2024년 1월 4일 (목) Day_017
혜윤 작업
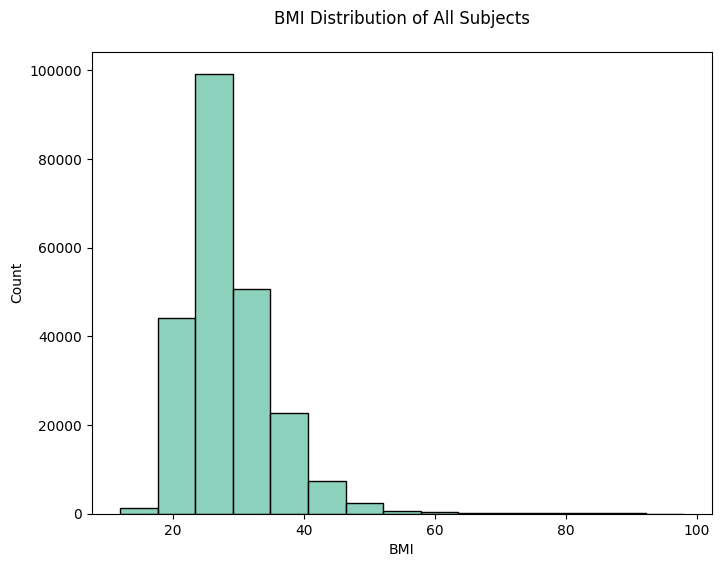
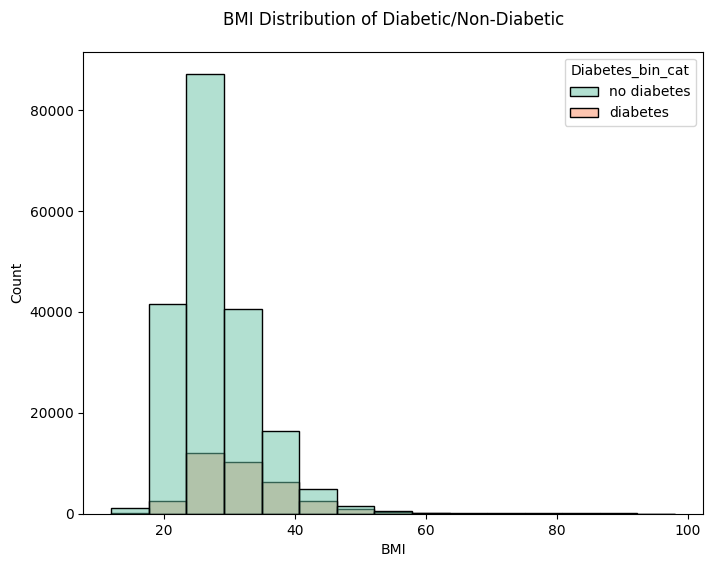
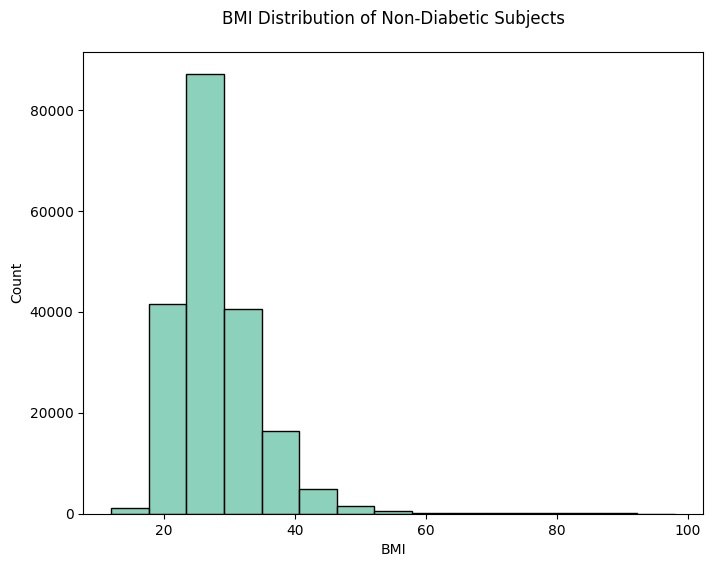
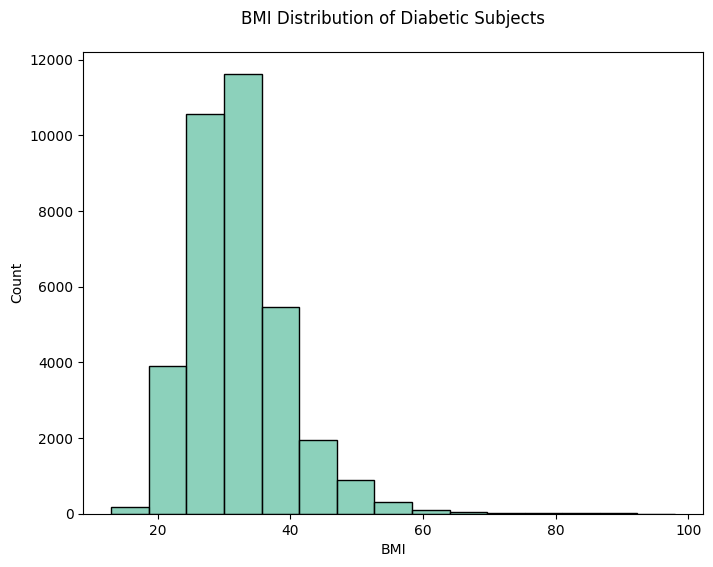
1. histplot for BMI
 |
 |
 |
 |
plt.figure(figsize=(8,6))
sns.histplot(data=df_diabetes_binary, x='BMI', bins=15)
plt.title('BMI Distribution of All Subjects', pad=20)
plt.show()
plt.figure(figsize=(8,6))
sns.histplot(data=df_diabetes_binary, x='BMI', bins=15, hue='Diabetes_bin_cat')
plt.title('BMI Distribution of Diabetic/Non-Diabetic', pad=20)
plt.show()
plt.figure(figsize=(8,6))
sns.histplot(data=df_diabetes_binary, x='BMI', bins=10, hue='Diabetes_bin_cat')
plt.title('BMI Distribution of Diabetic/Non-Diabetic', pad=20)
