Upstage AI Lab 2기
2024년 5월 31일 (금) Day_117
[Data-Centric AI] (1-1) Data-Centric AI란
AI System = Code + Data

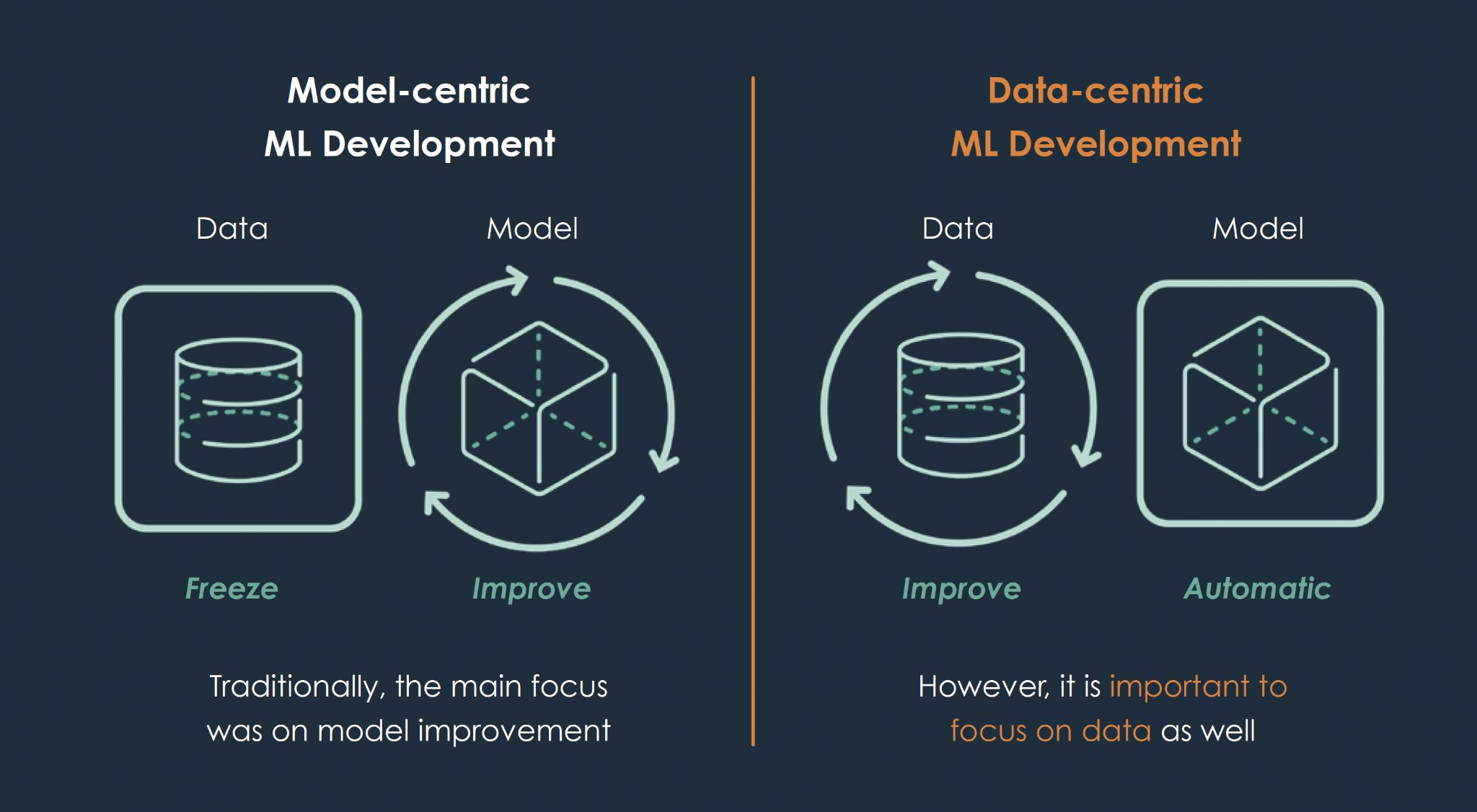
Model-Centric AI : 모델 중심 접근 방식
- 최대한 많은 데이터 확보하여 raw data의 noise 조차도 무시할 수 있도록
- freeze data, improve algorithm/model
Data-Centric AI : 데이터 중심 접근 방식
- freeze model, improve data
AI 서비스 개발과정
Project Setup → Data Preparation → Model Training → Deploying
After Deployment : 장비사양이 결정된 상황 → Data Centric이 조금 더 중요해짐 ∴ 데이터 품질 중요성 부가되기 시작
MLOps : 데이터셋 구축을 위한 인프라를 만들어 데이터를 체계적이고 효율적으로 관리할 수 있도록 자동화된 시스템

