# 01. 프로젝트 소개
프로젝트 기간 : 2024년 2월 13일 - 2024년 2월 26일
(캐글 대회 기간 : 2024년 2월 6일 - 2024년 5월 28일 )
주제 : Home Credit - Credit Risk Model Stability
(https://www.kaggle.com/competitions/home-credit-credit-risk-model-stability/data)
5년 전에도 Home Credit에서 대회를 진행한 바 있으며, 5년 전보다 무려 10배 더 큰 데이터로 자랑스럽게 돌아온 대회다. ^^


목적 : default prediction (binary classification)
평가 지표 : 자체평가 지표
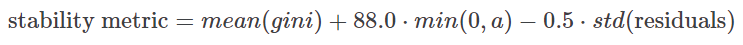

본 대회는 각 WEEK_NUM에 대하여 gini score를 계산하고, WEEK_NUM에 따른 gini score의 linear regression 계수로 falling rate (min(0,a))와 std(residuals)로 페널티항을 포함한 자체지표를 사용하였다. 대회 주최 측에서 이러한 평가지표를 사용한 것은 파산 가능성에 대해 시간이 변해도 안정적으로 예측하는 모델을 원했기 때문이다. 안정성은 본 대회에 굉장히 중요한 키워드였다.
Home Credit
Home Credit은 1997년 체코에서 설립되어 현재 네덜란드에 본사를 두고 6개 국가에서 대출 및 보험 상품을 판매하고 있는 회사다. 일반적으로 대출 상품을 판매하는 회사들이 그렇듯이 정확한 default prediction이 사업 성패에 중요한 영향을 미친다. 하지만 Home Credit 이 일반 대출회사와 다른 것은 Home Credit 홈페이지나 Sustainability report를 읽어보면 알 수 있다.
대회 설명에도 포함되어 있듯이 Home Credit은 신용 정보가 적은 사람들에게 대출을 제공하는 것이 핵심 사업이다. 그렇기 때문에 신용 정보가 부족한 사람에 대한 파산 가능성을 면밀히 검토하여 무분별한 대출을 지양하는 것이 중요하다. 이 부분이 굉장히 중요한 포인트이고 문제 해결에 대해 접근 방식을 가다듬을 수 있는 키 포인트이지 않을까 생각이 들었다. Home Credit이 신용 정보가 부족한 사람들에게 대출을 진행하는 이유는 부족한 신용정보로 인해 제 1 금융권으로부터 대출이 어려운 사람들이 합리적이고 안전하게 대출을 받을 수 있도록 하고, 나아가 이를 바탕으로 규제금융권에 접근할 수 있는 토대를 제공하고자 하는 것이기 때문이다.


문제정의
우리 팀은 데이터 분석 과정에서 주어진 문제에 대한 정의를 구체화시키는 과정을 순환적으로 반복하였는데, 이 과정에서 Home Credit의 핵심가치는 굉장히 중요한 요소였다. 문제 정의는 다음과 같은 순서로 발전되었다.