plt.show()
plt.figure(figsize=(8,6))
sns.histplot(data=df_diabetes_binary[df_diabetes_binary['Diabetes_binary'] == 0], x='BMI', bins=15)
plt.title('BMI Distribution of Non-Diabetic Subjects', pad=20)
plt.show()
2. countplot for Mental Health
 |
 |
 |
 |
plt.figure(figsize=(8,6))
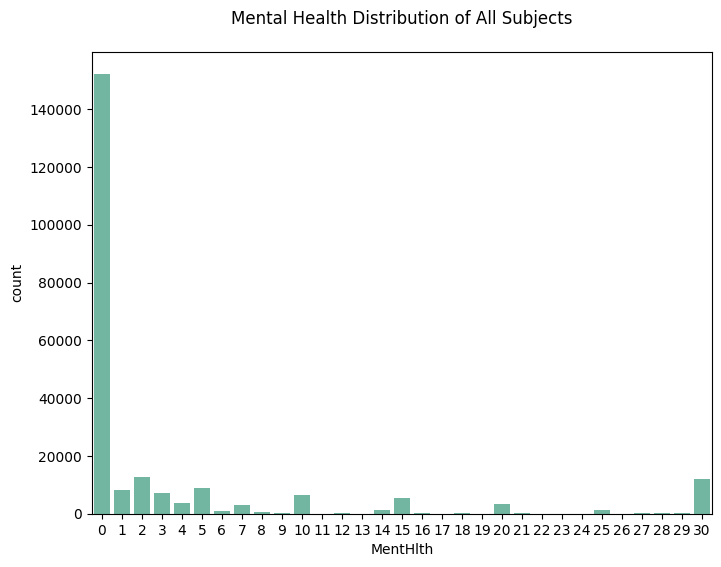
sns.countplot(data=df_diabetes_binary, x='MentHlth')
plt.title('Mental Health Distribution of All Subjects', pad=20)
plt.show()
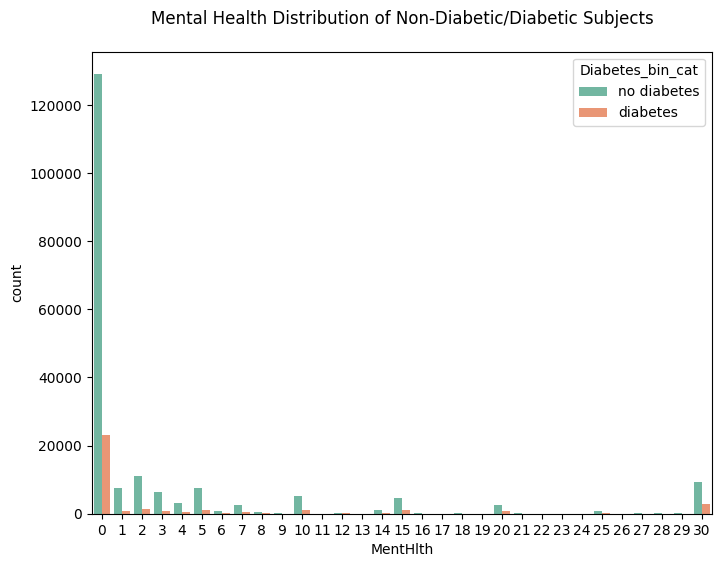
plt.figure(figsize=(8,6))
sns.countplot(data=df_diabetes_binary, x='MentHlth', hue='Diabetes_bin_cat')
plt.title('Mental Health Distribution of Non-Diabetic/Diabetic Subjects', pad=20)
plt.show()
