Upstage AI Lab 2기
2023년 12월 29일 (금) Day_014
Day_014 실시간 강의 (오전) :
(패스트캠퍼스 김용담 강사님)
시각화를 편하게 쓸 수 있도록 만들어진 라이브러리
특징적인 플롯
jointplot - density와 scatterplot이 합쳐진 형태
pairplot - pairwise 교차해서 graph
clustermap - 계층정보 같이 표시
업데이트 느리고 만들어진지 얼마 안 된 라이브러리
version up 되면 꼭 체크해야 될 것들이 있는 라이브러리임
(matplotlib은 자유도가 높은 대신 난이도도 높음 -> 고수는 ppt처럼 쓸 수도 있음)
주로 pairwise보다는 개별 feature 단위로 볼 일이 많음.
0) getting started with seaborn
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
1) seaborn의 data load
data = sns.load_dataset("penguins")
data = data.dropna()
2) seaborn의 plots
사용방법이 통일성 있음
plot 함수 기본 형태 : sns._______plot(data=, x=, y=, hue=, palette=)
연속형 변수 (Continuous variable) vs. discrete variable
hue= discrete variable
palette (예. 'viridis', 'summer', 'winter', 'Blues', 'Set2')
https://seaborn.pydata.org/tutorial/color_palettes.html
(1) histplot : 연속형 변수의 구간별 분포
sns.histplot(data=, x=, hue=, palette= , bins=)
y는 count, 입력하지 않아도 됨.
bins = 구간의 갯수 (일반적으로 10~30 사용)
sns.histplot(data=data,
x= 'body_mass_g',
hue = 'species',
palette="Set2",
multiple='stack',
bins=10
)
(2) displot : 여러 개의 distribution을 subplot으로 출력
kind = "hist"(히스토그램) / "kde"(밀도) / "ecdf"
col = column-wise 기준
row = row-wise 기준
sns.displot(
data=data,
x="flipper_length_mm",
kind='hist',
col ='species',
row='island',
hue='sex',
multiple='stack',
)

(3) barplot : discrete 변수를 기준으로 한 수치
default aggfunc 은 mean으로 설정되어 있어서 통계적 유의성을 보여주는 errorbar가 같이 표시됨.
x, y를 바꿔서 가로/세로를 바꿀 수 있음.
-> 기본적으로 discrete 변수를 기준으로 값을 plot하기 때문.
sns.barplot(data=data, x='species', y='body_mass_g',
hue='sex', palette='Set2',
errorbar=None)

sns.barplot(data=data, y='species', x='body_mass_g',
hue='sex', palette='Set2',
errorbar=None)

(4) countplot : discrete 변수에 따른 분포
sns.countplot(data=data, x='species')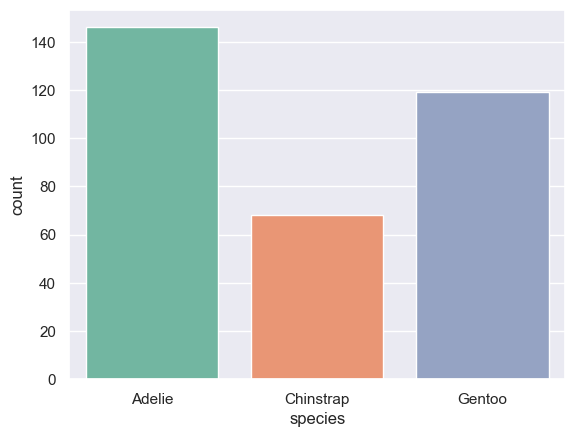
(5) boxplot
box : first quartile(25%) ~ third quartile(75%) => cdf 상 50%의 데이터가 분포한 범위 표현
bar : median (mean은 outlier 의 영향을 많이 받음.)
lower / upper bound : Q25 - IQR*1.5 / Q75 + IQR*1.5 ※ min / max 아님!!
(IQR = Inter Quartile Range)
note. outlier 정의는 방법론마다 다름. boxplot은 lower / upper bound를 벗어나는 data를 아웃라이어로 봄.
