Upstage AI Lab 2기
2024년 5월 30일 (목) Day_116
[ 0 ] 코드 필사[ 0 ] 산책- [ ] 경진대회 회고 정리하기
- [ ] QLoRA 논문 읽기
- [ ] 강의 복습 및 내용 정리하기
[ 0 ] 카운트 기반 언어모델- [ ] 언어모델 평가방법
[LM to LLM] (2-2) 카운트 기반 언어모델
1. 카운트 기반 단어 표현 방법 : 국소 표현(Local Representation) / 분산 표현 (Dense Representation)
Local Representation
- 단어별 고유식별자로 mapping (e.g. one-hot encoding), 각 단어 = 벡터에서 1개의 차원
- 고차원, 차원간 독립적
- 단어간 의미적 관계를 직접적으로 표현X
Dense Representation
- 주변 단어와의 관계로 표현, 주변 맥락의 영향을 받음. 저차원의 dense vector로 표현. 단어의 의미적 다양성 내포. (word embedding)
- 저차원, 각 차원은 의미적 특성을 나타냄
- 의미적 유사성을 벡터간 거리로 표현 가능
참고자료:
https://newtoner.tistory.com/45
Bag of Words
- 카운트 기반, 가장 전통적·기본적 방식. 어휘 사전을 구축.
- 단어 순서 고려 X, frequency만 중시 → 단어 간 관계 표현불가
( → 카운트 기반 언어 표현을 보완하기 위해 의미 기반 언어 표현이 나옴)
장 : 구현 쉬움. 분절이 정확할 때 유용.
단 : 문맥정보 무시. 차원의 저주.(∵ 임베딩 벡터의 차원 = 단어의 개수). 동음이의어, 다의어 표현 불가.
word 기준 : 영어는 stemming, 한국어는 형태소 분석 후 원형
2. TF-IDF (Term Frequency-Inverse Document Frequency)
근간 이론
- Inverted Index : 검색엔진에서 데이터를 효율적으로 검색하기 위한 구조
- key = 단어, value = 단어가 포함된 list of documents
- Comparison Function : TF-IDF 기반 ranking
- query 와 document 사이의 연관성 (frequency 기반)
- query 와 매칭되는 term의 빈도수가 더 높은 문서를 찾고 순위화
- Document Frequency
- query가 특정 document에만 나타남 → 연관성 ↑
- 문서 내 term의 위치
- query가 2개 이상일 때, 문서 내에서 가까움 → query 와 document의 연관성 ↑
- Document-Term Matrix ★
- 모든 문서에 등장하는 term들의 출연빈도 or 중요도 행렬화
- 문서/단어 → 행/열
- value → 빈도수 (BoW or TF-IDF)
TF-IDF (Term Frequency-Inverse Document Frequency)
1. Term Frequency
: (문서 내) 특정 문서 d에서 단어 t가 등장한 횟수 (DTM과 동일)
2. Inverse Document Frequency
