Upstage AI Lab 2기
2024년 3월 5일 (화) Day_057
온라인강의
업스테이지 AI
나머지 공부
CH. 4-1. CNN (Convolutional Neural Network)
MLP의 한계점 : flatten 하면서 이미지 데이터의 형상 정보가 사라짐
상대적 위치에 대한 정보가 사라지고, 인접 픽셀간 유사성에 대한 정보가 사라짐
앞단은 convolution을 사용하고, 어느 정도 추상적으로 특징이 잘 뽑혔다고 판단 되면 그 뒤부터는 일렬로 정렬해서 사용함.
convolution 연산
Filter/Kernel - Kernel을 구성하는 숫자가 모델이 학습해야할 파라미터
입력 데이터보다 출력 데이터의 크기가 작아짐
입력데이터 x 커널(element-wise product) -> feature map
hyperparam : kernel size, stride, padding,
이미지는 RGB -> 3 channels!!!
channel수는 정해져 있고, 커널의 채널도 인풋의 채널과 맞춰줌
(커널이 3차원이 됨)
but output channel은 1

3차원 필터를 FN개 사용하고 싶다면?
입력 (C, H, W) ⓧ 필터(FN, C, FH, FW) -> 출력(FN, OH, OW)
pooling - max pooling / average pooling
풀링은 학습의 대상이 아니다!!
- 효율적으로 데이터 크기를 줄일 수 있음
- 노이즈에 대해 robust함
꼭 해보기!
https://cs.stanford.edu/people/karpathy/convnetjs/demo/mnist.html
https://transcranial.github.io/keras-js/#/mnist-cnn
https://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html
CH. 4-2. RNN (Recurrent Neural Network)
자연어처리에 많이 사용됨.
특히 transformer model이 rnn에서 발전됨
입력데이터의 크기가 고정되지 않았을 경우 CNN을 쓰기가 어려움
이미지데이터 처리시에는 resize처리를 해줌 (학습시 이미지 크기를 기준으로)
but 텍스트는 이렇게 처리가 안됨
텍스트 -> sequential data

순차적으로 인풋을 넣어줄 때, 모델 파라미터에 이전 데이터의 상태에 대한 정보가 저장되어 있음
상태 정보를 저장해둔다는 의미
핵심 : 이전 시점의 정보를 현재 인풋과 같이 처리할 수 있어야 함
기억하는 역할 : 은닉층 (인풋이 추가됨에 따라 업데이트 됨)
one-to-many : 예) image captioning
many-to-one : 예) sentiment analysis
many-to-many : 예) machine translation, video scene classification
입력이든 출력이든 many가 들어오게 됨, 이것을 처리할 수 있는 구조여야 함.
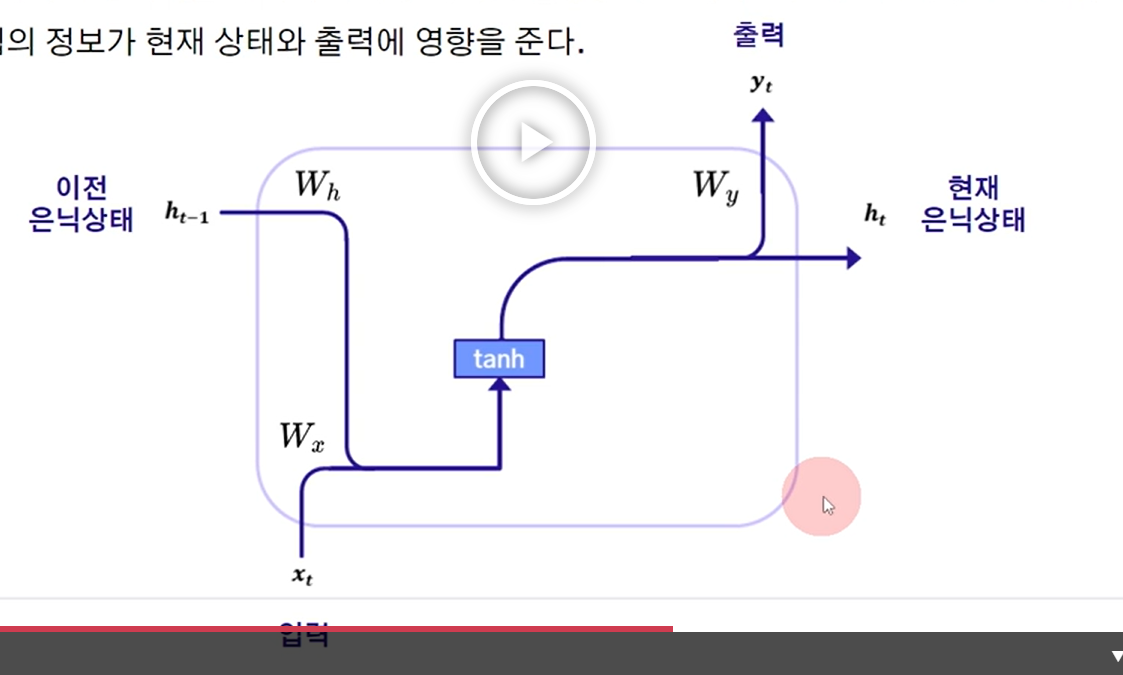
RNN에서는 arc tangent가 좋더라!라고 제안