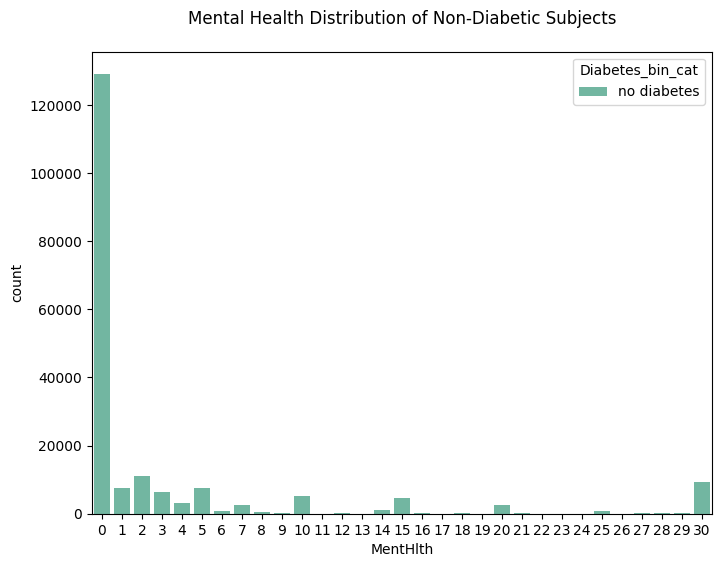
plt.figure(figsize=(8,6))
sns.countplot(data=df_diabetes_binary[df_diabetes_binary['Diabetes_binary'] == 0], x='MentHlth', hue='Diabetes_bin_cat')
plt.title('Mental Health Distribution of Non-Diabetic Subjects', pad=20)
plt.show()
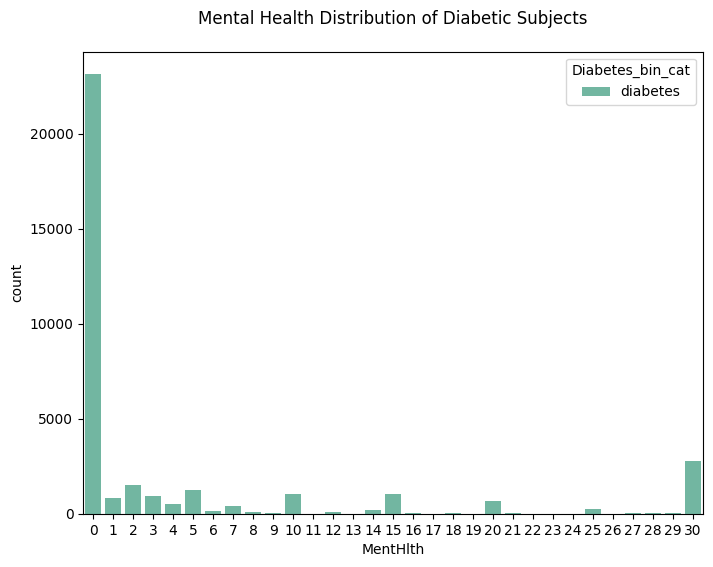
plt.figure(figsize=(8,6))
sns.countplot(data=df_diabetes_binary[df_diabetes_binary['Diabetes_binary'] == 1], x='MentHlth', hue='Diabetes_bin_cat')
plt.title('Mental Health Distribution of Diabetic Subjects', pad=20)
plt.show()
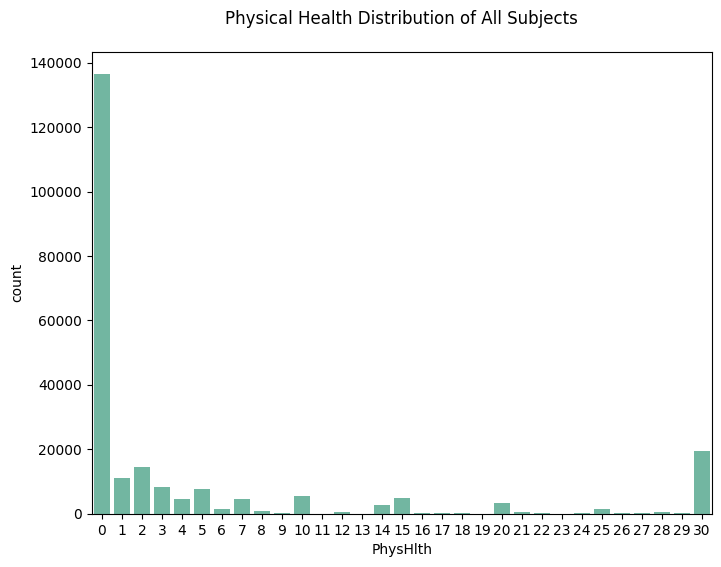
3. countplot for Physical Health
 |
 |
 |
 |
plt.figure(figsize=(8,6))
sns.countplot(data=df_diabetes_binary, x='PhysHlth')