- 주어진 정보를 바탕으로 default 가능성을 예측한다.
- 문제점 : target이 97 : 3 정도로 굉장히 클래스 임밸런스가 심한 자료이다. 하지만 사업성 측면에서 생각해보면 3~4%의 default를 잘 예측하는 것이 중요하다.
- 어떤 사람들에게 대출을 주면 안 되는 것인가?
- 기본적으로 기존의 신용기록이 나쁜 사람에게는 대출을 해주면 안 되는 것이 맞다.
→ 기본으로 깔고 가야할 전제 조건 - 그러나 신용기록이 없는 사람들 중에서도 default 가능성이 낮은 사람에 대해서는 잘 평가하여 대출 상품을 판매하는 것이 Home Credit의 목표
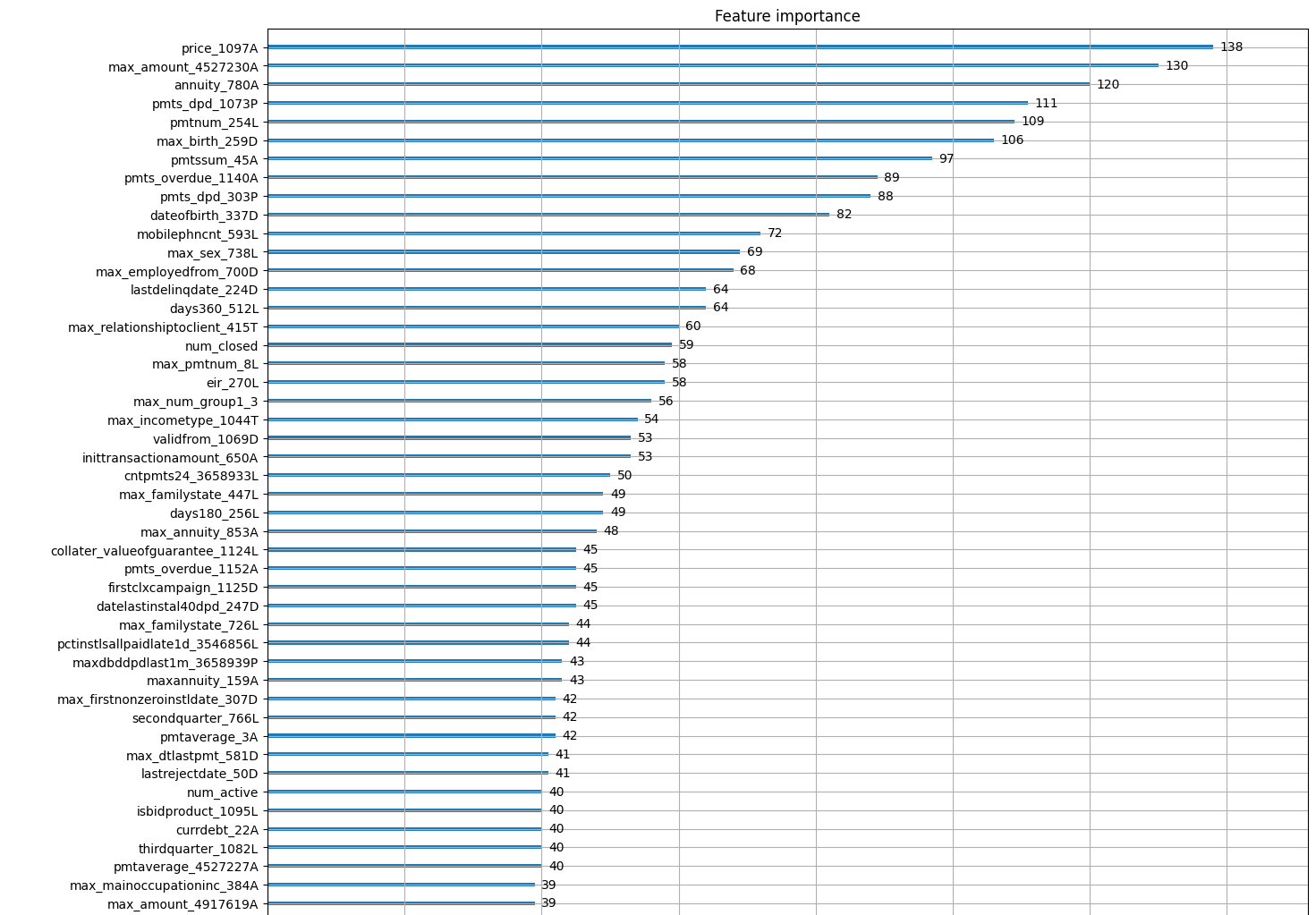
→ 그렇다면 Home Credit이 자체적으로 가공한 depth 0 자료 외에 depth1, depth2로부터 중요한 컬럼을 찾아내야한다. 즉, feature importance를 plot했을 때 depth1, depth2 로부터 새로 aggregate해서 추가한 컬럼들 중 기존 depth0 의 컬럼보다 상위에 찍히는 컬럼이 있는지 확인해보는 것이 중요하다.
- 기본적으로 기존의 신용기록이 나쁜 사람에게는 대출을 해주면 안 되는 것이 맞다.
- 또한 신용 기록이 없는 사람들에 대해 default 가능성에 대한 flag가 될만한 컬럼을 찾는것이 중요하다.
대회 이슈 - Metric Hacking과 그로 인한 대회 중단
대회 초반부터 Metric Hacking이 이슈가 되었고, Metric 자체도 문제였지만 해당 train 기간에 코로나 기간이 포함되어 있어 이에 대한 stability control 이슈가 발생하였다. 결국 캐글 대회가 2주 간 중단되어버리는 사상초유(까지는 아니지만 흔치는 않은)의 사태가 벌어졌다. 데이터 사이즈부터 대회 중단까지.. 여러모로 쉽지 않은 대회였다.

# 02. 데이터 소개
given data (train, test):
| DATA SOURCE | depth=0 | depth=1 | depth=2 |
| internal | static_0 | applprev_1 | applprev_2 |
| person_1 | person_2 | ||
| other_1 | - | ||
| deposit_1 | - | ||
| debitcard_1 | - | ||
| external | static_cb_0 | tax_registry_a/b/c_1 | - |
| credit_bureau_a/b_1 | credit_bureau_a/b_2 |
주어진 데이터의 종류만 해도 16종류였으며, credit_bureau_a_2 와 같이 11개로 나누어져 있는 파일들도 있었다.