critical한 문제점!!!
one-to-one에서도 backprop시 vanishing gradient problem이 있었는데,
rnn에서는 시간에 대해서도 누적되는 효과가 있어서 출력층과 먼 정보에 대한 파라미터 업데이트가 잘 안됨
-> Long-term dependency
Long-term dependency를 해결하기 위해
1. LSTM (Long Short-Term Memory)
2. GRU (Gated Recurrent Unit)
1. LSTM (Long Short-Term Memory)
3가지 gate : Forget gate, Input Gate, Output Gate

2. GRU (Gated Recurrent Unit)
LSTM을 단순화
2가지 gate : reset gate, update gate
update gate - LSTM의 Forget gate, Input Gate 합친것과 유사함

추가로 읽을 거리
https://karpathy.github.io/2015/05/21/rnn-effectiveness/
- rnn이 시계열 데이터를 다루긴 하지만, 이미지를 시계열 데이터처럼 바꿔서 이미지 인식에도 사용 가능함
https://en.wikipedia.org/wiki/Recurrent_neural_network
CH. 4-3. From AlexNet to ChatGPT
LeNet-5 (1998) - CNN구조를 처음 제안
AlexNet (2012) - 딥러닝의 시초
ImageNet dataset - ILSVRC 2010-2017
AlexNet을 기점으로 top 1 accuracy 급상승
AlexNet 이전은 전통적 기법으로 봄, AlexNet 이후 딥러닝 기반 모델이라고 봄


인식 TASK
VGG (2014)
3x3 필터로만 구성!
이전 : 초반에는 필터 크기가 큰게 좋다고 알려져 있었는데
3x3 필터를 여러겹 쌓는 방식으로
더 적은 파라미터로 더 큰 필터를 쓰는 효과를 냄
GoogLeNet(2015)
inception module을 제안
1x1, 3x3, 5x5 필터를 쓴 결과를 합

ResNet(2015)
핵심 아이디어는 대표적인 모델들에서 지금도 사용되고 있음
Transformer에도 적용되어 있음
기대하는 바 : 레이어가 클 수록 training/test 에러가 낮기를 기대함
-> degradation problem
이것은, 즉, 모델의 구조적으로 근원적인 문제가 있다!!

기존 방식에 highway를 추가함 - F(x) + x를 학습해야하는게 아니라 bypass를 뚫어줌으로써 F(x)에 대해서만 학습하면 됨
residual만 익히면 된다
residual connection
-> 152개 레이어
but 과적합은 일어나지 않고, 사람보다 정확도가 높아짐

생성 TASK
GAN(Generative Adversarial Networks, 2014)
새로운 방식으로 모델을 학습시킴
학습시 Generator와 Discriminator를 같이 학습시킴
(서비스 단에서는 Generator 를 서비스 함)