plt.title('Physical Health Distribution of All Subjects', pad=20)
plt.show()
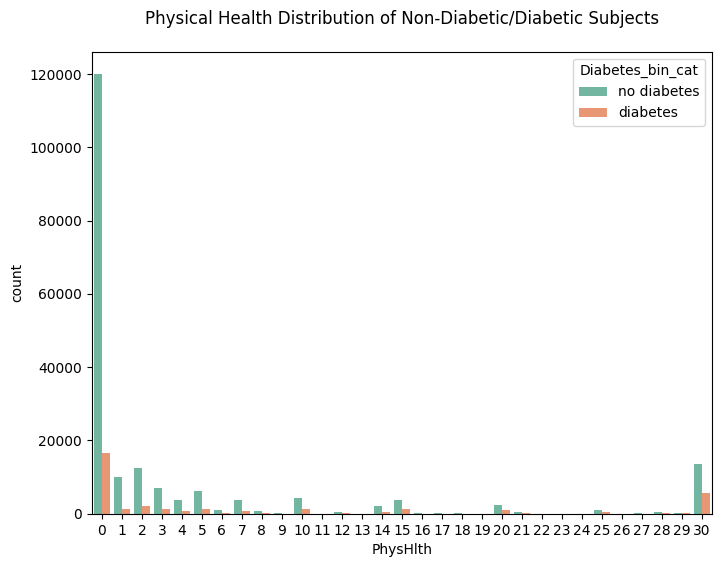
plt.figure(figsize=(8,6))
sns.countplot(data=df_diabetes_binary, x='PhysHlth', hue='Diabetes_bin_cat')
plt.title('Physical Health Distribution of Non-Diabetic/Diabetic Subjects', pad=20)
plt.show()
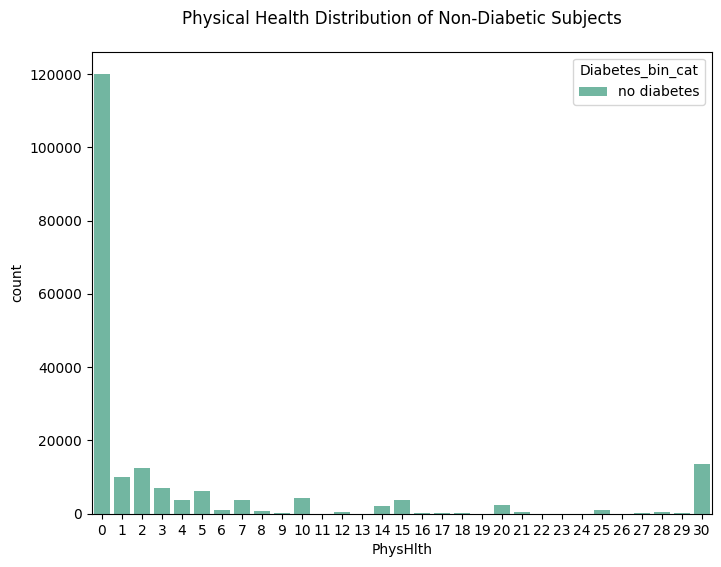
plt.figure(figsize=(8,6))
sns.countplot(data=df_diabetes_binary[df_diabetes_binary['Diabetes_binary'] == 0], x='PhysHlth', hue='Diabetes_bin_cat')
plt.title('Physical Health Distribution of Non-Diabetic Subjects', pad=20)
plt.show()
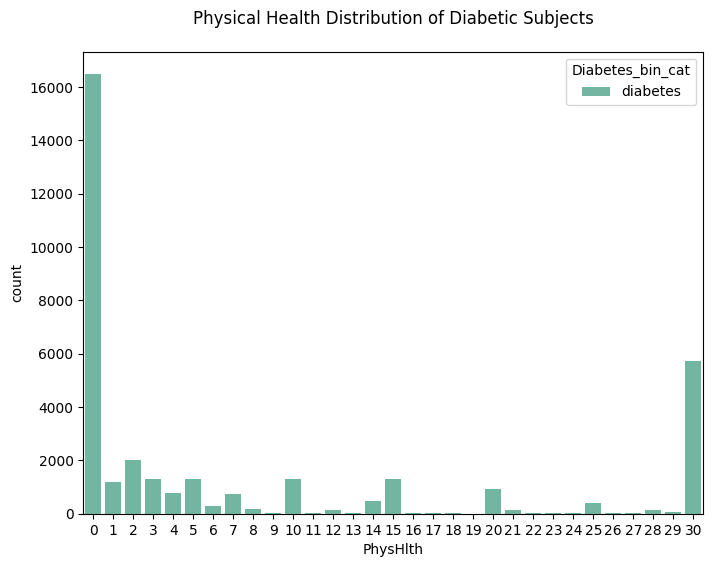
plt.figure(figsize=(8,6))
