기초 통계량을 바탕으로 두가지 방향의 가설설정이 가능함
1. 당뇨병 예측에 필요한 변수는 [ ], [ ], [ ] 일 것이다.
2. 당뇨병 설문을 위해 [ ], [ ], [ ] 변수는 [ ] 변수만으로 충분히 설명된다.
단일 변수 검증
dependent : 'Diabetes_binary'
chi-squared(categorical independent variable) :
| 'Diabetes_binary'와의 correlation | chi-squared test p-value |
||
| binary | 'HighBP' | 0.254318 | 0.0 |
| 'HighChol' | 0.194944 | 0.0 | |
| 'CholCheck' | 0.072523 | 0.0 | |
| 'Smoker' | 0.045504 | 0.0 | |
| 'Stroke' | 0.099193 | 0.0 | |
| 'HeartDiseaseorAttack' | 0.168213 | 0.0 | |
| 'PhysActivity' | -0.100404 | 0.0 | |
| 'Fruits' | -0.024805 | 0.0 | |
| 'Veggies' | -0.041734 | 0.0 | |
| 'HvyAlcoholConsump' | -0.065950 | 0.0 | |
| 'AnyHealthcare' | 0.025331 | 0.0 | |
| 'NoDocbcCost' | 0.020048 | 0.0 | |
| 'DiffWalk' | 0.205302 | 0.0 | |
| 'Sex' | 0.032724 | 0.0 | |
| categorical | 'GenHlth' | 0.276940 | 0.0 |
| 'Age' | 0.177263 | 0.0 | |
| 'Education' | -0.102686 | 0.0 | |
| 'Income' | -0.140659 | 0.0 |
개별변수와 당뇨병 환자를 종속변수로 설정한 logistic regression()
'BMI', 'MentHlth', 'PhysHlth', 'GenHlth', 'Age', 'Education', 'Income'
생각하고 있는 가설들
- 'CholCheck'/ 'AnyHealthcare' / 'NoDocbcCost' 변수는 영향이 없을 것이다.
- 'Stroke'/ 'HeartDiseaseorAttack' 변수는 당뇨병에 대한 설명변수보다는 당뇨병에 의한 결과일 수 있다.
- 'GenHlth' / 'MentHlth' / 'PhysHlth' 를 별도로 구분하지 않아도 될 것이다.
- BMI의 카테고리(① 'underweight', 'healthy', 'overweight', 'obese' / ② 'not obese' / 'obese' )는 당뇨병 예측에 중요한 변수일 것이다.
+ 어떤 변수들의 조합이 예측력을 높일 수 있을 것인가.
가설들에 대한 근거
1. 'CholCheck'/ 'AnyHealthcare' / 'NoDocbcCost' 변수는 영향이 없을 것이다.
'CholCheck'
(1) Non-Diabetic과 Diabetic의 'CholCheck' mean (barplot)
sns.barplot(data = df_diabetes_binary, y = 'CholCheck', x = 'Diabetes_binary')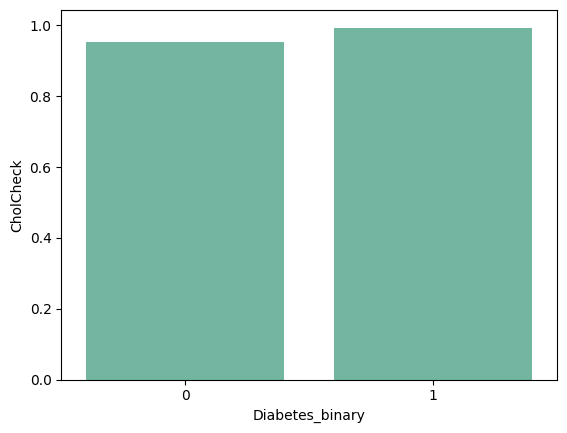
(2) 'CholCheck' - 'Diabetes_binary'의 상관계수 : 0.072523
'AnyHealthcare'
(1) Non-Diabetic과 Diabetic의 'AnyHealthcare' mean (barplot)