주의. feature 1개를 기준으로 outlier를 정의하는 것은 naive한 접근법
sns.boxplot(data=data, x='species', y='bill_depth_mm')
(6) violinplot : boxplot + min/max
sns.violinplot(data=data, x='species', y='body_mass_g')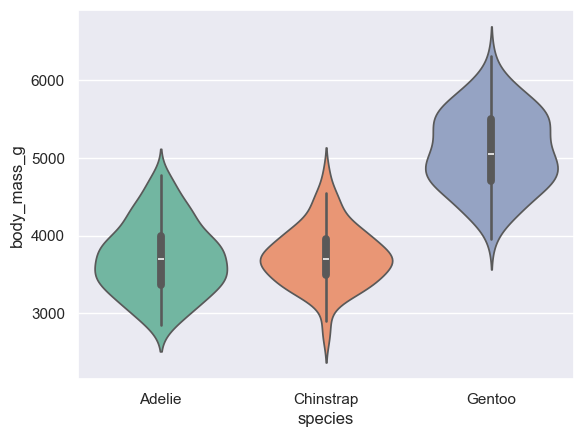
(7) lineplot : 경향성
x축 : 시간, index 등
x축, y축 모두 수치형 데이터
default로 confidential interval 같이 표현됨 (errorbar=None 으로 표시되지 않게 할 수 있)
sns.lineplot(data=data, x='body_mass_g', y='flipper_length_mm')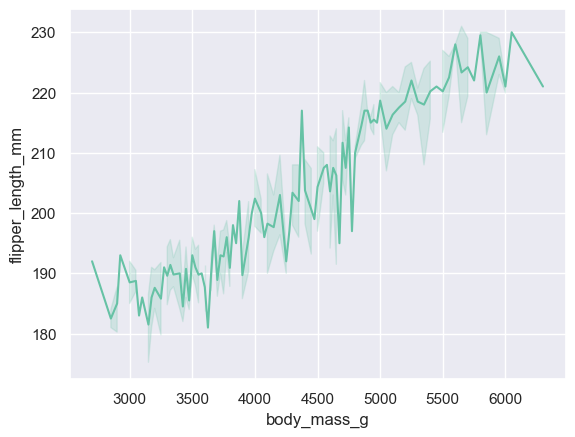
note : sns.lineplot(x= , y= )
꼭 input으로 dataframe이 필요한 것은 아님.
sequential data인 개별 data를 x, y로 넣어줄 수 있으며, 이 때 x, y의 크기는 같아야 함.
(8) pointplot
point = mean
mean의 오차범위와 경향성을 표시
sns.pointplot(data=data, x='species', y='flipper_length_mm')
(9) scatterplot
sns.scatterplot(data=data, x='bill_depth_mm', y='bill_length_mm', hue='species')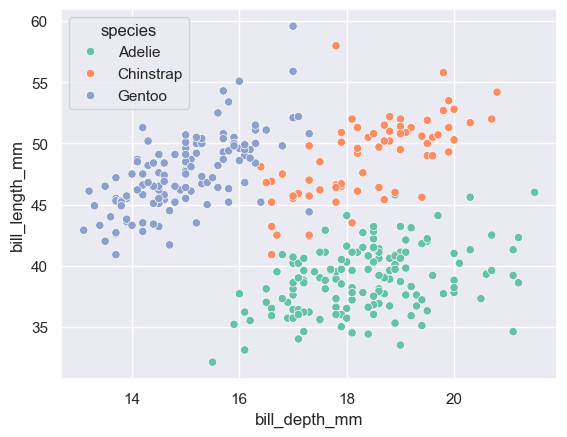
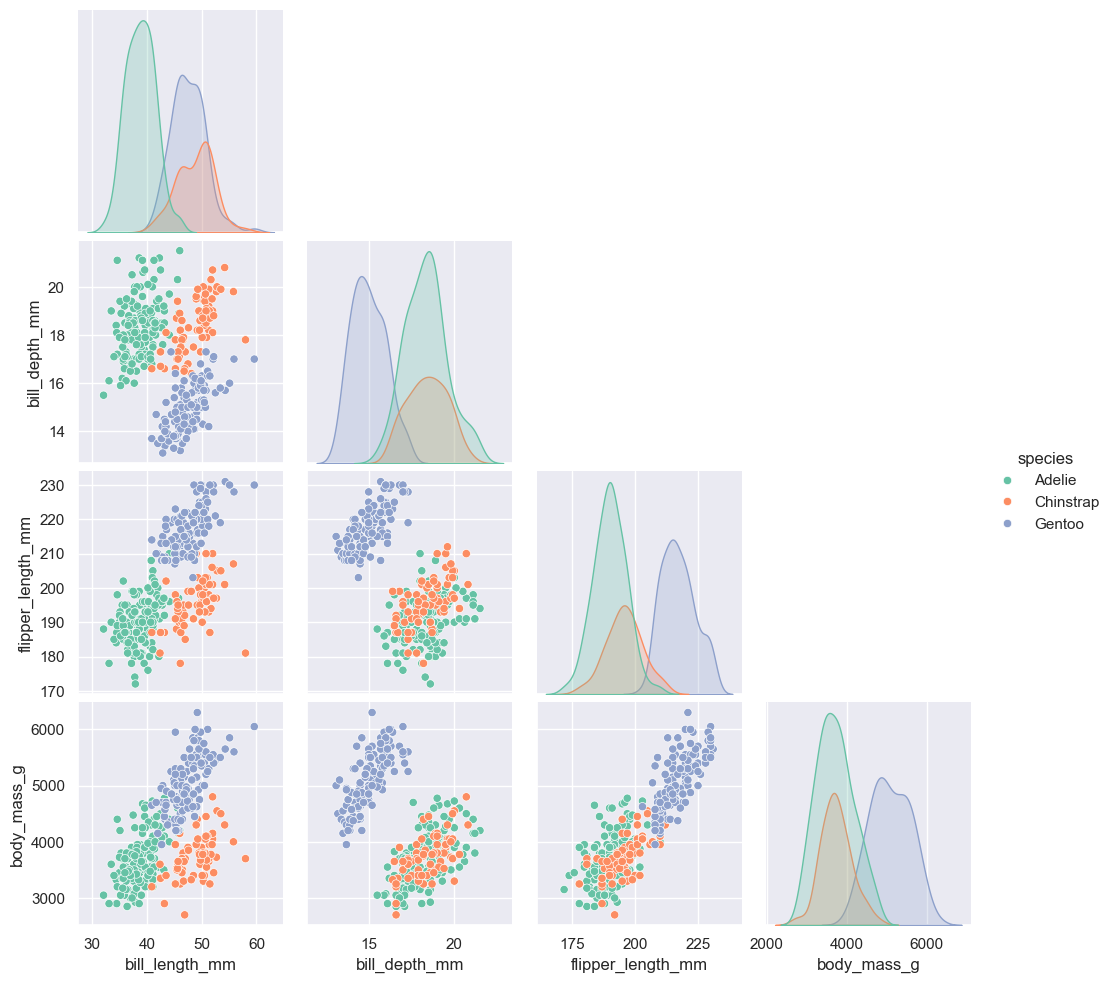