sns.countplot(data=df_diabetes_binary[df_diabetes_binary['Diabetes_binary'] == 1], x='PhysHlth', hue='Diabetes_bin_cat')
plt.title('Physical Health Distribution of Diabetic Subjects', pad=20)
plt.show()
* 추가로 하고 싶은 작업 : Mental Health / Physical Health 값이 0, 30인 데이터 제외한 분포도 보기
4. countplot for General Health
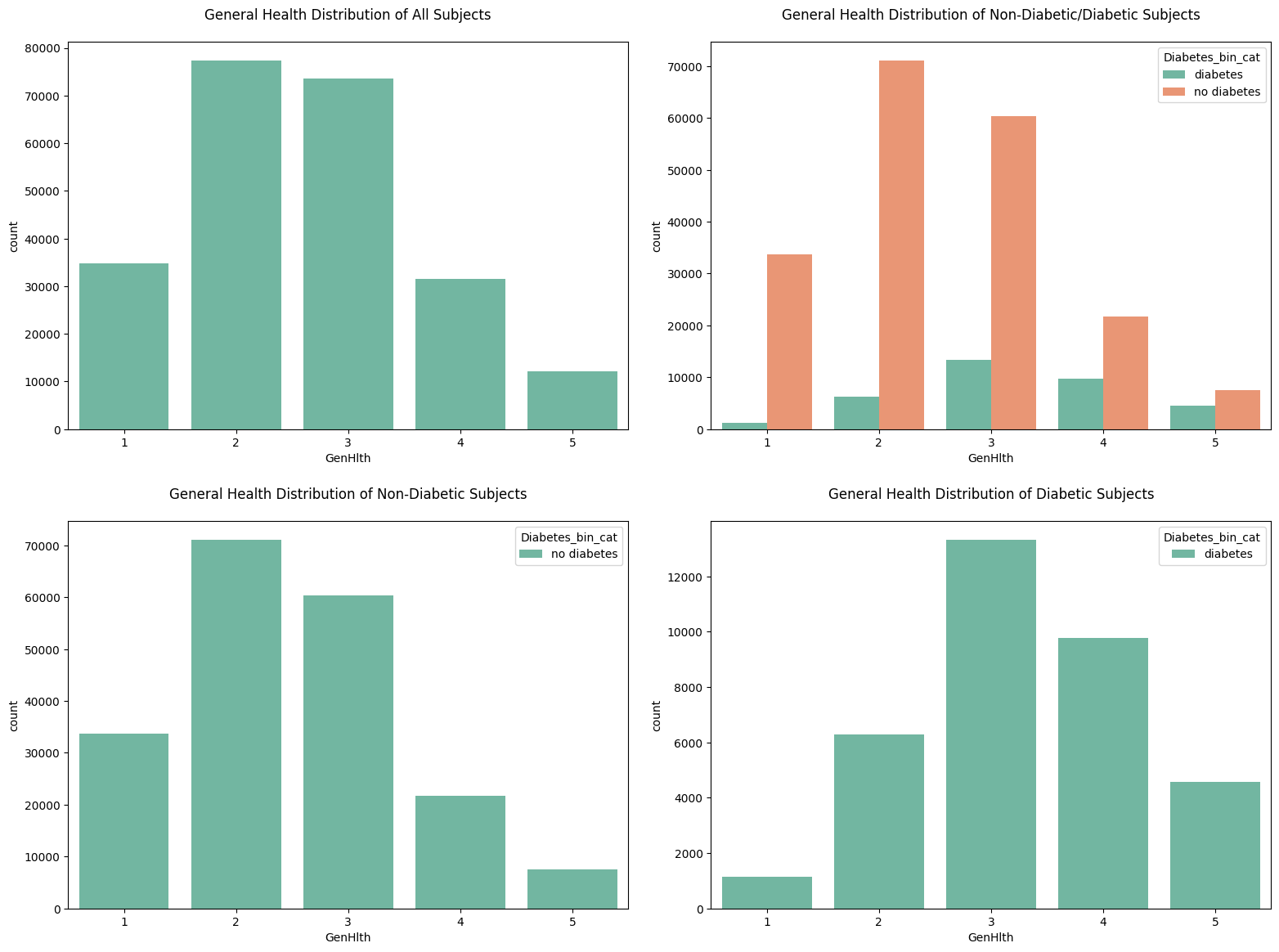
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
sns.countplot(data=df_diabetes_binary, x='GenHlth', ax=axes[0, 0])
axes[0, 0].set_title('General Health Distribution of All Subjects', pad=20)
sns.countplot(data=df_diabetes_binary, x='GenHlth', hue='Diabetes_bin_cat', ax=axes[0, 1])
axes[0, 1].set_title('General Health Distribution of Non-Diabetic/Diabetic Subjects', pad=20)
