Upstage AI Lab 2기
2024년 6월 14일 (금) Day_126
Embedding 생성과 ANN
ANN 알고리즘 (Approximate Nearest Neighbor)
1. LSH (Loclity Sensitive Hashing) - 여러 벡터를 하나의 버켓으로 군집화
2. Tree/Space Partitioning - ANNOY : vectorspace → subspace로 분할, 트리에 저장
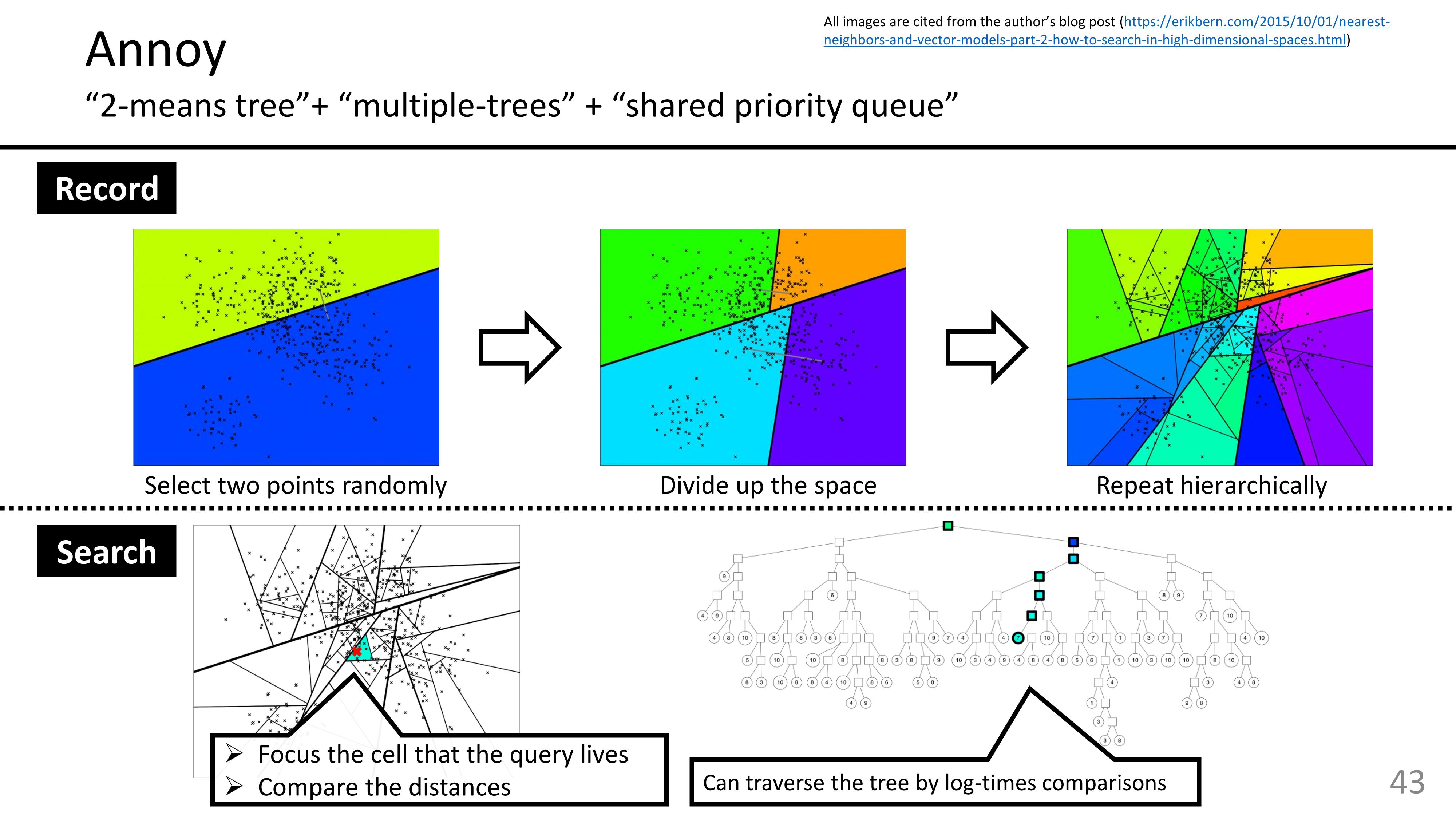
ref:
https://speakerdeck.com/matsui_528/cvpr20-tutorial-billion-scale-approximate-nearest-neighbor-search
3. Graph-based Methods
- NSW (Navigable Small World Graphs)
문서 데이터를 graph에 저장, graph-traversal을 통해 가장 가까운 노드 찾기
embedding도 node와 edge로 표현할 수 있다는 idea에 착안. but! edge가 너무 많으면 비효율적
- Hierarchical NSW : edge 길이별로 계층을 나눔. 가장 긴 edge부터 탐색, 검색 복잡도를 줄임
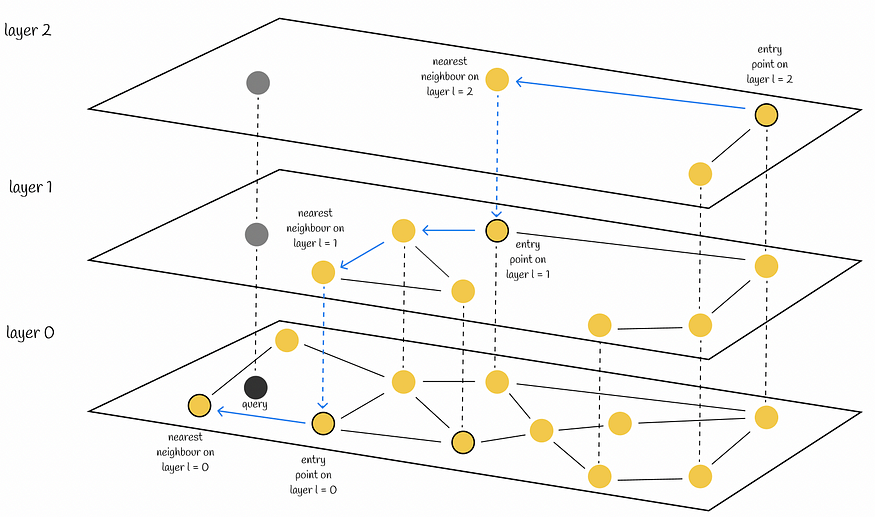
ref:
4. Inverted File Index
K-means Algorithm + Vector Quantization
query 벡터가 클러스터 엣지 근처에 위치할 경우 성능상 문제 발생 → 주변의 여러 클러스터를 포함해서 검색
상용 Vector DB 비교 분석
유사도 기반 검색, 효율적인 데이터 관리
색인(Indexing) : 인코더를 직접 제공하지는 않음. ANN 알고리즘 사용
검색 : 유사도 계산시 ANN 알고리즘 사용.
