Upstage AI Lab 2기
2024년 2월 29일 (목) Day_055
온라인강의
업스테이지 AI
어제자 못 들은 수업
Deep Learning 모델 학습법 모델 학습법 I : 다층 퍼셉트론 0:51: 48
승현님 추천
https://www.youtube.com/@hanyoseob/videos
Deep Learning 모델 학습법 모델 학습법 I : 다층 퍼셉트론
다층 퍼셉트론 : 뉴럴넷의 시초
뉴럴넷 개요
사람의 인지, 기계의 인지
기계의 인지
- 전통적 방식 :
구별 짓는 특징을 사람이 결정 handcraft feature
예) 어떤 특징을 봐야 사람이 있는지 알 수 있을까.
그 특징을 뽑으면 그게 논문이 되었다.
- 뉴럴넷 방식 :
학습 데이터 - 이미지, 정답
자동으로 특징들과 의사 결정 룰을 찾아낸다.
인공 뉴런의 등장
activation function - 말하자면 다음 뉴런으로 넘겨줄지 말지 결정되는 포인트 (종류 예시) 퍼셉트론, 시그모이드 뉴런 등)
퍼셉트론
인공뉴런 시초
1957년 코넬 항공 연구소에서 고안
Feed-forward 네트워크
현재 층의 뉴런은 다른 층의 여러개의 뉴런과 연결되어있음.
이전 뉴런들로부터 넘어오는 신호들에 대하여 가중치를 주어 현재 층의 뉴런에서 합침
아웃풋 신호를 넘길지 말지(activation function), 그것을 결정하기 위한 threshold
퍼셉트론은 임계치보다 크면 on, 작으면 off

퍼셉트론으로만 구성된 뉴럴 넷은 input/output binary
모델의 파라미터에 따라 모델이 바뀐다 = 의사결정이 바뀐다

편향 (bias)
bias를 키워서 뉴런을 활성화시킬 확률이 높일 수 있음
퍼셉트론과 선형 분리
퍼셉트론이 각광받았던 이유
: 전기회로 관점에서
어떠한 연산이든 NANDgate의 조합으로 표현이 가능하다.
즉, 어떠한 모델이든 NANDgate의 조합으로 표현이 가능하다.
어떤 연산이든 그 근간은 NANDgate 하나로 표현이 가능하다.
universal approximation theorem
퍼셉트론이 NANDgate를 묘사를 할 수 있으면
여러 퍼셉트론으로 구성된 뉴럴넷은 어떠한 연산이든 구현할 수 있다는 뜻이 됨.
퍼셉트론 하나로 NANDgate 표현 가능

but 퍼셉트론으로는 xor 논리값은 표현이 안 됨 - 하나의 직선으로 영역을 구분할 수 없기 때문에
but 선 두개로 표현 가능
즉, 퍼셉트론 두 개의 조합으로 표현 가능하다.
퍼셉트론 두 개 이상 사용 -> non linear seperability
결론 : 퍼셉트론 하나가 NANDgate
그러면 퍼셉트론을 여러 개 조합하면 어떠한 연산이든 표현 가능한 것 아닌가?
-> 다층 퍼셉트론
MLP(Multi-Layer Perceptron)
지금은 이 개별 인공뉴런이 페셉트론이 아니어도 MLP라고 부름
MLP(Multi-Layer Perceptron) 와 Fully-Connected Layers (FCs)는 동의어로 사용됨
(퍼셉트론은 요새 실제 모델링에서 사용안함)
앞 뒤로 모든 뉴런과 연결되어 있음
다층 퍼셉트론에서 activation function이 임계치보다 크냐 작냐가 아닐 수도 있음
(활성화 함수에 대한 인풋은 z로 표현됨. 통일된 표현방법임)
활성화 함수가 필요한 이유
결과적인 계산이 선형분리냐 비선형 분리냐에 따라 활성화 함수가 필요한 이유가 설명됨.
활성화 함수가 없는 다층 퍼셉트론 모형은 결과적으로 단순한 선형식임
but 비선형 구분이 나은 경우가 더 많음.

perceptron은 step function으로
시그모이드 - 미분가능하게 만들어짐
역전파 기법 : 미분이 가능해야 간단한 연산으로 모델을 학습 가능하다.