sns.countplot(data=df_diabetes_binary[df_diabetes_binary['Diabetes_binary'] == 0], x='GenHlth', hue='Diabetes_bin_cat', ax=axes[1, 0])
axes[1, 0].set_title('General Health Distribution of Non-Diabetic Subjects', pad=20)
sns.countplot(data=df_diabetes_binary[df_diabetes_binary['Diabetes_binary'] == 1], x='GenHlth', hue='Diabetes_bin_cat', ax=axes[1, 1])
axes[1, 1].set_title('General Health Distribution of Diabetic Subjects', pad=20)
plt.tight_layout(pad=2.0)
plt.show()
5. countplot for Age
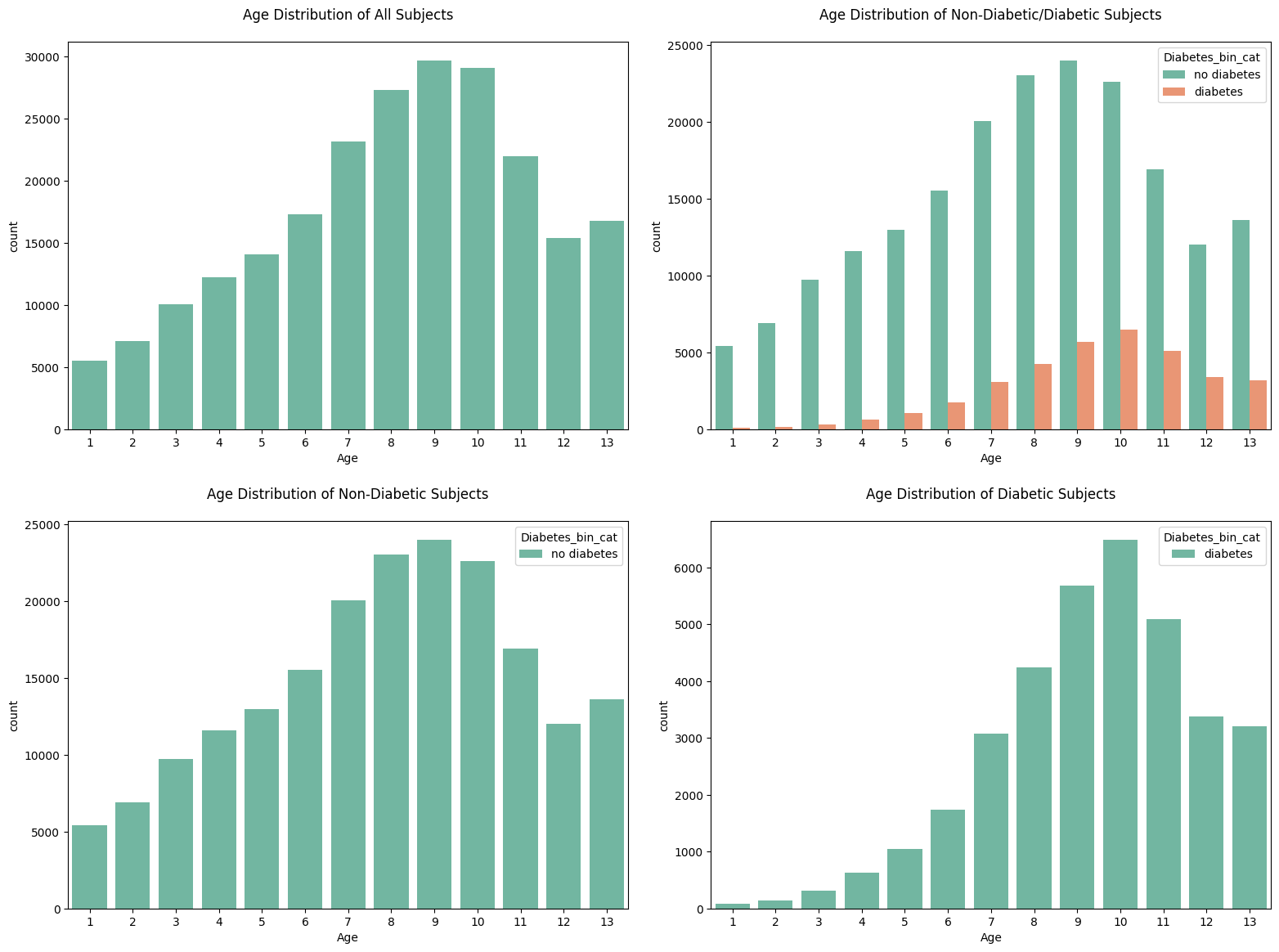
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
sns.countplot(data=df_diabetes_binary, x='Age', ax=axes[0, 0])
axes[0, 0].set_title('Age Distribution of All Subjects', pad=20)
