Upstage AI Lab 2기
2024년 6월 13일 (목) Day_125
검색엔진 발전과정
문제정의 : 텍스트 문서 집합 (비정형) → 질의 → 적합한 문서 추출 및 랭킹
방대한 양 & 속도 & 적합도
검색엔진에 필요한 데이터 구조와 알고리즘
1. 역색인 (Inverted Index) - {key : 단어, value : 문서}, 추출된 문서에 대해서는 우선순위(ranking) 필요
2. Ranking Algorithm
- 질의와 문서의 유사도 : TF-IDF, BM25 등
- 문서 자체의 품질 : Page Rank, Spam Score, Recency(시의성) 등
- (Implicit) Relevance Feedback - 서비스 중에 사용자의 선호도를 implicitly 반영
도전과제 : ① 지속적 최적화 비용 (언어, 관심사 등 변화함) ② 키워드 매칭의 한계 극복
기존 - 키워드 매칭
After Neural Network : Embedding을 통한 유사도 계산 (vector similarity)
질의가 길어질수록 키워드 매칭만으로는 한계가 있고, vector similarity는 계산 비용 이슈가 있음
ANN & Vector DB
ANN (Approximate Nearest Neighbor) : Nearest Neighbor 중에서만 검색, 정확도 ↓, 계산 비용 ↓
예) Elasticsearch, Faiss, milvus, Pinecone 등
검색엔진 랭킹 모델링
1. Inverted Index
{key : 단어, value : 문서}
Text extraction
↓
Tokenization
↓
Stop-word removal
↓
Normalization …… Lemmatization, Stemming
↓
Inverted Index
2. Query-Document Relevance
Retrieval
- Boolean Model
- Vector Space Model : TF-IDF
- Probabilistic Model
- Binary Independence Model (BIM)
- BIM extensions : Two Poisson, BM 11, BM25

Document Quality
- Page Rank
- Recency
- Spam score
(Implicit) Relevance Feedback
한계점 : 단어의 통계 정보만을 이용함
3. Evaluation Metric
Evaluation Metric of Ranking Model
Information Retrieval 에서는 recall은 큰 의미가 없음
1. Precision @ k
2. F1-score
3. Average Precision (Precision-recall curve의 아래쪽 면적)
주요 Information Retrieval Evaluation Metric
1. MRR (Mean Reciprocal Rank)
관련 있는 문서가 몇번째에 있는지 (가장 첫번째 relevant 문서만 고려함)
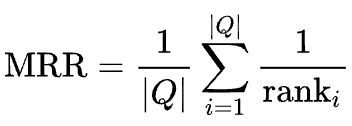
2. MAP (Mean Average Precision)
질의 N개에 대한 AP 평균, 적합한 문서가 다수일 때
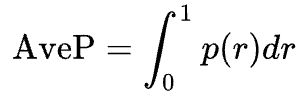
3. NDCG (Normalized Discounted Cumulative Gain)
순위에 따른 가중치 값이 다름
- CG (Cumulative Gain) : 순위에 있는 문서들의 연관도 합
- DCG (Discounted Cumulative Gain)
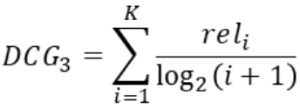
- IDCG (Ideal DCG)

- NDCG = DCG / IDCG
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day126] Information Retrieval (4) ANN (0) | 2024.06.14 |
|---|---|
| Upstage AI Lab 2기 [Day126] Information Retrieval (3) 신경망 기본 정보 추출 (0) | 2024.06.14 |
| Upstage AI Lab 2기 [Day118] LM to LLM (0) | 2024.06.03 |
| Upstage AI Lab 2기 [Day117] Data-Centric AI (0) | 2024.05.31 |
| Upstage AI Lab 2기 [Day117] LM to LLM (0) | 2024.05.30 |



