Upstage AI Lab 2기
2024년 5월 31일 (금) Day_117
todo
- [ ] 경진대회 회고 정리하기
- [ ] QLoRA 논문 읽기
- [ ] 테디노트 AutoRAG
[ 0 ] 강의 수강[ 0 ] Data Centric AI[ 0 ] Data-Centric AI란 무엇인가?[ 0 ] Data-Centric AI의 미래[ 0 ] 데이터 구축 프로세스 소개[ 0 ] 데이터 구축 기획서 작성
- [ ] 강의 복습 및 정리
[ 0 ] 의미기반 언어 지식 표현 체계 이론- [ ] 문맥기반 언어지식 표현 체계 이론
의미기반 언어 지식 표현 체계 이론

Word Embeddings
- Count-based methods : Count vector, TF-IDF. 의미 정보, 순서 정보 고려 X.
- Prediction-based methods : Neural Net 기반, 주변 단어로부터 타겟 단어 예측.
Word2Vec, FastText, Neural Probabilistic Language Models - Others : Glove(Global vectors for word representation)
Count-based methods 외의 Word Embeddings
- 고정된 길이의 dense vector로 단어를 표현. 의미적, 문법적 특성을 수치로 표현. 단어 간 유사도 포착 가능.
- 분포가설(Distribution Hypothesis)기반 : 단어가 나타나는 주변 맥락이 유사하면, 그 단어들의 뜻도 서로 비슷함
문장 입력 → 각 단어를 vocabulary에서 조회 → 단어의 고유 인덱스 → 단어에 해당하는 dense vector 호출
word embedding 3대장 : Word2Vec, Glove, FastText
Word2Vec
- Neural Net 기반, Prediction-based
- 학습방법에 따라 CBow, Skip-Gram
- 단어 주변 정보만 활용
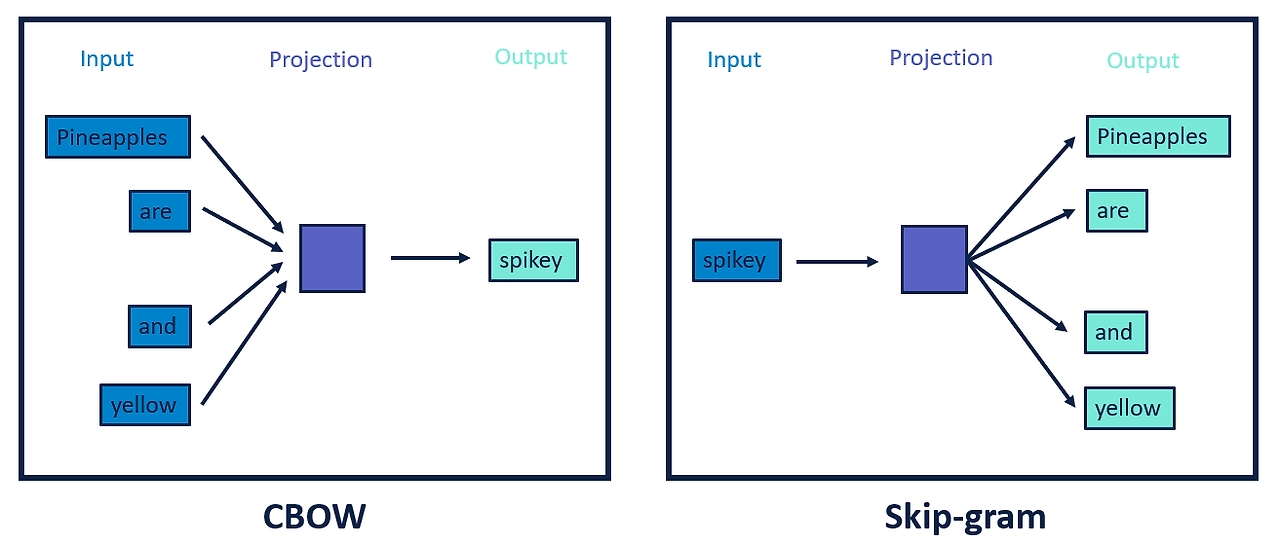
- CBoW (Continuous Bag of Words) - 주변 단어의 맥락을 통해 중심 단어 예측

