Upstage AI Lab 2기
2024년 6월 3일 (월) Day_118
Multilingual LLM
1. Multilingual Pre-trained Model
low resource language에 대한 기술적 차별 ↓
(1) mBERT (Multilingual BERT)
(2) XLM (Cross-lingual Language Model)
- Translation Language Model

ref:
Lample, Guillaume, and Alexis Conneau. "Cross-lingual language model pretraining."
https://arxiv.org/pdf/1901.07291
(3) MASS (Masked Sequence to Sequence Pre-training) - span masking, BERT의 MLM을 seq2seq로 확장
(4) mBART (Multilingual BART)
- Unseen Language 번역 task에서는 언어 수가 많을수록 성능 ↑
(5) mT5 (Multilingual T5)

2. Multilingual LLMs
(1) PaLM (Pathways Language Model), PaLM2 @ Google - BARD 기반 LLM, Decoder-only
(2) LLaMA (Large Language Model Meta AI), LLaMA2 @ Meta
(3) Alpaca @ Stanford - LLaMA1을 Instruction Tuning
(4) Falcon
(5) Red Pajama
(6) PolyLM
(7) BLOOM - Decoder-only
(8) GPT-3.5, GPT-4 @ OpenAI
3. Multilingual LLM Benchmark
(1) LASER (Language-Agnostic SEntence Representation, 2019), LASER2 (2020) @ MetaAI - embedding
(2) Flores (2019), Flores-101 (2021, 최초의 many-to-many eval dataset), Flores-200 (2022) @ MetaAI
(3) WikiMatrix (2019) @ Meta
(4) CCMatrix (2020) @ Meta - language pair
(5) NLLB 200 (No Language Left Behind, 2022) @ Meta
(6) MEGA (Multilingual Evaluation of Generative AI) - 다국어 평가데이터셋
(7) Open Multilingual LLM Evaluation Leaderboard (https://huggingface.co/spaces/uonlp/open_multilingual_llm_leaderboard)
Multimodal LLM
1. Multimodal PLMs
- Image-Text
배경지식
coarse-grained classification - 대분류 / fine-grained classification - 소분류
ViT (Vision Transformer) - BERT의 [CLS] 토큰처럼 class token을 추가
(1) CLIP (Contrastive Language-Image Pre-training)
기존의 ViT, ResNet 등은 zero-shot 불가, fine-tuning 필수
idea : 이미지와 이미지를 설명하는 텍스트를 align 해서 학습하면 사전학습 없이도 사용 가능하지 않을까?
→ Image와 Text의 공통된 Multi-modal Embedding Space를 학습
Contrastive Pre-training : Jointly learn image and text
- text encoder : GPT-2
- image encoder : ViT
positive pair의 cosine similarity 최대화, negative pair의 cosine similarity 최소화
문제 : fine-grained classification은 잘 하는데 coarse-grained classification에 약함

ref:
1. Radford, Alec, et al. "Learning transferable visual models from natural language supervision."
https://arxiv.org/pdf/2103.00020
(2) FILIP (Fine-grained Interactive Language-Image Pre-training)
CLIP을 개선 (CLIP은 image와 caption의 일대일 매칭)
image → patches, caption → tokens ∴ patch와 token 사이의 contrastive learning
Loss : text-to-image contrastive learning loss, image-to-text contrastive learning loss

ref:
1. Yao, Lewei, et al. "Filip: Fine-grained interactive language-image pre-training."
https://arxiv.org/pdf/2111.07783
(3) BLIP
웹 데이터의 noise를 줄이기 위해 CapFlit 구조 사용
CapFlit : 사람이 제작한 이미지-텍스트 쌍으로 seq2seq 학습 → 새 caption 생성
- text encoder : pretrained BERT
- image encoder : ViT
Loss : ① Image-Text Contrastive Loss ② Language Modeling Loss ③ Image-Text Matching Loss
- Audio-Text
(1) Whisper
- transformer 구조
- multitask training supervised data (intentionally add noise for robustness)
- multitask training format : <|transcribe|>, <|translate|> tokens to idendifiy 전사, 번역, 화자구분 등
- time-aligned sequecne data 생성
- multitask training format = labaels, 음성 스펙트럼 = input
note : 음석인식 품질 지표 : Word Error Rate
- Video-Text
(1) VideoCLIP
- text encoder : S3D & 6 layers of BERT
- image encoder : BERT
두 인코더 사이의 contrastive learning
2. Multimodal LLMs
- Image-Text
(1) Flamingo
대량의 데이터 & Few Shot
- Language Model : pretrained LLM (Chinchilla 60B)
- image encoder : pretrained image encoder of CLIP
- perceiver resampler : image-text를 cross attetion으로 embedding의 크기를 맞춰줌
query = text, key&value = image
(2) BLIP-2
freeze image encoder and text encoder

두 모델의 representation을 사상하는 Q-Former를 학습.
Q-Former 와 fully connected layer 만 학습함.
(3) LLaVA (Language and Vision Assistant)
- Language Model : pretrained LLM
- image encoder : pretrained image encoder of CLIP
- instruction 생성에 초점
- projection layer 만 학습
- conversation, description, reasoning을 잘 함
- Image/Video/Audio/Text Multimodal
(1) Gemini
Cross-Lingual LLMs
1. Transfer Learning
|- Instruction Tuning
|- Further Pre-training
|- Vocabulary extension
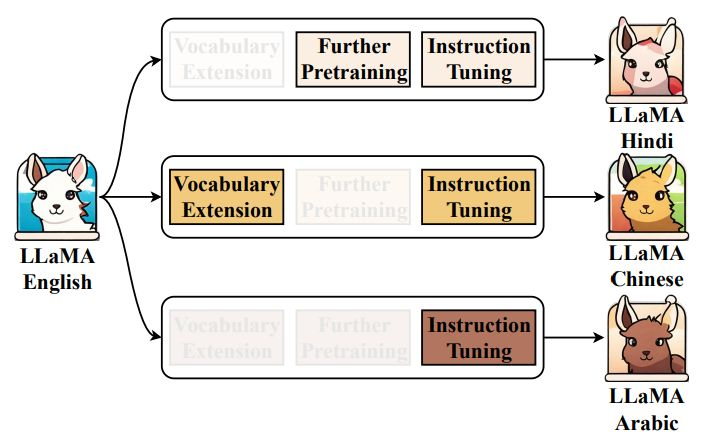
2. 모델 및 임베딩 학습 기반 방법
- AMM (Adapting Monolingual Model)
- 토큰 임베딩만 타겟 언어에 맞도록 무작위 초기화
- XPT (Cross -lingual Post-Training)
phase 1 : 언어적 차이 이해, 하나의 adapter layer 를 추가
phase 2 : full fine-tuining
- GPT-recycle
작 학습된 다른 언어모델이 엠베딩을 사용. 차원을 맞추는 과정 필요.
3. 임베딩 정렬 기반 학습
(무작위 초기 정렬 대신) - 소스 언어와 목표 언어간 토큰 유사도를 기반으로 초기 정렬
WECHSEL
4. Adapter 기반 학습 - LoRA, QLoRA 등
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day126] Information Retrieval (3) 신경망 기본 정보 추출 (0) | 2024.06.14 |
|---|---|
| Upstage AI Lab 2기 [Day125] Information Retrieval (1) (1) | 2024.06.14 |
| Upstage AI Lab 2기 [Day117] Data-Centric AI (0) | 2024.05.31 |
| Upstage AI Lab 2기 [Day117] LM to LLM (0) | 2024.05.30 |
| Upstage AI Lab 2기 [Day116] LM to LLM (1) | 2024.05.30 |