: (문서 간) 단어가 제공하는 정보의 양 (i.e. 희귀한 단어일수록 정보의 양 ↑, 흔한 단어는 정보가 되지 않음)
N = 전체 문서의 수
df = 단어가 포함된 문서의 수

TF-IDF : 기계 독해, 문서 요약, 문서 군집화, 키워드 추출
BM25
TF-IDF의 단점 보완한 metric. 정보검색분야에서 널리 사용되는 ranking function 방법론 중 하나
TF-IDF와 유사 but 문서의 길이까지 고려 + 특정 단어가 문서 내 지나치게 반복 시 penalty → Robustness ↑
TF의 영향 ↓, IDF의 영향 ↑, 문서길이의 영향 ↓

avgdl : 모든 문서의 평균 길이
k1, b : hyperparameter
문서 길이가 다른 문서간 공정한 비교 가능 but 단어의 순서/문맥 고려 X
→ 의미 기반 방법론의 등장
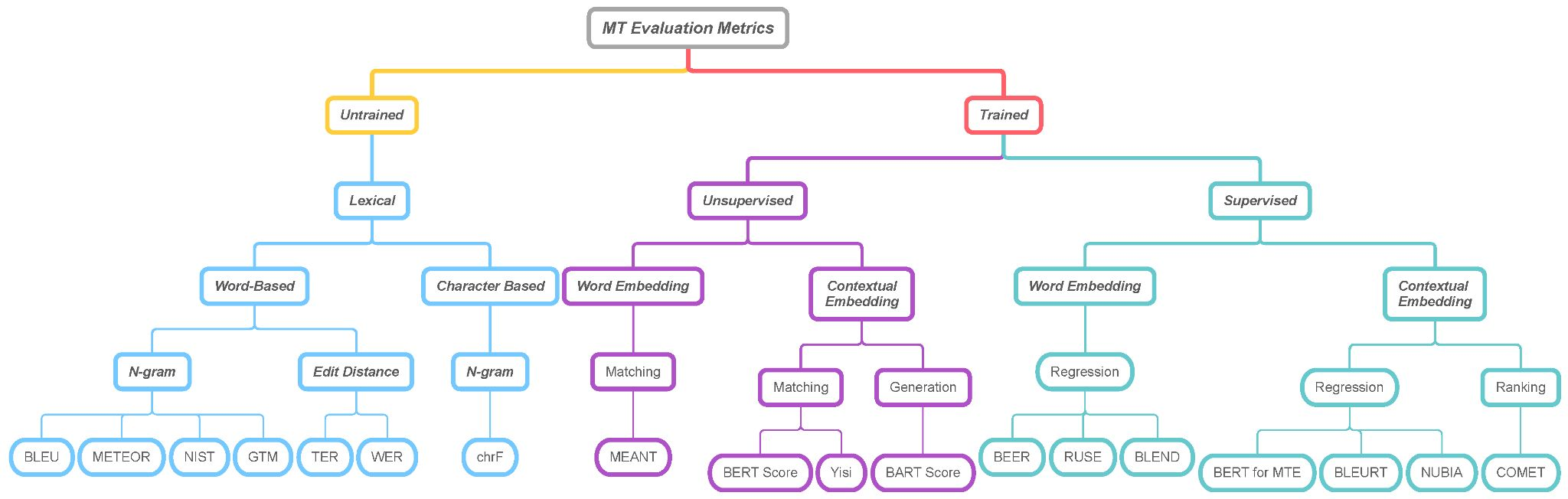
[LM to LLM] (2-3) 언어모델 평가 방법
- PPL (Perplexity)
- confused 정도 표현. 낮을수록 좋음. 확률기반으로 계산
- BLEU (Bilingual Evaluation Understudy Score)
- N-gram overlap, Brevity Penalty(너무 짧은 생성문에 대한 페널티), Clipping
- but 문맥정보 반영 X
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- 요약평가 지표로 많이 사용됨
- METEOR (Metric for Evaluation of Translation with Explicit Ordering)
- 기계번역 지표, BLEU보다 robust하고 발전된 지표. 정확성&유창성
- exact match & synonym match & order match & penalty
- chrF (character n-gram F-score)
- 기계번역 평가 지표
- BLEURT (Bilingual Evaluation Understudy with Representations from Transformers)
- 딥러닝 기반의 평가 방식. 의미, 문맥도 고려 가능
- pretrained LM의 기계 번역을 transformer로 평가
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day117] Data-Centric AI (0) | 2024.05.31 |
|---|---|
| Upstage AI Lab 2기 [Day117] LM to LLM (0) | 2024.05.30 |
| Upstage AI Lab 2기 [Day109] NLP 경진대회 - LoRA 공부 (0) | 2024.05.21 |
| Upstage AI Lab 2기 [Day102] NLP - Next Encoder Model (0) | 2024.05.09 |
| Upstage AI Lab 2기 [Day102] NLP - Encoder - Decoder Model(BART) (이론) (0) | 2024.05.09 |



