Upstage AI Lab 2기
2023년 12월 29일 (금) Day_014
Day_014 실시간 강의 (오후) : EDA(Exploratory Data Analysis)
(패스트캠퍼스 김용담 강사님)
0) import libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
1) load data
[데이터 링크] https://www.kaggle.com/c/instacart-market-basket-analysis/data
path = r'./data/'
aisles = pd.read_csv(path + 'aisles.csv')
departments = pd.read_csv(path + 'departments.csv')
order_products_train = pd.read_csv(path + 'order_products_train.csv')
orders = pd.read_csv(path + 'orders.csv')
products = pd.read_csv(path + 'products.csv')- aisles / departments / products
- order_products_train
- orders
2) check info
memory_usage 등을 포함하여 각 data의 row와 column의 의미 파악
aisles.info()
departments.info()
order_products_train.info()
orders.info(memory_usage='deep')
products.info()
note: memory_usage='deep'
order의 경우 orders.info() 결과로 'memory usage: 182.7+ MB'로 표시됨
data 중 dtype이 object가 있는 경우 memory usage 가 바로 계산되지 않아서 memory_usage='deep' 를 이용하면 조금 더 자세하게 memory usage를 계산해줌
3) EDA
keyword : 관계형 DB
Q1. 어떤 Product가 가장 많이 reorder가 되었는가?
step1. merge : order_products_train & products
data = pd.merge(order_products_train, products, on='product_id', how='left')note. 이 data에서는 how='inner'를 써도 같은 결과가 나옴
어디가 더 큰 set인지 고민해보고 써야 함
step2. pivot_table : values=['reordered'], index = ['product_name']
pd.pivot_table(data = data, values=['reordered'], index = ['product_name'], aggfunc='sum')\
.sort_values(by='reordered', ascending=False)
# 또는
# order_products_train.groupby(['product_id']).sum()
+ Q1 - 1) product 개수는 49,688개인데, Q1의 결과는 39,123개인 이유?
: 현재 data상 구매 이력(order)이 없는 제품 (order_products_prior까지 보면 다른 결과가 나올 수 있음)
note. reorder = 0 이번이 첫번째 구매
+ Q1 - 2) 가장 많이 주문된 Product는?
tip : order count를 세면 가장 정확하지만, reordered 수를 count 하는 것으로 충분할 수 있음. 즉, Q1 결과물과 같음
data = order_products_train + products
Q2. reorder가 가장 많이 일어나는 department는?
필요한 data : data + departments
step0. 합쳐야할 데이터 컬럼 확인하기
departments.columns
# Index(['department_id', 'department'], dtype='object')
data.columns
# Index(['order_id', 'product_id', 'add_to_cart_order', 'reordered', 'product_name',
# 'aisle_id', 'department_id'], dtype='object')
step1. merge
data = pd.merge(data, departments, on='department_id', how='left')
step2. pivot_table : values=['reordered'], index=['department']
pd.pivot_table(data = data, values=['reordered'], index=['department'], aggfunc='sum')\
.sort_values(by='reordered', ascending=False).head(10)
note : DB normalization(db의 정규화) - 저장시 효율성을 위해 분리하여 저장, 분석시 필요한 정보만 merge
data = pd.merge(data, aisles, on='aisle_id', how='left')data = order_products_train + products + departments + aisles
Q3. order를 가장 많이 한 user는?
필요한 data : data + orders
step0. orders 전처리
orders = orders[orders.eval_set == 'train']
orders = orders.drop(columns='eval_set')
orders.columns
# Index(['order_id', 'user_id', 'order_number', 'order_dow', 'order_hour_of_day', 'days_since_prior_order'], dtype='object')
orders.sort_values(by='order_number', ascending=False)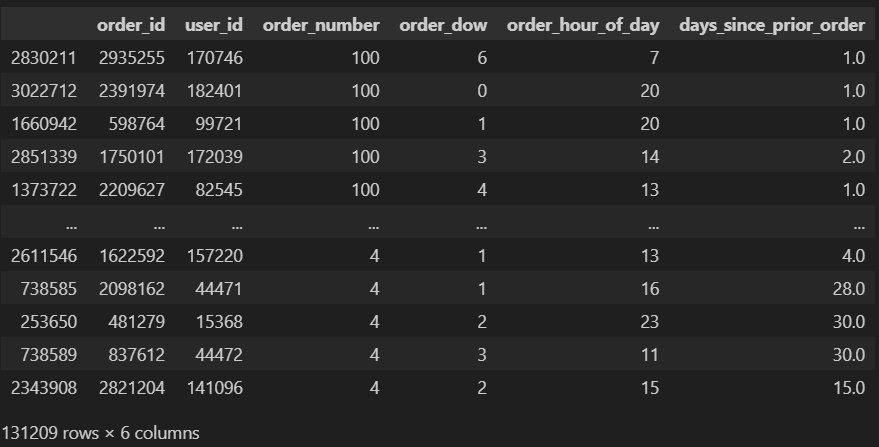
orders[orders.order_number == 100]
# 867 rows
step1. merge : data + orders
data = pd.merge(data, orders, on='order_id', how='left')
step2. pivot_table : values=['order_number'], index=['user_id']
pt_onum = pd.pivot_table(data=data, values=['order_number'], index=['user_id'], aggfunc='max')\
.sort_values(by='order_number', ascending=False)