sns.countplot(data=df_diabetes_binary, x='Age', hue='Diabetes_bin_cat', ax=axes[0, 1])
axes[0, 1].set_title('Age Distribution of Non-Diabetic/Diabetic Subjects', pad=20)
sns.countplot(data=df_diabetes_binary[df_diabetes_binary['Diabetes_binary'] == 0], x='Age', hue='Diabetes_bin_cat', ax=axes[1, 0])
axes[1, 0].set_title('Age Distribution of Non-Diabetic Subjects', pad=20)
sns.countplot(data=df_diabetes_binary[df_diabetes_binary['Diabetes_binary'] == 1], x='Age', hue='Diabetes_bin_cat', ax=axes[1, 1])
axes[1, 1].set_title('Age Distribution of Diabetic Subjects', pad=20)
plt.tight_layout(pad=2.0)
plt.show()
6. countplot for Education
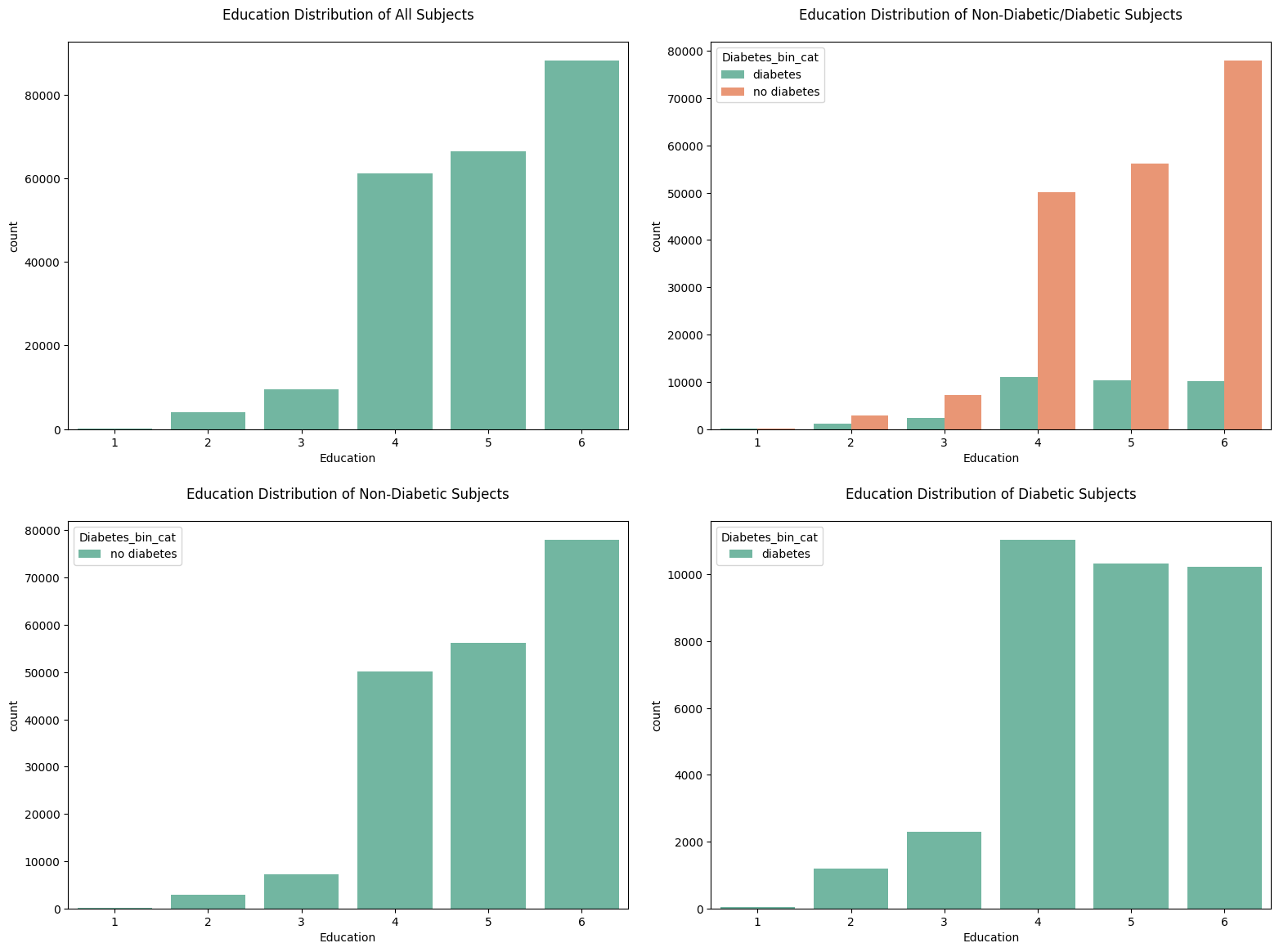
7. countplot for Income