위와 같이 나뉘어 있는 파일들은 다 머지한 후 shape을 체크해본 결과 다음과 같았다.
depth = 0
- Base tables : (1526659, 5) - target 0 : 1478665 / target 1 : 47994
- static_0 : (1526659, 168)
- static_cb_0 : (1500476, 53)
depth = 1 ~ 2 internal data
- applprev_1 : (6525979, 41)
- applprev_2 : (14075487, 6)
- person_1 : (2973991, 37)
- person_2 : (1643410, 11)
- other_1 : (51109, 7)
- deposit_1 : (145086, 5)
- debitcard_1 : (157302, 6)
depth = 1 ~ 2 external data
- tax_registry_a_1 : (3275770, 5)
- tax_registry_b_1 : (1107933, 5)
- tax_registry_c_1 : (3343800, 5)
- credit_bureau_a_1 : (15940537, 79)
- credit_bureau_a_2 : (188298452, 19)
- credit_bureau_b_1 : (85791, 45)
- credit_bureau_b_2 : (1286755, 6)
test 데이터로 제공된 데이터는 10개 뿐이었는데 본 대회가 code submission 대회라 test의 개수나 아이디 등은 가려둔 채, 주어진 테스트 파일명을 참고하여 코드를 짜두면 실행하는 과정에서 실제 test data로 대체해서 submission 점수를 채점하는 방식으로 진행되기 때문이었다. stable한 모델에 초점을 두고 있는 대회라 이용자의 정보 노출을 최소화하여 메트릭해킹을 지양하고 싶었던 의도로 파악된다. (하지만 안타깝게도 본 대회는 메트릭 해킹이 너무 큰 이슈가 되어버렸다.)

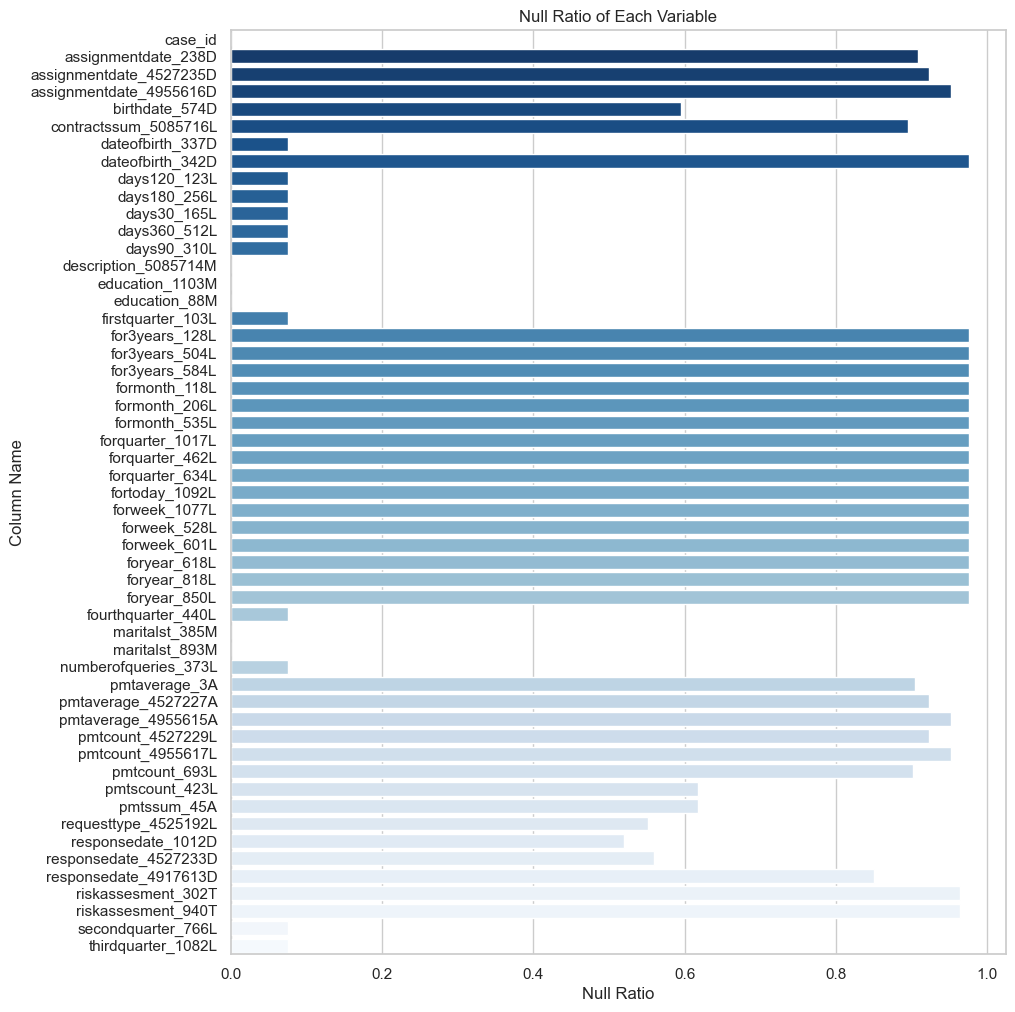
aggregation 하기 전 데이터별 null ratio는 너무 길어서 다음의 접은 글에 담아보았다.