# pt_onum = orders.pivot_table(index = 'user_id', values = 'order_number', aggfunc = 'max')
pt_onum[pt_onum.order_number == 100].index
# Int64Index([170746, 182401, 99721, 172039, 82545, 172054, 92052, 12772,
# 107809, 8779,
# ...
# 190983, 33645, 43265, 142245, 109020, 142304, 690, 69995,
# 103737, 33934],
# dtype='int64', name='user_id', length=867)
요약
| Q1. | Q2. | Q3. |
| order_products_train | order_products_train | order_products_train |
| + | + | + |
| products | products | products |
| + | + | |
| departments | departments | |
| + | + | |
| aisles | aisles | |
| + | ||
| orders |
Q4. order가 가장 많이 일어난 요일은?
orders.order_dow.value_counts()
# dow가 무슨 요일인지 definition에 없음
sns.countplot(data=orders, x='order_dow')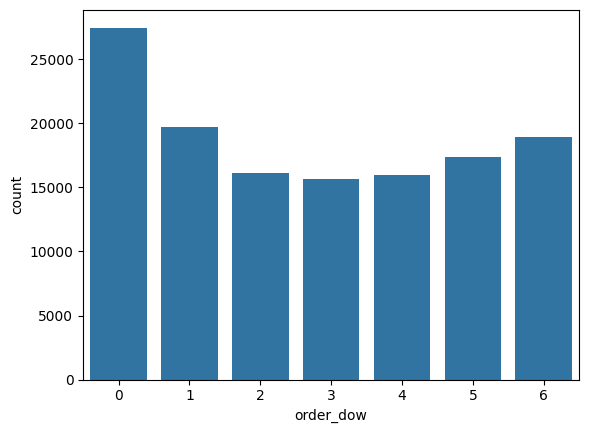
sns.countplot(data=orders, x='order_hour_of_day')
note. 온라인 판매에서는 요일에 따른 구매 패턴 변화가 중요한 정보
+ Q4 - 1) 재구매가 가장 많이 일어나는 요일
data.pivot_table(index = 'order_dow', values='reordered', aggfunc = 'sum')\
.sort_values(by='reordered', ascending=False)
Q5. 재구매율이 높은 product top10은?
data.pivot_table(index = 'product_name', values = 'reordered', aggfunc = 'mean')\
.sort_values(by='reordered', ascending=False).head(10)
note1. reordered의 value가 1.0인 이유는 데이터 일부만 가지고 분석해서 그런 것.
note2. recommendation을 위해서는 user별 재구매율을 봐야함.
+ ) session-based recommendation - 실시간 추천, action(click, add-to-cart, buy)과 함께 예측
+ ) ctr(clickthrough rate)
+ ) cold-start problem
Q6. 사람들이 평균적으로 재구매를 하는 기간은?
data.days_since_prior_order.mean()
# NaN은 자동으로 mean 계산에서 빠짐
Q7. days_since_prior_order에 따른 reorder 횟수 변화
pt_days = data.pivot_table(index = 'days_since_prior_order', values='reordered', aggfunc = 'sum')
pt_days = pt_days.reset_index()[:-1]
plt.figure(figsize=(18, 6))
sns.barplot(x = pt_days.days_since_prior_order.astype(int), y=pt_days.reordered)
sns.lineplot(x = pt_days.days_since_prior_order.astype(int), y=pt_days.reordered, lw=4)
Extra Q. user들이 구매 패턴에 따라 어떤 그룹으로 묶일까? (Customer Segmentation)
step1. Count Vectorization(≒ Bag-of-Words)
user profiling : user를 어떻게 정의할것인가?
-> vector space 를 정의해야 함
pd.crosstab(data['user_id'], data['department'])

step2. 비슷한 유저끼리 partitioning -> clustering
# !pip install scikit-learn
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3, random_state=42)
labels = model.fit_predict(user_matrix)
df = pd.DataFrame({
'user_id': user_matrix.index,
'group_id' : labels
})
data_fin = pd.merge(data, df, on='user_id')
g0 = data_fin[data_fin.group_id == 0]
g0.product_name.value_counts()[:10]
g0.department.value_counts()[:10]
g1 = data_fin[data_fin.group_id == 1]
g1.product_name.value_counts()[:10]
g1.department.value_counts()[:10]
g2 = data_fin[data_fin.group_id == 2]
g2.product_name.value_counts()[:10]
g2.department.value_counts()[:10]

'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day015-022] EDA 조별 프로젝트 (1) 기초통계 (0) | 2024.01.04 |
|---|---|
| Upstage AI Lab 2기 [Day015-022] EDA 조별 프로젝트 (1) | 2024.01.03 |
| Upstage AI Lab 2기 [Day014] (1) Seaborn_기초 (0) | 2023.12.29 |
| Upstage AI Lab 2기 [Day012] (2) pandas_기초_1 (0) | 2023.12.28 |
| Upstage AI Lab 2기 [Day012] (1) numpy_기초 (0) | 2023.12.27 |


