를 만들어야 하는데다가 콜버트 자체를 학습시키는 방법에 대한 자료가 부족하여 triple data 구성까지 밖에 진행하지 못하였다. Triple data를 구성하는 단계에서도 고민이 많았는데, ① negative document를 어떻게 정의할 것인지에 대한 고민과 ② retrieve model이 실제로 헷갈려하는 document를 hard negative로 설정하기 위해서는 어떻게 선별해야할 것인가에 대한 고민이 있었다.
##개선점
: 추후 RAG 공부를 추가 진행하면서 콜버트 학습을 더 진행시켜보고 싶다.
노션링크 :
https://www.notion.so/hyj89han/IR-34518a714bfb4f40beed1c5855cad7c9