depth = 0 파일에 대한 null ratio
train_static_0

train_static_cb_0
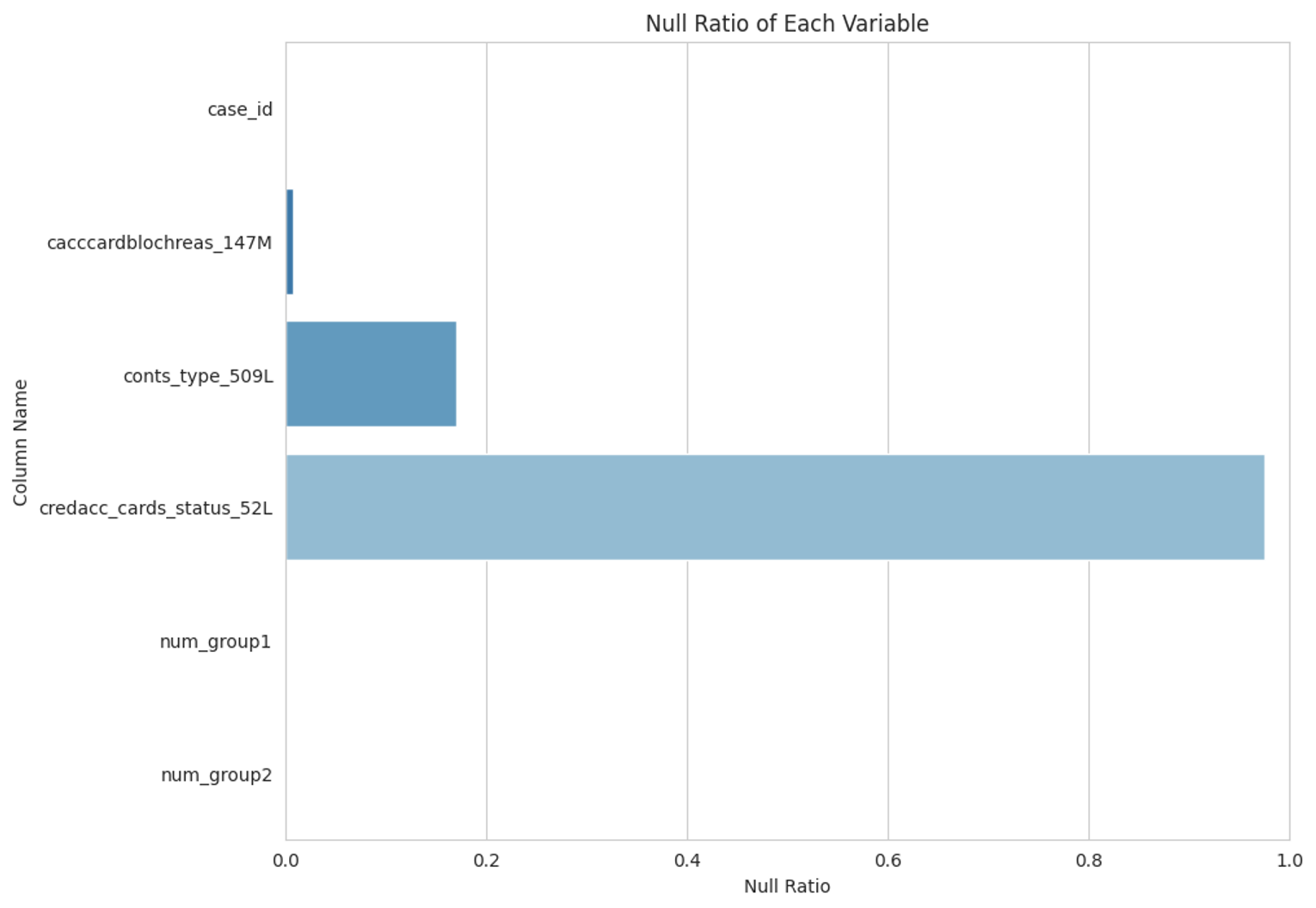
depth = 1 ~ 2 internal data 에 대한 null ratio
applprev_1

applprev_2
person_1