sns.barplot(data = df_diabetes_binary, y = 'AnyHealthcare', x = 'Diabetes_binary')
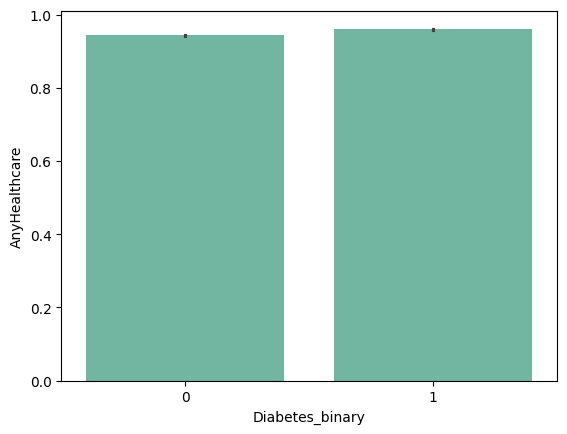
(2) 'AnyHealthcare' - 'Diabetes_binary'의 상관계수 : 0.025331
'NoDocbcCost'
(1) Non-Diabetic과 Diabetic의 'NoDocbcCost' mean (barplot)
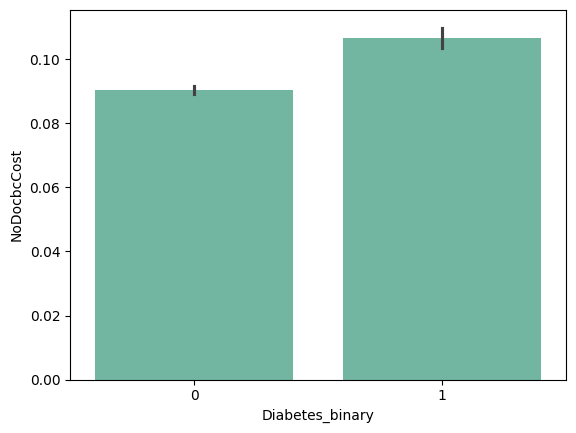
(2) 'NoDocbcCost' - 'Diabetes_binary'의 상관계수 : 0.020048
note. 'Diabetes_binary' 와의 correlation 절댓값 순서
| NoDocbcCost | Fruits | AnyHealthcare | Sex | Veggies | Smoker | MentHlth | HvyAlcoholConsump | CholCheck | Stroke | PhysActivity | Education | Income | PhysHlth | HeartDiseaseorAttack | Age | HighChol | BMI | DiffWalk | HighBP | GenHlth |
| 0.020048 | 0.024805 | 0.025331 | 0.032724 | 0.041734 | 0.045504 | 0.054153 | 0.06595 | 0.072523 | 0.099193 | 0.100404 | 0.102686 | 0.140659 | 0.156211 | 0.168213 | 0.177263 | 0.194944 | 0.205086 | 0.205302 | 0.254318 | 0.27694 |
2. 'Stroke'/ 'HeartDiseaseorAttack' 변수는 당뇨병에 대한 설명변수보다는 당뇨병에 의한 결과일 수 있다.
| 'Stroke' | 'HeartDiseaseorAttack' |
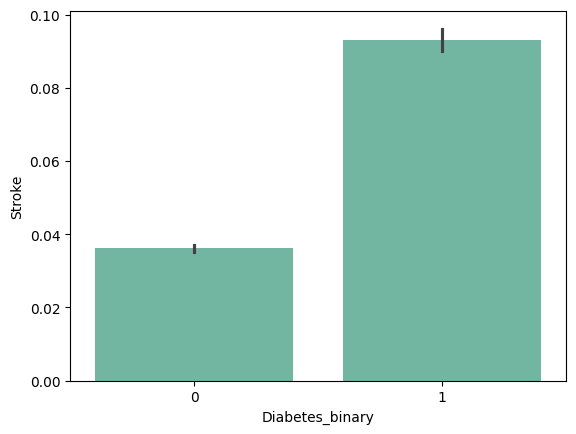 |
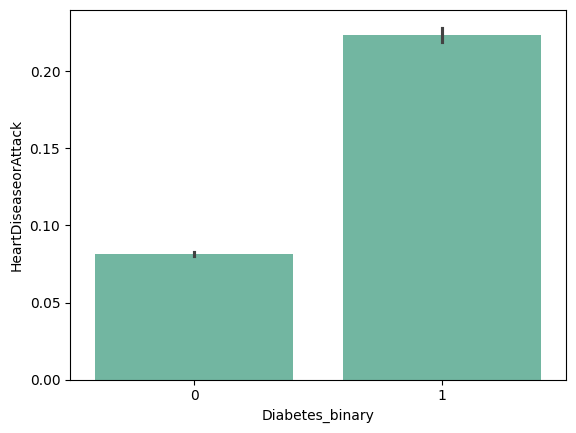 |
출처 : Stegmayr, B., & Asplund, K. (1995). Diabetes as a risk factor for stroke. A population perspective. Diabetologia, 38, 1061-1068.
Stroke incidence, case fatality and mortality in diabetic patients were compared to non-diabetic subjects in a 35-74-year-old population in northern Sweden (target population 241,000).
During an 8-year period, 1,544 stroke events in diabetic patients and 4,826 events in non-diabetic subjects were recorded.
The crude incidence of stroke was 1,000 per 100,000 in the diabetic men vs 247 in the non-diabetic men (relative risk 4.1; 95 % confidence interval 3.2-5.2).
Among diabetic women, the crude incidence was 757 per 100,000 and 152 in non-iabetic women (relative risk 5.8; 95 % confidence interval 3.7-6.9).
