Upstage AI Lab은 크게 두 단계로 나뉘는데, 초반은 패스트캠퍼스 과정, 두번째는 Upstage 과정이다.
2월 27일부터 시작된 Upstage 과정은 ML Advanced, Image Classification, NLP, 그리고 선택주제로 진행되는 AI실전대회까지 총 4번의 경진대회를 진행하게 된다.
그 중 첫번째인 ML Advanced 경진대회가 진행되었다.
# 01. 프로젝트 소개 : House Price Prediction
Task : 서울시 아파트 실거래가 예측 (Regression)
Evaluation Metric : RMSE (Root Mean Squared Error)
프로젝트 기간 : 2024년 3월 20일 (10am) - 2024년 4월 2일 (1pm)
Given Dataset : 국토교통부 실거래가, 서울시 공공주택 아파트 정보
- Train Data : 2007-01-01 ~ 2023-06-30, size (1188822, 52)
- Test Data : 2023-07-01 ~ 2023-09-26, size (9272, 51)
본 경진대회는 기본적으로 베이스코드가 주어졌기 때문에 이를 바탕으로 빠르게 여러가지 실험을 수행해볼 수 있었다. kaggle 경진대회들도 다양한 사람들이 starter code들을 공유해주는데, 입문자에게는 이런 코드들을 필사하는 것 만으로도 큰 도움이 되고, 주어진 짧은 경진대회 기간 안에 다양한 실험들을 해볼 수 있다는 장점이 있다. 이러한 공유의 문화가 개인적으로 너무 즐겁다. 이어서 설명하기도 하겠지만 실제로 우리 팀도 각자 아는 것들을 주고받으며 지식의 티키타카가 생겼고 그 과정이 너무 재밌었기 때문이다.
우리 팀은 EDA, extra data search, feature engineering, modeling이 순환적으로 이뤄졌고 마지막에 '진짜' Outlier들을 탐색해내는 방법으로 성능을 향상시켰다. 아래 표는 내가 제출했던 prediction 중 의미가 있었던 제출을 중심으로 정리해보았다.
| Given baseline | Submission #1 |
Submission #2 |
Submission #3 |
팀 최종 제출 | ||
| Public | 47133.7121 | 23750.1248 | 22665.8725 | 17642.1889 | 15070.6662 | 14691.1409 |
| Private | 34223.5885 | 19159.6049 | 14979.0390 | 12607.6082 | 12614.1573 | 12994.2534 |
| Date | - | 2024-03-22 18:22 |
2024-03-27 10:54 |
2024-03-28 18:14 |
2024-04-02 11:32 |
2024-04-02 11:59 |
# 02. Submissions
- Submission #1 (2024-03-22 18:22)
- (Baseline 47133.7121) → Public LB 23750.1248 -> Private LB 19159.6049
- 확실하게 불필요한 컬럼 우선 제거, 구에 대한 encoding 방식 변경, 파생변수 추가 (is_public, yrs_diff_built_contract, built_in3yrs, built_in5yrs, built_over30yrs)
Step 1. 1st level EDA
Part 1. k- 로 시작하는 컬럼들에 대한 가설 검증

컬럼별 결측 비율을 봤을때, k-로 시작하는 컬럼들이 비슷한 비율의 높은 결측치를 가진다. 데이터 출처 중 서울시 공공주택 아파트 정보 데이터가 있었기 때문에 k-로 시작하는 컬럼들은 이 데이터로부터 머지된 정보일 것으로 판단, 공공주택이 아닌 아파트들에 대해서는 결측치가 생긴 것이라는 가설을 세웠다.