(10) pairplot
scatterplot은 한 번에 feature 두 개씩 밖에 못 보는 점을 보완
모든 numeric data에 대해 plot
(보통 6개 feature 정도 까지만 봄)
sns.pairplot(data=data, hue='species')
sns.pairplot(data=data, hue='species', corner=True)
(11) heatmap
corr()와 함께 사용
(heatmap만 내부 구현체가 달라서 palette= 대신 cmap= 사용)
import pandas as pd
data.corr()
sns.heatmap(data.corr(), annot=True, fmt='.3f', cmap='Blues')

Q & A
Q : 정규화는 안 하나요?
A : 원본 데이터의 스케일이 달라져서 의미가 없음. EDA에서는 scaling 잘 안함.
Data Science를 위해 공부할 라이브러리 : seaborn, matplotlib, dash, plotly
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day015-022] EDA 조별 프로젝트 (1) | 2024.01.03 |
|---|---|
| Upstage AI Lab 2기 [Day014] (2) EDA 실습 (0) | 2023.12.31 |
| Upstage AI Lab 2기 [Day012] (2) pandas_기초_1 (0) | 2023.12.28 |
| Upstage AI Lab 2기 [Day012] (1) numpy_기초 (0) | 2023.12.27 |
| Upstage AI Lab 2기 [Day010] (1) Flask 기초 (0) | 2023.12.26 |