The 28-day case fatality among men was similar in the diabetic and non-diabetic stroke patients (18.6 vs 17.1%; p = 0.311), but significantly higher in diabetic women compared with non-diabetic women (22.2 vs 17.9 %; p = 0.02). When compared with the non-diabetic population, the overall mortality from stroke in the diabetic population (first and recurrent) was 4.4-times higher in male and 5.1 times higher in the female patients. Hypertension, atrial fibrillation, heart failure or myocardial infarction were all significantly more common in diabetic than in non-diabetic stroke patients. The
population attributable risk, a crude estimate of all strokes ascribed to diabetes mellitus, was 18 % in men and 22% in women. In Sweden, about 50 strokes are annually directly attributed to diabetes in a population of 100,000 in this age group. [Diabetologia (1995) 38: 1061-1068]
3. 'GenHlth' / 'MentHlth' / 'PhysHlth' 를 별도로 구분하지 않아도 될 것이다.
변수간 상관관계가 높은 편
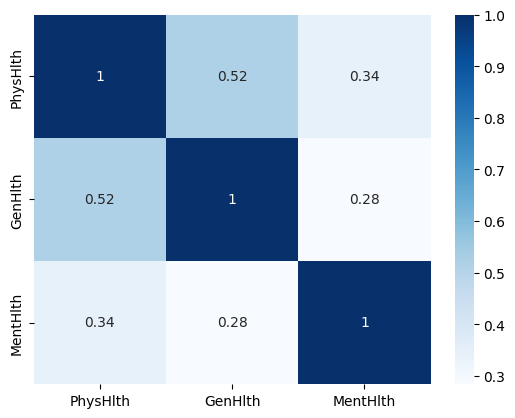
+ ) 'MentHlth' / 'PhysHlth' 0이 많아서 고민
'MentHlth' 중 응답 0 의 비율 : 0.663801
Now thinking about your mental health, which includes stress, depression, and problems with emotions, for how many days during the past 30 days was your mental health not good? scale 1-30 days

'PhysHlth' 중 응답 0 의 비율 : 0.595179
Now thinking about your physical health, which includes physical illness and injury, for how many days during the past 30 days was your physical health not good? scale 1-30 days

https://www.cdc.gov/brfss/annual_data/annual_2015.html
모델 검증을 위해
1. correlation이 0에 가까운 변수부터 제거?
corr_series = df_diabetes_binary.drop('Diabetes_binary', axis=1).corrwith(df_diabetes_binary.Diabetes_binary)
corr_series.abs().sort_values()
| NoDocbcCost | Fruits | AnyHealthcare | Sex | Veggies | Smoker | MentHlth | HvyAlcoholConsump | CholCheck | Stroke | PhysActivity | Education | Income | PhysHlth | HeartDiseaseorAttack | Age | HighChol | BMI | DiffWalk | HighBP | GenHlth |
| 0.020048 | 0.024805 | 0.025331 | 0.032724 | 0.041734 | 0.045504 | 0.054153 | 0.06595 | 0.072523 | 0.099193 | 0.100404 | 0.102686 | 0.140659 | 0.156211 | 0.168213 | 0.177263 | 0.194944 | 0.205086 | 0.205302 | 0.254318 | 0.27694 |
2. VIF 높은 값부터 제거?
from statsmodels.stats.outliers_influence import variance_inflation_factor
def calculat_vif(df) :
vif_data = pd.DataFrame()
vif_data['Variable'] = df.columns
vif_data['VIF'] = [variance_inflation_factor(df.values, i) for i in range(df.shape[1])]
return vif_data
vif_result = calculat_vif(df_diabetes_binary.drop(columns=['Diabetes_binary', 'Diabetes_bin_cat', 'Obesity_cat']))
vif_result.sort_values(by='VIF', ascending=False)
| 19 | 2 | 11 | 3 | 20 | 13 | 18 | 9 | 7 | 8 | 0 | 1 | 15 | 4 | 17 | 16 | 14 | 6 | 12 | 5 | 10 | |
| Variable | Education | CholCheck | AnyHealthcare | BMI | Income | GenHlth | Age | Veggies | PhysActivity | Fruits | HighBP | HighChol | PhysHlth | Smoker | Sex | DiffWalk | MentHlth | HeartDiseaseorAttack | NoDocbcCost | Stroke | HvyAlcoholConsump |
| VIF | 27.02937 | 21.45925 | 18.92962 | 17.34323 | 12.57782 | 10.96276 | 9.754024 | 5.279982 | 4.136394 | 2.825639 | 2.352183 | 2.066881 | 2.011309 | 1.985653 | 1.903811 | 1.850008 | 1.469319 | 1.296633 | 1.218706 | 1.128022 | 1.091476 |
3. 로지스틱 회귀 이외의 모델로 검증?
In a multivariate regression, there are multiple independent variables and multiple outcomes. In multivariable regression, there are multiple independent variables, but only one outcome.
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day024] git-협업 (0) | 2024.01.15 |
|---|---|
| Upstage AI Lab 2기 [Day015-022] EDA 조별 프로젝트 (5) 설명변수 조합 (0) | 2024.01.09 |
| 통계학 복습 (0) | 2024.01.06 |
| Upstage AI Lab 2기 [Day015-022] EDA 조별 프로젝트 (데이터 개요) (1) | 2024.01.04 |
| Upstage AI Lab 2기 [Day015-022] EDA 조별 프로젝트 (1) 기초통계 (0) | 2024.01.04 |