MLP 예제 : MNIST
이미지 크기 = input node 개수
(픽셀 값이 개별 노드로 들어)

MLP online demo 꼭 해보기
모델 학습법 2 : 경사하강법
Gradient Descent
경사하강법 Gradient Descent
모든 a,b에 대해 손실함수를 계산하는 것은 불가능
최소한의 a,b에서만 손실함수를 계산 하는 것이 목표
어느 방향으로 가면 손실함수가 줄어들 것이
모델의 파라미터와 손실함수 값의 관계
어떤 점에서의 함수의 기울기를 알면 어느 방향으로 점을 움직여야 함수값이 증가 또는 감소하는지 알 수 있음.
미분값의 반대방향으로 가면 손실함수가 감소한다.
경사하강법 Gradient Descent 의 한계
1. local minimum에 빠지는 경우
2. plateau에서 멈추는 경우
해결방법
1. 파라미터 초기화를 잘한다.
(여러 초기화 기법이 있음 - chapter3에서 배울 예정, pretraining이라고도 함.
아예 초기화 하는 방법도 많음)
2. 모델 구조를 바꿔서 그래프 모양을 바꾼다.
모델 구조를 바꾸면 손실함수 그래프의 모양이 바뀐다.
3. 러닝스텝을 바꾼다.

learning rate를 잘못 잡으면 아예 발산할 수도 있음.
but 모든 샘플에 대해 손실함수를 다 더해야 해서 연산량이 문제가 됨
그렇다면!
전체 샘플에 대한 손실함수의 평균을 구하나,
일부 샘플에 대한 손실함수의 평균을 구하나 비슷하지 않을까?
하는 발상으로 나온 것이
확률적경사하강법 Stochastic Gradient Descent
확률적경사하강법 Stochastic Gradient Descent
매번 다양하게 샘플을 고른다는 의미에서 Stochastic
경사하강법에서는 1step 이 1epoch 였음
1 epoch : 전체 학습데이터셋 한바퀴 모두 학습
M개를 m개 사이즈의 batch로 쪼갬.
m개 batch에 대해 한바퀴 돌아서 파라미터 업데이
1 step : m개의 batch마다 평균 loss 구해서 파라미터를 한번 업데이트
M/m step = 1 epoch
m=1이면 온라인학습(online/incremental learning)이라고도 부름
∴ 손실함수의 그래디언트를 구하기 위해서는 손실함수가 미분 가능해야하고, 그래서 activation function을 시그모이드를 씀.
SGD의 장점 : 샘플링을 통해 모델구조를 간접적으로 바꾸는 효과가 있음.
역전파 (기초)
= Backpropagation
현대 딥러닝의 백프로가 역전파 방식을 도입해서 계산을 효율화
역전파는 최적화 알고리즘 계산에 있어 효율서을 확보
SGD로는 학습 데이터의 수를 줄였을 뿐
여전히 모든 파라미터에 대해 계산해야하는 것은 변함 없음
역전파를 도입하면 왜 편미분에 대해 간단해지는지 감을 잡기위해
계산 그래프
Computational Graph
- 이점 :
편미분이라는 큰 문제를 잘게 쪼갤 수 있음(단순화)
각 변수에 대한 미분을 효율화할 수 있음
각각의 편미분을 적용해서 합쳐서 최종 결과를 도출하겠다.
계산하는 과정을 엣지와 노드를 도입해서 step by step으로 접근하겠다.
Computational Graph 에 chain rule을 같이 적용!!
chain rule을 적용하면 전체 손실함수에 대해 미분하는 것 보다 간단한 미분으로 표현/계산이 가능함.