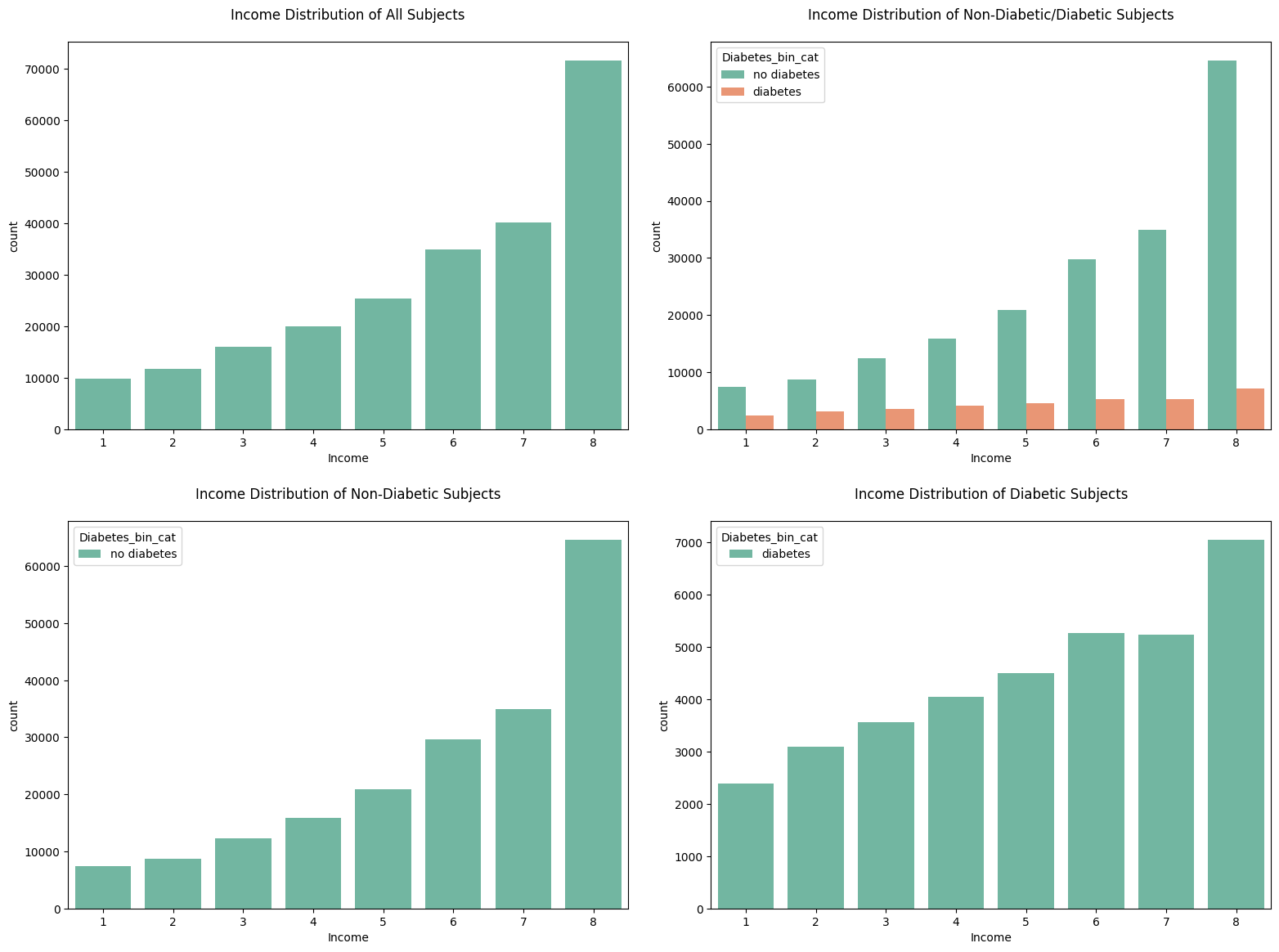
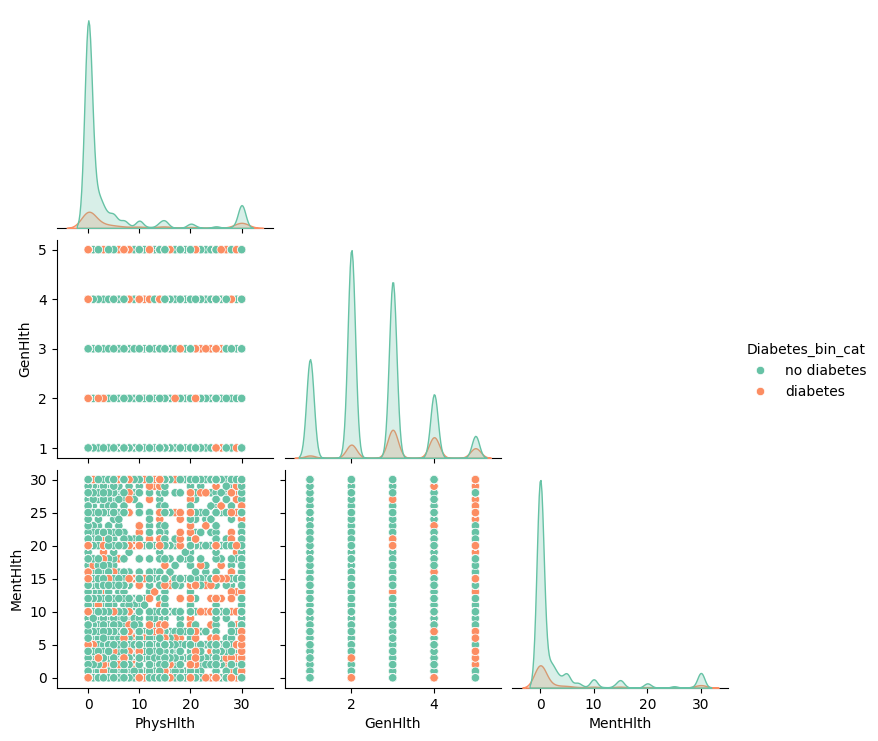
8. pairplot for 'PhysHlth', 'GenHlth', 'DiffWalk', 'MentHlth'
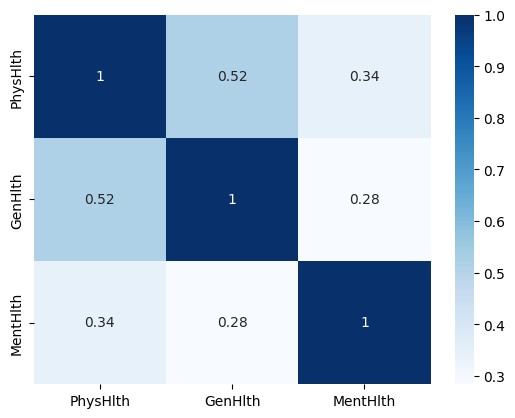
barplot, correlation sorting으로부터 'PhysHlth', 'GenHlth', 'MentHlth'간 상관관계가 높을 것으로 판단,
pairplot을 그려봤으나 결과는 NG
(1) GenHlth가 1to5의 카테고리 데이터라 그런듯
(2) 'PhysHlth', 'GenHlth'가 0~30까지라 scatter에서 어떤 패턴이 보이길 기대했으나 실패
'Upstage AI Lab 2기' 카테고리의 다른 글
| 통계학 복습 (0) | 2024.01.06 |
|---|---|
| Upstage AI Lab 2기 [Day015-022] EDA 조별 프로젝트 (데이터 개요) (1) | 2024.01.04 |
| Upstage AI Lab 2기 [Day015-022] EDA 조별 프로젝트 (1) | 2024.01.03 |
| Upstage AI Lab 2기 [Day014] (2) EDA 실습 (0) | 2023.12.31 |
| Upstage AI Lab 2기 [Day014] (1) Seaborn_기초 (0) | 2023.12.29 |