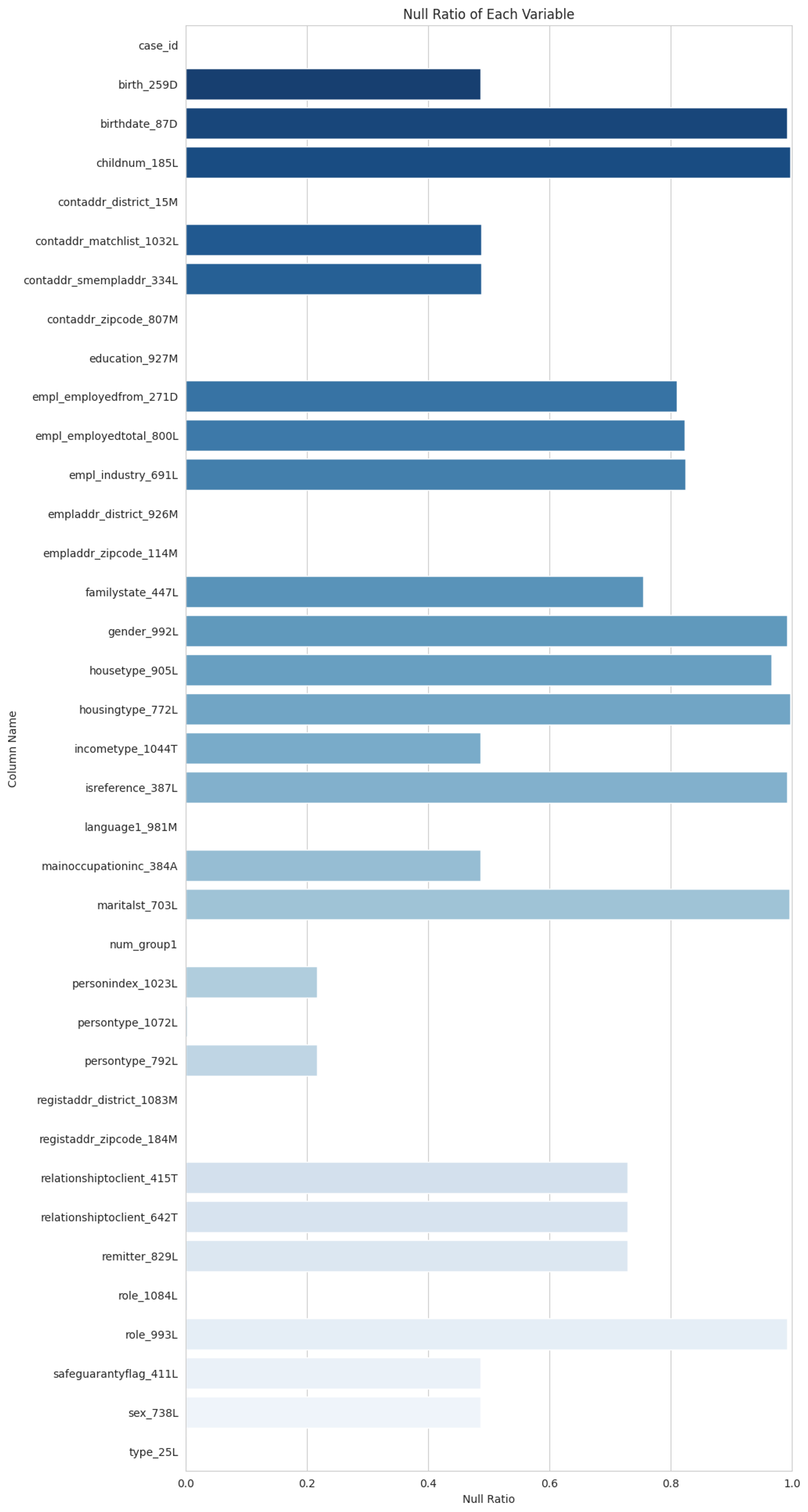
person_2
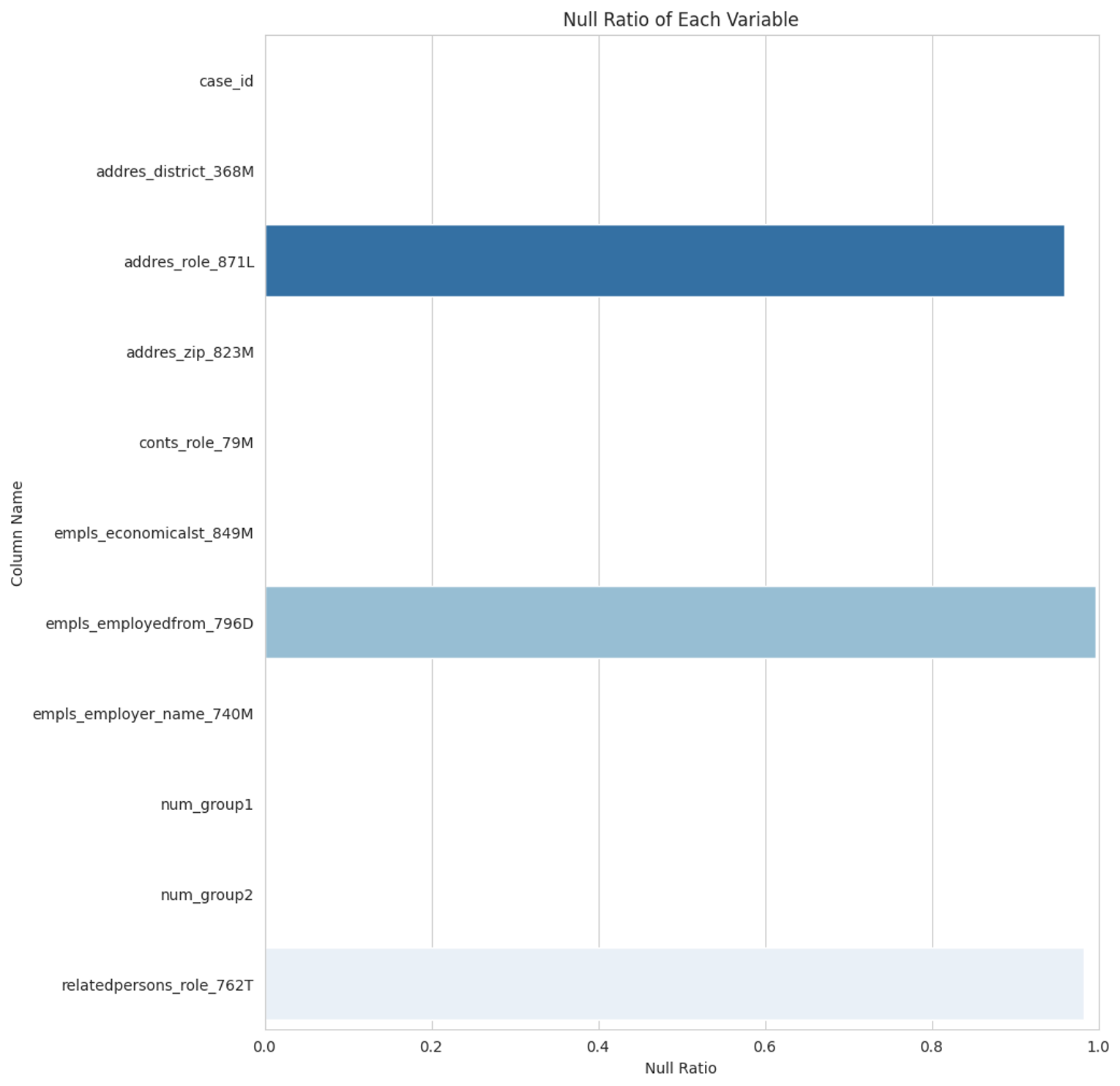
deposit_1
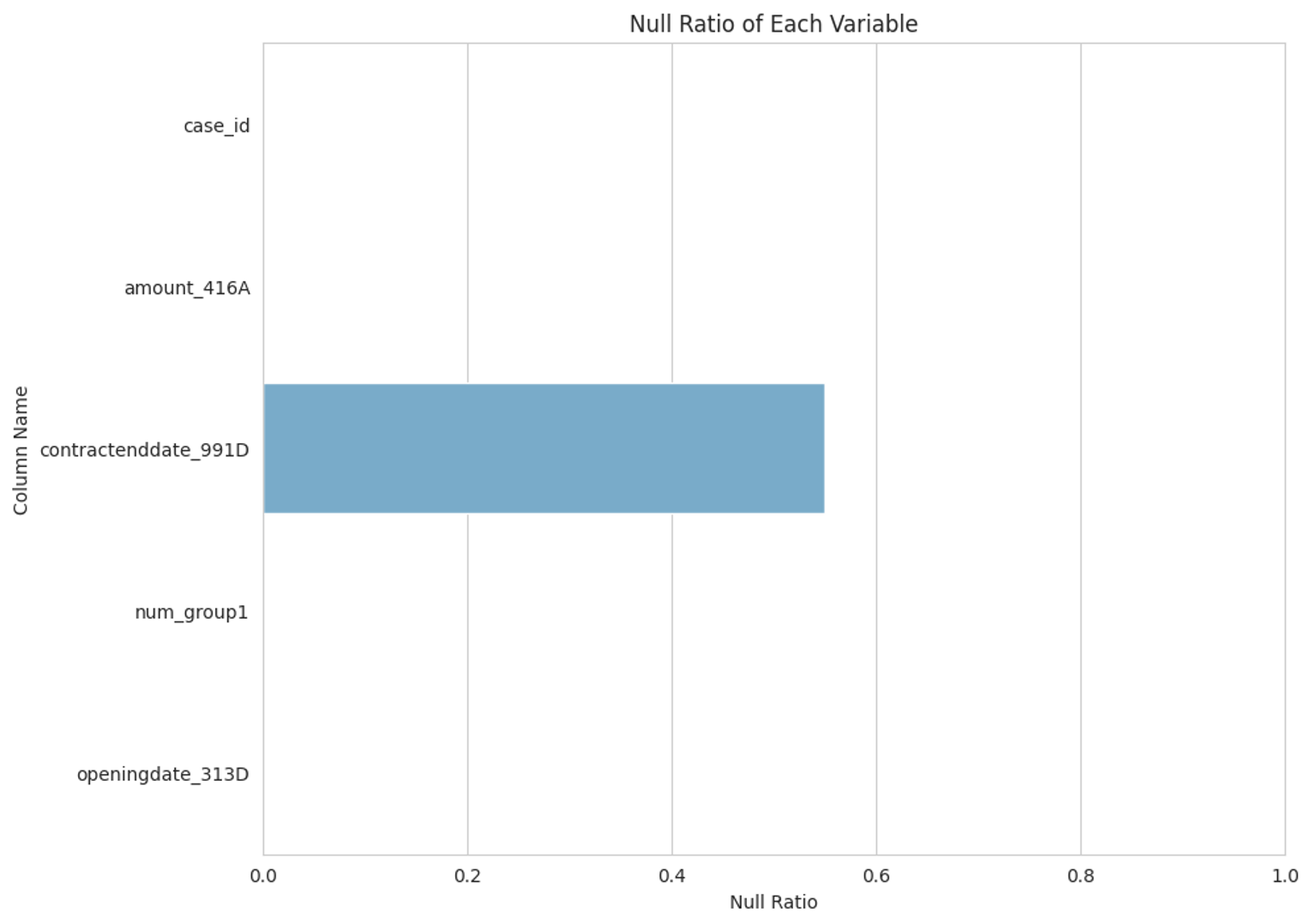
debitcard_1
other_1 : all columns non-null