- Skip-Gram - 중심 단어로부터 주변 단어들을 예측

Glove
공존 행렬 (Co-occurrence Matrix) 기반
단어 간 유사성과 차이를 벡터 공간에 인코딩, 코퍼스 전체 통계 정보를 바탕으로 단어벡터 학습
Co-occurrence Probability

Glove 손실함수 - 희귀 단어 쌍에 대한 영향 ↓, 자주 등장하는 단어 쌍에 대한 영향 ↑

https://nlp.stanford.edu/pubs/glove.pdf
V : vocab 크기
Xij : 전체 코퍼스에서 공존행렬
f(Xij) : 가중치 함수

GloVe는 학습 ↑ Accuracy ↑, word2vec(CBoW, Skip-gram)은 과적합됨
FastText
- Prediction-based
- 단어를 n-gram의 subword로 분해한 정보를 포함 → 형태학적 특성 학습
- word2vec의 확장, robustness 강화
(word2vec의 Out of Vocabulary 문제와 형태학적 유연성 부족 문제 보완)
1. subword 분해 - n-gram vector들을 합함. (Skip-gram 개선) + hashing으로 메모리 문제 완
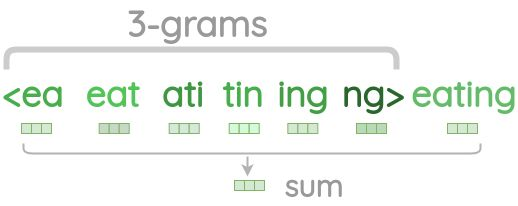
2. Negative Sampling - 임베딩 최적화, 의미가 가까운 벡터는 가까워지도록, 의미가 다른 벡터는 멀어지도록

참고자료 :
1. https://amitness.com/posts/fasttext-embeddings
2. Bojanowski, Piotr, et al. "Enriching word vectors with subword information."
https://arxiv.org/pdf/1607.04606
기타 임베딩 방법
- Doc2Vec - 문서 전체 의미공간에 표현, doc ID 추가 (word2vec은 문장, 문단, 문서 단위 반영 힘듦)
- CoVe (Contextualized Word Vectors) - 동적 임베딩을 얻기 위해 번역 모델 이용, 문맥 반영.
(번역 데이터셋 필요. 번역 데이터셋 = labeled data ∴ supervised learning)
문맥기반 언어지식 표현 체계 이론 (Contextual LM : ELMo, GPT-1, BERT)
의미기반 임베딩 : 문맥정보가 없어 다의어 반영 X
ELMo
- Bi-LSTM 기반 동적 임베딩
- Pre-trained Word Representation 을 얻기 위해 만들어진 사전학습 모델
- unsupervised (∴ 훨씬 유용!)
GPT-1 (Decoder only)
- unlabeled text corpora
- Causal Language Modeling, Auto-regressive, unidirectional
- 문장의 이전 단어들을 기반으로 다음 단어 예측
- task별로 model 구조 수정해 fine-tuning (i.e. model과 task가 일대일 매칭)
BERT (Encoder only)
- unlabeled text corpora
- MLM + NSP (MLM으로 인해 contextual LM의 특성을 갖게 됨)
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day118] LM to LLM (0) | 2024.06.03 |
|---|---|
| Upstage AI Lab 2기 [Day117] Data-Centric AI (0) | 2024.05.31 |
| Upstage AI Lab 2기 [Day116] LM to LLM (1) | 2024.05.30 |
| Upstage AI Lab 2기 [Day109] NLP 경진대회 - LoRA 공부 (0) | 2024.05.21 |
| Upstage AI Lab 2기 [Day102] NLP - Next Encoder Model (0) | 2024.05.09 |