Elasticsearch, Faiss, Pinecone
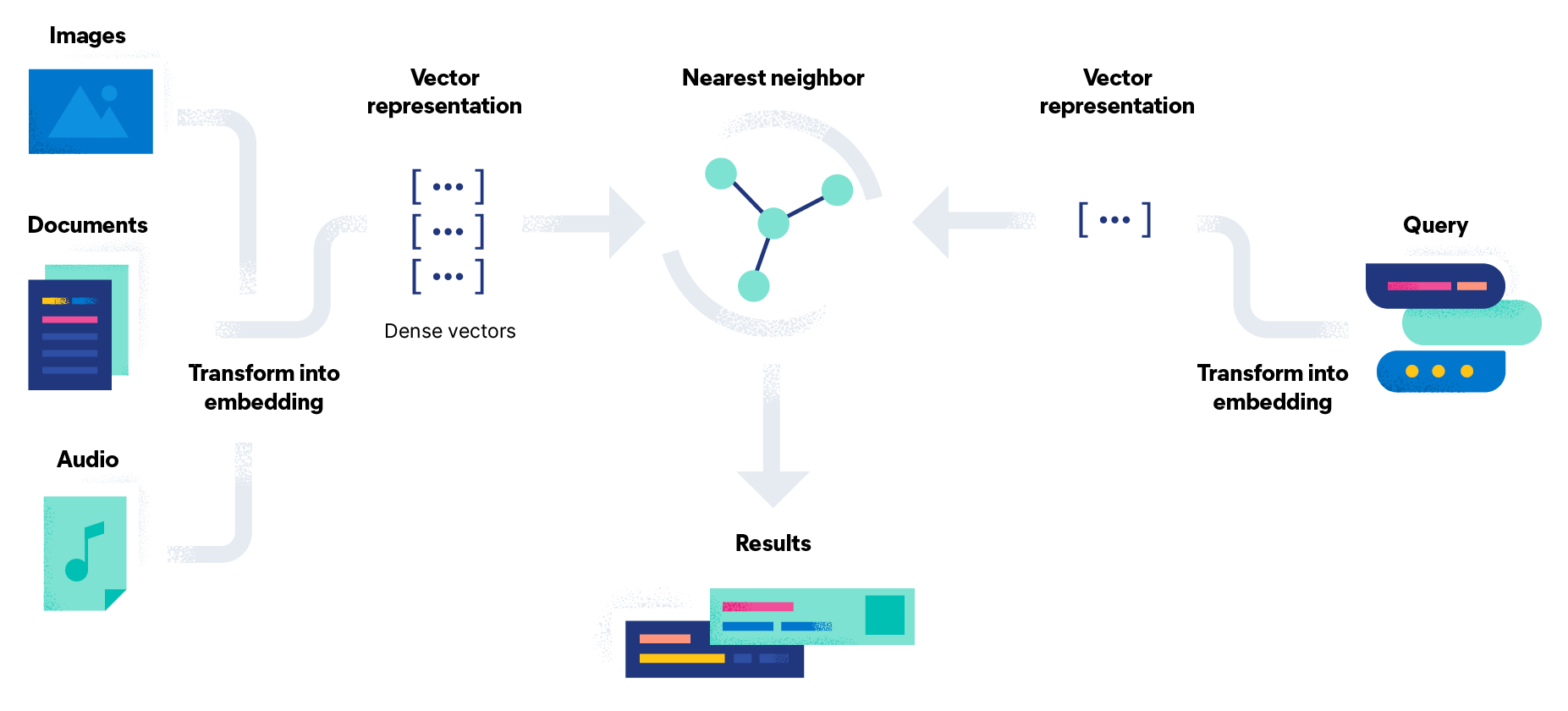
ref:
https://www.elastic.co/what-is/vector-search/
실습 - Elasticsearch
(한글 형태소 분석기는 vector 유사도 기반과 비교하기 위함)
sparse retrieve : 기존 역색인
dense retrieve : embedding을 이용. 너무 긴 text는 embedding 생성시 효과가 떨어질 수 있음
vector 유사도는 오탈자에 대해서도 강건함
실습 - Faiss : 특정 embedding field 하나만 저장
Faiss 는 CPU 버전과 GPU 버전이 있음
문서 전체를 색인하는 방식이 아니라 embedding만 색인. return 값인 offset 사용해서 색인해야 함.
실습 - Pinecone
임베딩 이외의 필드를 딕셔너리 포맷으로 같이 넣어줄 수 있음.
문서를 namespace 로 나눠서 저장 가능
ColBERT
벡터 인코딩이지만 Bi-encoder와 다름
Cross-encoder : 성능 good, 속도 bad
Bi-encoder : 속도 good, 성능 bad
질의, 문서 각각 임베딩 but 모든 토큰을 이용해서 유사도 계산
차원 축소에 따른 성능 폭이 크진 않음
Poly-Encoder - 미리 임베딩해둬서 연산을 줄임
Late Interaction
유사도 계산 방식 : query-document pair에 대해 같은 파라미터를 가지는 BERT 모델로 토큰 레벨 임베딩해 MaxSim 계산

query 개수에 대해 평균
Token Level Soft Interaction - TF-IDF 와 유사
triplet 활용, positive, negative에 대해 softmax cross-entropy loss 계산
결국 학습 데이터 구축이 문제