depth = 1 ~ 2 external data 에 대한 null ratio
tax_registry_a/b/c_1 : all columns non-null
credit_bureau_a_1

credit_bureau_a_2
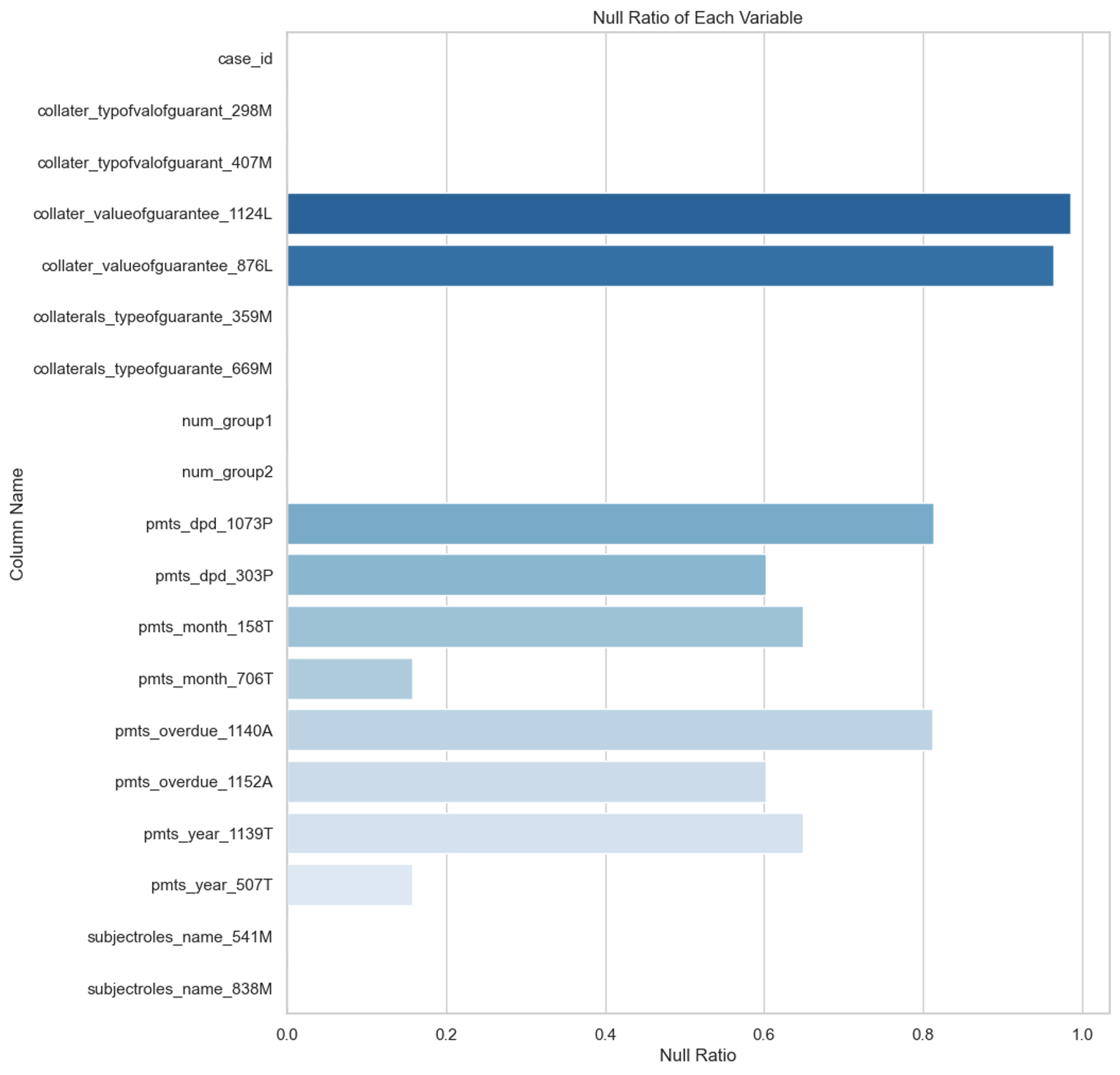
credit_bureau_b_1

credit_bureau_b_2

# 03. 프로젝트 진행
Step 1. 팀원 간 분석 작업 분배
팀원 모두에게 생소한 도메인일 뿐만 아니라 파일의 크기 또한... 168개 컬럼이 있는 파일, 1억 8천행^^이 있는 파일 등이 있어서 일단은 각자 파일을 분배하여 분석을 진행해보기로 하였다.