이미 p4에 대한 L을 미분한 값은 파라미터 업데이트 하면서 구했음

feed forward 해서 L을 구하고 아웃풋에 가장 가까운 레이어부터 미분값을 구함 -> backpropagation
인접한 파라미터 사이에서의 미분값을 곱해서 뒤로 넘겨줌
역전파 (심화)
2.1. 손실 함수의 기본 가정
2.2. 역전파의 기본 방정식
2.3. 역전파 알고리즘
역전파 알고리즘이 동작 가능한 손실함수의 기본 가정이 있음
- 모든 손실 함수에 대해 역전파 알고리즘을 사용 가능한 것은 아님.
역전파 알고리즘을 사용할 수 있기 위해서는 충족되어야 하는 손실함수의 조건이 있음.
가정 1.
학습 데이터 샘플에 대한 신경망의 총 손실은,
각 데이터 샘플에 대한 손실의 합과 같다.
가정 2.
각 학습 데이터 샘플에 대한 손실은 aL(최종 출력)에 대한 함수이다.
l-번째 레이어의 j번째 뉴런에 대한 에러 δjl를 다음과 같이 정의
l-번째 레이어의 j번째 뉴런에서의 z값 zjl
zjl에 대해 손실함수를 편미분한 값을 에러 δjl라고 정의.

역전파의 기본 방정식 (4개)
4가지 방정식으로 구성되어 있음
기본 방정식 1.
아웃풋 레이어에 대한 방정식
아웃풋 레이어에서 미분이 어떻게 되느냐
이 때, 계산을 유도할 때, 에러를 기준으로 표현

여기서 주의할 부분
데이터 샘플 전체에 대한 합을 코스트라고 정의한 것이 아니라
한 샘플에 대한 코스트를 계산한 것.
최종 레이어의 노드별 출력값에 대해 합한것.

아웃풋 레이어에서는 z
---( σ )---> a 노드간 연결고리가 없기 때문에 결국 Σ는 의미 없음.
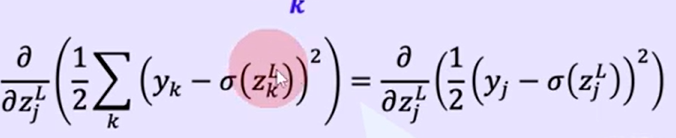
노드별로 에러를 구해서 매트릭스 형태로 합치겠다.
(Hadamard Product로 표현)
기본 방정식 2.
l 번째 레이어와 l+1번째 레이어 사이의 관계

기본 방정식 3. & 기본 방정식 4.
z에 대해 구했으니
b, w에 대한 편미분
기본 방정식 3. bias에 대한 편미분
덧셈 노드는 에러시그널이 그대로 넘어간다.

기본 방정식 4로부터 얻을 수 있는 insight 1 & 2

wjk l 의 변화량에 따른 C의 변화량이 작다는 것은 무슨 의미인가?
(-> 학습이 진행돼도 weight의 변화가 거의 없다)
1. a가 작은 경우 (a 가 0에 가까운 경우) - 편미분 값이 0에 가깝다.
즉, low activation neuron 과 연결된 weight는 거의 안 변한다.
2. δ가 작은 경우 -> σ'이 0에 가깝다(기본 방정식2) -> 시그모이드 함수에서 양 극단 -> 학습이 느려
기본 방정식 요약

모델 파라미터 업데이트 w. GD

멘토님 추천영상
https://www.youtube.com/watch?v=N6CbPBRR_pw
https://www.youtube.com/watch?v=glLSmqAG7NA
https://opentutorials.org/module/4916/28942
참고자료
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day055] Deep Learning - 성능고도화 (0) | 2024.03.04 |
|---|---|
| Upstage AI Lab 2기 [Day055] Deep Learning - 손실 함수 (0) | 2024.03.03 |
| Upstage AI Lab 2기 [Day043] ML 프로젝트 (day1-2) (2) 업무분담 (0) | 2024.02.13 |
| Upstage AI Lab 2기 [Day043] ML 프로젝트 (day1) (0) | 2024.02.13 |
| Upstage AI Lab 2기 [Day042] 자료구조 및 알고리즘 (3) (0) | 2024.02.09 |