비유 : G는 위조지폐(Fake)를 생성, D는 fake와 real을 감별
D의 성능이 올라가면, D를 속이기 위해서 G의 성능도 향상 됨
목표 : D가 구별하기 어려운 real같은 fake를 만드는 것
text domain
Sequence-to-Sequence (Seq2Seq, 2014)
시퀀스 투 시퀀스 형태로 전체 구조를 엮어놓은 모델구조를 제안함
기본 LSTM 구조에 순차적으로 텍스트 인풋
중간에 하나의 context vector로 압축해서 출력의 첫 단에 같이 넣어줌
(인코딩 - 컨텍스트 벡터 - 디코딩) 구조 -> transformer 구조와 유사함
기존의 통계적 번역보다 성능이 좋아짐
Transformer (2017)
self-attention 매커니즘
attention : 연관성이 있는 것들만 보겠다.
- 입출력간 관계 뿐만 아니라, 입력 문장 내부에서도 attention이 학습될 수 있도록 모델 구조를 짬
입력 내 연관성, 출력 내 연관성, 입출력 간 연관성
그 결과 텍스트 데이터에 대해 성능이 올라감
(transformer도 기본적으로 seq2seq 구조)
Transformer 나오면서 텍스트 도메인의 성장이 가속화됨
LLM
BERT (Bidirectional Encoder Representations from Transformers, 2018)
transformer 모델을 많이 키우고,
텍스트 도메인도 pre-training, fine-tuning이 잘 작동하는 것을 보여준 첫 모델
BERT의 pre-training 방식 : 빈 단어 맞추기 (Masked Language Model)
masking 된 것을 예측하는 방식으로 task setting해서 pretrain함
-> self-supervised
여러 입출력 관계를 만들어 낼 수 있음
GPT (Generative Pre-trained Transformer, 2018)
GPT pre-training 방식 : 다음 단어를 예측하는 방식으로 pretrain
transformer 구조를 쓰기는 하는데
decoder 모델 구조만 가져와서 모델을 키워서 setting
그렇게 해서 BERT처럼 pre-training, fine-tuning 하니까 잘 되더라
여기서 더 사이즈를 키워나감
더 공부할 것
https://jalammar.github.io/how-gpt3-works-visualizations-animations/
Computer Vision domain
EfficientNet (2019)
같은 수의 파라미터를 갖는 다른 모델들 보다 항상 accuracy가 높음, 획기적 성능 발전
좌상단 - 가능하면 적은 파라미터로 가능하면 높은 accuracy
CNN 구조에서 변화가능한 요소 3가지 : 레이어 수 / feature map의 resolution(channel 수를 키워서) / 채널
EfficientNet 는 세가지 모두를 잘 조절해서 학습이 가능하도록 만듦
그 결과 더 효율적인 파라미터로 성능 향상
ViT (Vision Transformer, 2020)
transformer가 text 에서 성능이 좋다보니 vision domain에도 transformer를 가져오기로 함
이미지 데이터를 시계열 순으로 바꿔줘야 함
pre-train -> 다음 단어 예측과 유사함
이미지 데이터에서 다음 단어 예측 task와 유사한 건 뭘까?
이미지를 패치로 쪼개서, 다음 패치를 예측하는 방식으로
이미지를 패치로 쪼개서 트랜스포머 구조에 맞춰서 넣어줌 -> 그리고 CNN보다 성능이 잘 나옴
ChatGPT (2022)
GPT3 에서 이미 in-context learning으로 충격
GPT3 to GPT3.5 코딩 데이터를 넣어줌
why? 코드 = 논리정연한 표현 방법
코드 데이터를 넣어줬더니 지식 성능이 올라감
첨언.
OpenLLM 진영과 closedLLM 진영이 있었고 그 기술격차가 컸는데, LLaMA 이후 그 격차가 많이 줄어들었음.
Hugging Face : Open LLM Leaderboard
추가로 읽을 거리
- 공부할 때 좋음
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day057] PyTorch 실습 - Tensor Manipulation (1) | 2024.03.05 |
|---|---|
| Upstage AI Lab 2기 [Day057] PyTorch (0) | 2024.03.05 |
| Upstage AI Lab 2기 [Day055] Deep Learning - 성능고도화 (0) | 2024.03.04 |
| Upstage AI Lab 2기 [Day055] Deep Learning - 손실 함수 (0) | 2024.03.03 |
| Upstage AI Lab 2기 [Day055] Deep Learning (1) | 2024.02.29 |