가설 확인을 위해 결측 비율이 일정한 컬럼들 중에서 임의로 한 개의 컬럼을 선택하여 null여부에 따라 train data를 나누고 k 컬럼들에 대한 결측치를 비교했다. (이 과정에서 가설과 달랐다면 다른 컬럼을 선택해서 다시 분석할 계획이었다.)
dt["k-전용면적별세대현황(60㎡이하)"].isnull().sum()
# 869608
dt["k-전용면적별세대현황(60㎡이하)"].notnull().sum()
# 249214
k_rel_cols = ['k-단지분류(아파트,주상복합등등)', 'k-전화번호', 'k-팩스번호', '단지소개기존clob', 'k-세대타입(분양형태)', 'k-관리방식', 'k-복도유형',
'k-난방방식', 'k-전체동수', 'k-전체세대수', 'k-건설사(시공사)', 'k-시행사', 'k-사용검사일-사용승인일', 'k-연면적', 'k-주거전용면적', 'k-관리비부과면적', 'k-전용면적별세대현황(60㎡이하)',
'k-전용면적별세대현황(60㎡~85㎡이하)', 'k-85㎡~135㎡이하', 'k-135㎡초과', 'k-홈페이지', 'k-등록일자', 'k-수정일자']
dt_k_area_isnull = dt[dt['k-전용면적별세대현황(60㎡이하)'].isnull()][k_rel_cols]
dt_k_area_notnull = dt[dt['k-전용면적별세대현황(60㎡이하)'].notnull()][k_rel_cols]
서울시 공공주택 아파트 정보 자체에도 결측은 있을 수 있기 때문에 공공주택이 아닌 dt_k_area_isnull를 우선 검토하였다.
'k-전용면적별세대현황(60㎡이하)' 이 null인 데이터가 869608개, null이 아닌 데이터가 249214개 였다.
dt_k_area_isnull에 대한 notnull().sum() (결측이 아닌 자료들의 개수)을 출력해본 결과 0 또는 45로 일정하였다. 시간관계상 notnull().sum()이 45인 경우에 대해 추가적인 분석을 진행하지는 못 했지만 869608개 중 결측이 아닌 데이터가 45개밖에 안 되는 것이라 활용도가 높지 않은 컬럼으로 판단하였다.
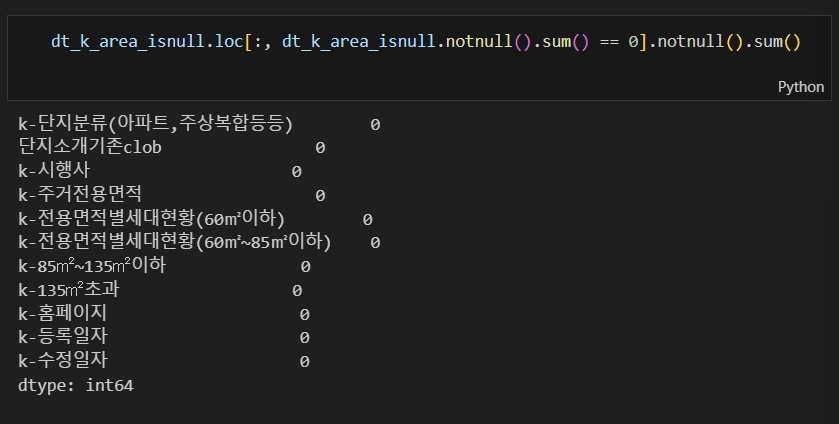 |
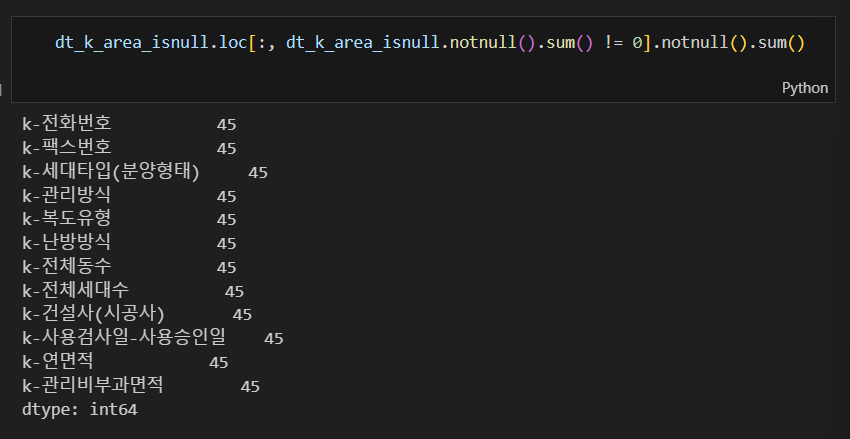 |
이를 바탕으로 dt_k_area_notnull의 isnull.sum()도 출력해보았고, isnull.sum()이 일정하게 0인 컬럼은 아래의 그림과 갔았으며, 나머지는 결측의 비율이 불규칙하게 나타났다.