Data-Centric AI가 산업에 미친 영향
LLM의 시대 - 빅테크만 개발 가능
일반기업, 개인, 연구자들 - Fine-tuning → 많은 데이터 필요 X, 소량의 고품질 데이터
Fine-tuning의 현주소 : LoRA
사전학습 모델 완전히 고정 + low rank query-value attention matrix 추가
low rank query-value attention matrix 만 학습시킴

LLM의 시대
- Prompt engineering 강조
- In-Context Learning : 이전에 배운 정보, 컨텍스트 활용
GPT-3를 통해 알게 된 사실
- 입력값에 지시문을 포함시키면 그에 맞는 결과를 준다.
- 큰 LLM일수록 좋은 성과 + 일정수준 이상에서는 fine-tuning보다 나은 결과
- 의의 : prompt engineering 만으로도 fine-tuning을 능가할 가능성
- 단점 : input에 더 많은 토큰 입력 → inference 비용 ↑
- prompt engineering 비용과 fine-tuning 비용 비교하여 선택 필
- 지시가 구체적일수록 의도에 가까운 결과를 준다. → 다양한 목적에 맞는 프롬프트 템플릿이 공유되고 있음.
Data-Centric AI 관련 연구
Data-Centric AI (DCAI) @ NeurIPS2021 (Andrew Ng)
DMLR @ ICML'23 (Data-centric Machine Learning Research Workshop at ICML 2023) - Prompting for Small Dataset
Data-Centric AI 관련 태스크
- 이상 탐지 및 제거 (Anomaly Detection & Removal)
- 오류 감지 및 수정 (Error Detection & Correction)
- 데이터 증강 (Data Augmentation)
- 피쳐 엔지니어링 (Feature Engineering)
- 컨센서스 라벨링 (Consensus Labeling)
- 액티브 러닝 (Active Learning)
- 커리큘럼 학습 (Curriculum Learning)
[Data-Centric AI] (1-2) Data-Centric AI의 미래
keywords : multilingual, multimodal, synthetic data
Foundation model의 시대 : pretrained with unlabeled data, Foundation model에 필요한 데이터에 집중

keyword 1 : Multilingual
before transformer : unilingual LM
after transformer : unilingual for specific task(e.g. KoBERT)
after LLM : multilingual
Multilingual Data
- MLQA(MultiLingual Question Answering)
- Multilingual LibriSpeech
- GEM Benchmark
Multilingual Model
- BLOOM @ BigScience
- PaLM2 @ Google
- MMS(Massively Multilingual Speech) @ Meta
keyword 2 : Multimodal
LMM(Large Multimodal Model)
Multimodal Data
- VQA (Visual Question Answering)
- VidLN (Video Localized Narratives)
- VDialogUE - 5 tasks, 6 datasets
Multimodal Model
- GPT-4 @ OpenAI
- PaLM-E @ Google
- KOSMOS-2 @ Microsoft - <image>, <grounding>, <loc>
keyword 3 : Synthetic Data
합성데이터 예) 자율주행 시뮬레이션, VQA 데이터 생성, 오디오 데이터 생