weak supervision - iteratively - 처음부터 고품질 데이터 구축은 어렵다.
LLM 어플리케이션 구현
고성능의 어플리케이션
JSON mode, function calling
JSON mode : prompting 에 JSON 명시 또는 JSON mode 사용
response-format = {"type" : "json-object"}
+ description에도 JSON으로 추력하라 명시
OpenAI API function calling
tools 에 사용할 함수들의 명세를 작성
JSON 출력 → parsing에 용이
function calling 더 다양하게 활용 가능
ref :
https://web.stanford.edu/class/cs224u/slides/cs224u-neuralir-2023-handout.pdf
ref :
https://matsui528.github.io/cvpr2020_tutorial_retrieval/
https://www.pinecone.io/learn/series/faiss/vector-indexes/
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day126] Information Retrieval (3) 신경망 기본 정보 추출 (0) | 2024.06.14 |
|---|---|
| Upstage AI Lab 2기 [Day125] Information Retrieval (1) (1) | 2024.06.14 |
| Upstage AI Lab 2기 [Day118] LM to LLM (0) | 2024.06.03 |
| Upstage AI Lab 2기 [Day117] Data-Centric AI (0) | 2024.05.31 |
| Upstage AI Lab 2기 [Day117] LM to LLM (0) | 2024.05.30 |