 |
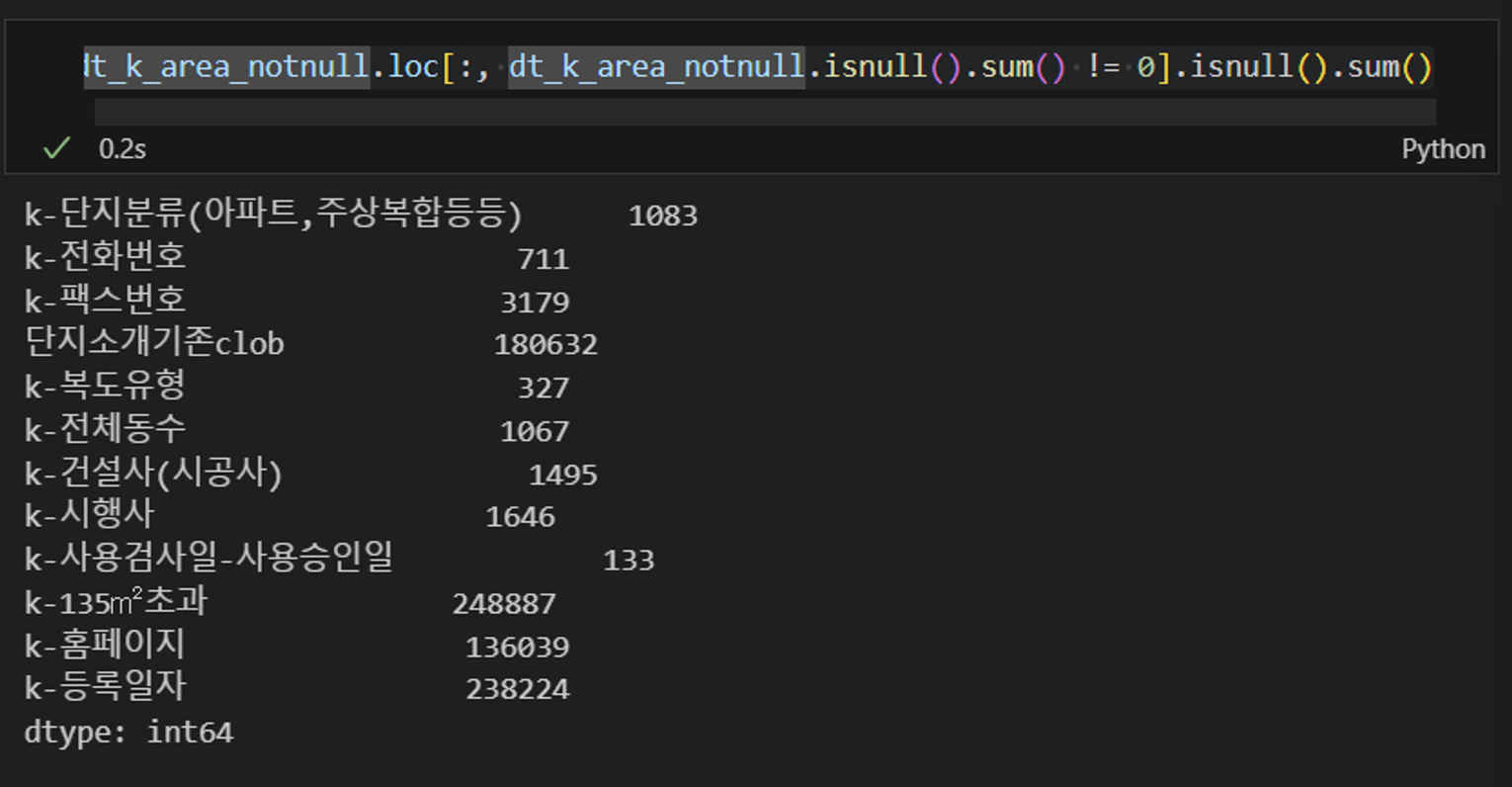 |
cols_to_use = []
for col in dt_k_area_isnull.loc[:, dt_k_area_isnull.notnull().sum() == 0].columns.tolist():
if col in dt_k_area_notnull.loc[:, dt_k_area_notnull.isnull().sum() == 0].columns.tolist():
cols_to_use.append(col)
cols_to_use
['k-주거전용면적', 'k-전용면적별세대현황(60㎡이하)', 'k-전용면적별세대현황(60㎡~85㎡이하)', 'k-85㎡~135㎡이하', 'k-수정일자']