[Data-Centric AI] (2-1) 데이터 구축 프로세스 소개
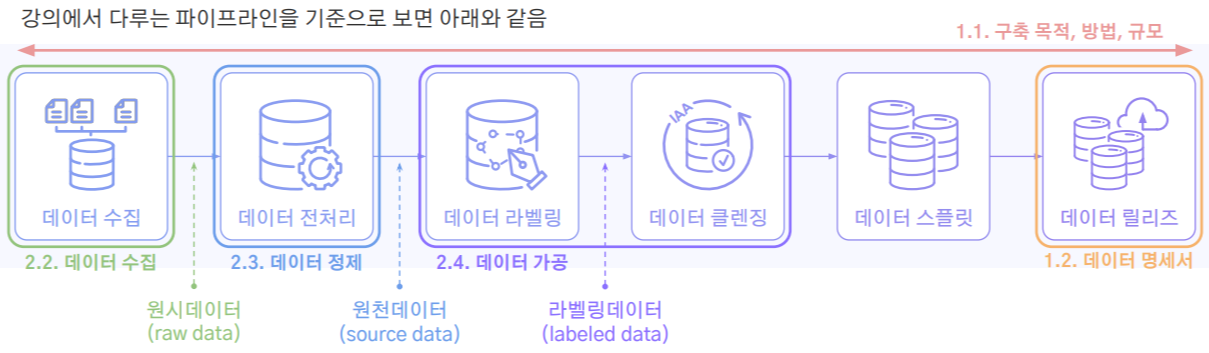
데이터 구축 파이프라인 6단계

데이터 용어
- 원시 데이터 (raw data) : 데이터 수집 후, 데이터 전처리 전
- 원천 데이터 (source data) : 데이터 전처리 후, 데이터 라벨링 전
- 라벨링 데이터 (labeled data) : 데이터 라벨링 후
데이터 구축 파이프라인
- 데이터 수집
- 데이터 수집 방법 : 직접수집, 크롤링, 오픈소스, 크라우드 소싱
- 데이터 타당성 검토 : 저작권, 개인정보, 데이터 다양성 확보, 데이터 편향 방지 및 윤리 준수, 사실적 획득/수집 환경 구성, 법·제도 준수
참고자료 : https://www.aihub.or.kr/aihubnews/qlityguidance/view.do?currMenu=131&topMenu=103&nttSn=10125
- 데이터 전처리 : 데이터 품질 확보, 데이터 스키마 설계

[Data-Centric AI] (2-1) 데이터 구축 프로세스 소개 강의자료 중 - 데이터 라벨링 : Quality Control, Efficiency, Scalability
- 데이터 클렌징 : 데이터 내재적/외재적 요소 검수
- 내재적 : Inter Annotator Agreement
- 외재적 : IRB(기관생명윤리위원회, Institutional Review Board), TTA (한국정보통신기술협회, Telecommunications Technology Association)
- 데이터 스플릿 : train, valid, test split
- 데이터 릴리즈
데이터 구축 사이클
 |
 |
[Data-Centric AI] (2-2) 데이터 구축 기획서 작성
명확한 방향 설정, 리소스 및 일정 관리, 품질 관리, 갈등 방지
AI Hub의 '인공지능 학습용 데이터 구축 지원사업' 데이터 구축 기획서
- 1. 구축 계획 수립 ( = 요약 )
1.1. 구축 목적, 방법, 규모
1.2. 데이터 명세서
2023년도 인공지능 학습용 데이터 구축 지원사업 공고 - [붙임 1] 인공지능 학습용 데이터 구축 계획서 - 데이터 구축
2.1. 개요
2.2. 데이터 수집
2.3. 데이터 정제 ( = 전처리 )
2.4. 데이터 가공 ( = 라벨링 )
2.5. 학습모델 적용 방안
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day125] Information Retrieval (1) (1) | 2024.06.14 |
|---|---|
| Upstage AI Lab 2기 [Day118] LM to LLM (0) | 2024.06.03 |
| Upstage AI Lab 2기 [Day117] LM to LLM (0) | 2024.05.30 |
| Upstage AI Lab 2기 [Day116] LM to LLM (1) | 2024.05.30 |
| Upstage AI Lab 2기 [Day109] NLP 경진대회 - LoRA 공부 (0) | 2024.05.21 |