일단은 확실하게 민영주택에 대하여 모두 결측치를 갖고, 공공주택에 대하여 모두 결측이 없는 컬럼들을 우선 선택하여 분석에 사용해보는 방향으로 선택하였고, 공공주택여부를 판단하는 is_public 파생변수를 생성하였다.
dt['is_public'] = dt["k-전용면적별세대현황(60㎡이하)"].notnull()
Part 2. 구별/동별 특성에 대한 분석
Task는 서울시로 한정되기 때문에 구별/동별 특성이 중요하다.

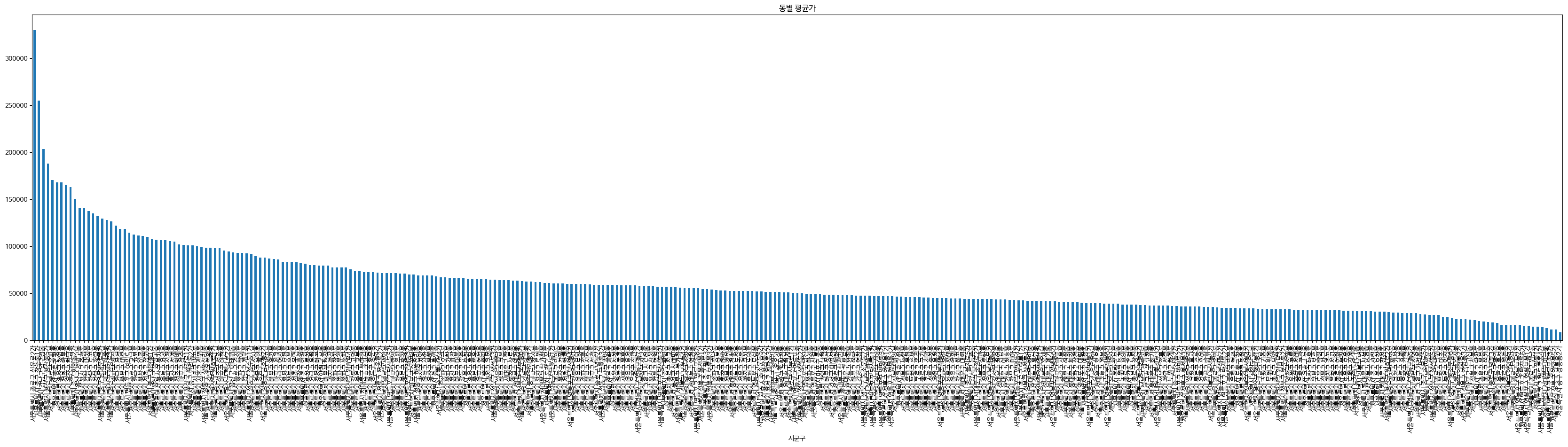


베이스라인에 주어진 IQR을 기준으로 아웃라이어를 다 삭제할 경우 너무 많은 데이터 손실이 있다고 판단하여, 일단 아웃라이어 탐지는 오히려 후순위로 미루었다.
대신 한가지 실험을 해보았는데, 개인적으로 구 정보는 범주형 변수는 맞지만 명목형이 아닌 ordinal 변수라고 생각하였다. 따라서 일반적인 label encoding 대신 구별 평균가의 순서 자체를 구 이름을 encoding하는 실험을 해보았다. 추후 추가된 파생변수들이 있긴 하지만 이 인코딩 방식이 퍼블릭 리더보드 상 47133.7121 → 23750.1248 로 향상되는데 주요한 역할을 한 것으로 판단된다.
district_order = dt.groupby("구")["target"].mean().sort_values(ascending=False).index.tolist()
district_mapping = {district: label for label, district in enumerate(district_order)}
concat_select['구_encoded'] = concat_select["구"].map(district_mapping)
Step 2. 1st level Feature Engineering - 파생변수 생성
건축년도 자체나 계약년도 자제보다도 계약시점에서 아파트의 연한이 중요하기 때문에 'yrs_diff_built_contract' 라는 변수를 생성하였고, 최신 아파트의 기준을 3년으로 잡을지 5년으로 잡을지 실험해보기 위해 'built_in3yrs', 'built_in5yrs' 파생변수를 생성하였다. 또한 재건축이 "가능"해지는 시점은 건축연한 30년이 지나는 시점이기 때문에 이 부근에서 재건축을 앞두고 재건축에 대한 기대감으로 아파트가 상승이 일어나기 때문에 'built_over30yrs' 라는 컬럼 또한 추가하여 실험을 진행하였다.
concat_select['yrs_diff_built_contract'] = concat_select['계약년'] - concat_select['건축년도']
concat_select['built_in3yrs'] = concat_select['yrs_diff_built_contract'].apply(lambda x : 1 if x <= 3 else 0)
concat_select['built_in5yrs'] = concat_select['yrs_diff_built_contract'].apply(lambda x : 1 if x <= 5 else 0)
concat_select['built_over30yrs'] = concat_select['yrs_diff_built_contract'].apply(lambda x : 1 if x >= 30 else 0)

위 그림과 같이 거래시점과 건축년도의 차이가 28년인 지점부터 41년인 지점까지 가파른 상승세를 보이는 것을 알 수 있다.

- Submission #2 (2024-03-27 10:54)
- Public LB 22665.8725 -> Private LB 14979.0390
- 모델 변경 : xgboost, n_estimators 1000
- 동에 대한 encoding 방식 변경, 가격 상승에 더 중요한 지점을 찾기 위해 built_over30yrs 외에도 built_over35yrs, built_over40yrs를 추가, 구와 동 특성 보다 세분화된 분기점을 찾기 위해 on_main_st 파생변수 추가, business district 가 있는 구를 구별하기 위한 has_bds 파생변수 추
- 외부데이터 추가 :
- 학생 1만명단 사설학원수개소
- 구단위 도시계획현황 통계
- 코스피 종가

- Submission #3 (2024-03-28 18:14)
- Public LB 17642.1889 -> Private LB 12607.6082
- 외부데이터 추가 :
- 공시가격, 버스정류장, 역세권
- 실업률
이 지점부터는 다른 팀원들과 작업을 합쳐나가기 시작하였다. 한 팀원은 새로 쓸만한 베이스라인을 주었고, 다른 팀원은 논문 조사로 공시가격 데이터의 유효성을 찾아와 공시가격을 찾을 수 있는 링크를 주었더니 그걸 합치고, API를 이용해 역세권과 버스정류장세권(?) 분석을 진행하여 이를 내 작업과 합치면 공시가격과 역세권 정보만으로 분석하였을 때 보다 더 큰 효과가 나타날 것으로 판단하였다. 실제로 효과가 있었을 뿐 아니라 Private LB가 오픈 되면서 이 모델의 강건함이 더 부각되었다.

하지만 팀 모델에는 내가 feature engineering 하고 외부 데이터로부터 추가한 모든 feature가 하나도 포함되지 못 하였다. 왜냐하면 이 시점에서 리더보드 상 RMSE가 17642.1889 인 내 모델이 팀 내 꼴찌였기 때문이다. ㅠㅠㅠ 따라서 내 가설들은 모두 기각 당하였다. (하지만 Private LB가 오픈되면서 나는 자신감을 되찾았다.)

# 03. 최종 Leaderboard 순위

최종적으로 우리 팀은 Public LB 상 1위, Private LB 상 3위를 기록하였다. 하지만 기록 자체보다도 중요한 건 우리가 이 과정을 진짜 즐겼고 많은 것을 배웠다는 것이라고 나는 생각한다. 정말 재미있는 팀워크였다. 나의 마지막 소감으로 "티키타카란 이런것이구나!"라고 담았을 정도이니까. (비록 Private LB 오픈 후 우리들의 급격한 도파민 드롭이 있었지만 ㅠ)
# 팀플을 마무리하며
(미리 한가지 덧붙이고 시작하자면, 개인적으로 저작권에 굉장히 예민한 편이라 다른 팀원들의 저작물을 본 게시글에 첨부하지는 않았지만 진짜 많은 분석과 논의가 오고 갔다. 물론 팀원들의 양해를 구하고 출처를 밝히고 첨부할 수도 있겠지만 그들의 노력이 이 글에 포함되면서 마치 '내' 작업처럼 오해가 생기는 것이 싫어서 내가 실제로 plot한 것들만 첨부하였다.)
재미있었던 것은 그 수많은 논의 속에서도 각자가 흥미를 가지는 포인트가 다 달랐고, 서로의 의견을 받아들이는 정도도 사람마다 달랐다. 한 사람은 모델링에 집중하였고, 나는 매크로한 분석에 집중하였고, 다른 사람은 논문까지 찾아가며 유용할만한 외부 데이터를 찾았고, 다른 사람은 광기 서린 아웃라이어 찾기를 진행하였다. 그리고 그것들이 다 합쳐져서 위와 같은 결과가 나왔다. 어느 누구도 역할이 없는 사람이 없었으며, 각자 다른 부분의 작업을 진행하며 합쳐 나가는 과정이 재밌었다.
특히 내가 많이 배운 지점은 원래도 내 성격상 같이 공부하는 사람끼리인 이 과정에서 다른 사람이 진행해보고 싶은 것을 막을 권리는 없다고 생각하여 다른 팀원이 계속 접목시킬 외부자료를 찾는 것을 말리지 않았는데 그게 결정적으로 팀의 성과를 높이는데 가장 효과가 있는 자료였고, 덕분에 그 동안 내가 취한 stance에 대한 확신을 얻을 수 있는 중요한 계기가 되었다. (그동안은 좀 더 강하게 의견을 밀어붙이지 못하는 내가 잘못된 것인가에 대한 의문을 가지고 있던 시점이었기 때문이다.)
어쨌든 결과도 좋고, 과정도 즐거웠던 첫번째 스터디 그룹이 이렇게 마무리 되고 우리는 다음 스터디 그룹으로 옮겨졌다. 처음에는 서로 너무 낯설었는데 많이 친해져서 헤어지는 게 아쉬웠다.
'패스트러너 기자단 4기' 카테고리의 다른 글
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #09_멘토링 (0) | 2024.05.10 |
|---|---|
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #08_미니 프로젝트 - Upstage 경진대회 #2 (0) | 2024.04.24 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #05_그룹스터디 (1) 첫번째 그룹세미나 (0) | 2024.03.18 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #04_미니 프로젝트 (3) ML 프로젝트 (0) | 2024.03.03 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #03_2개월차 후기 (0) | 2024.02.10 |