내가 맡은 파일은 다음의 세 파일들이었다.
- static_cb_0 : (1500476, 53)
- credit_bureau_a_2 : (188298452, 19)
- applprev_1 : (6525979, 41)
특히 credit_bureau_a_2의 분석 과정이 나름 흥미로웠다. 우리 팀원들 모두 대체 depth=0, depth=1, depth=2의 의미가 무엇인가 계속 이해하기 어려웠는데 credit_bureau_a_2를 세세하게 뜯어보는 과정에서 보다 명확하게 depth의 의미를 알 수 있었으며, 정성적 분석으로 이 데이터를 어떻게 활용할 수 있을까 깨닫게 된 그 과정이 내겐 너무 신기한 경험이었다. 덤으로 1억8천행의 데이터를 온전히 소화했다는 그 뿌듯함.
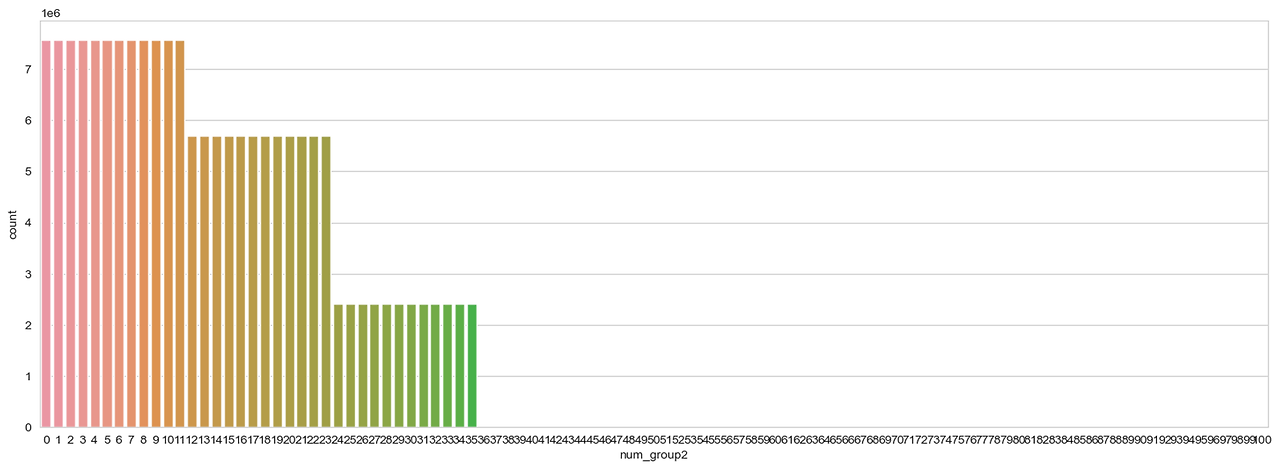
depth = 1, depth = 2에 따라오는 num_group1, num_group2라는 컬럼이 있었는데, 이게 각자 맡은 파일마다 의미가 다르지만 각 파일들을 aggregate하는 단계에서 하는 역할이 같음을 이해하는데 시간이 걸렸다.
이를 위해 나같은 경우 아예 내가 담당한 credit_bureau_a_2에 대해 num_group2의 분포를 플롯해보았다.
Step 2. baseline modeling and downsampling
모델 선택 : LGBM
target 값이 0, 1인 이진 분류 문제이며, feature definition에 정의된 컬럼만 465개, case_id 1526659개, 일부 데이터가 188298452행을 가지고 있어 트리 기반 모델 중에서도 lightGBM이 유효할 것으로 판단하였다.
팀원들끼리 최종 취합을 위해 공통의 베이스라인(https://www.kaggle.com/code/greysky/home-credit-baseline)을 선정하고, 다른 팀원이 전체 데이터를 취합할 수 있도록 베이스라인을 수정하는 작업을 진행하는 동안 나는 우리의 가장 큰 문제인 1억 8천행의 데이터를 어떻게 out of memory 없이 합치고, downsampling한 모델까지 돌려볼 수 있을까 테스트하는 작업을 담당하였다.
(베이스라인 코드 공유는 캐글의 자랑이자 개인적으로 신기하게 생각하는 부분인데, 캐글은 공유문화가 워낙 발달이 되어 있어서 이런식으로 많은 사람들이 각자의 베이스라인을 공유해주곤 한다. 이런 베이스라인이 있어서 덕분에 우리같은 초보자들도 최종 분석 결과까지 다가갈 수 있었다.)
Downsampling
이 데이터는 target 비율 97 : 3 로, class imbalance가 굉장히 심하다고 볼 수 있다. 이전 EDA 프로젝트 당시에도 이러한 class imbalance에 대한 고민을 했던 경험이 있어서 이 대회에서도 default인 target 1 을 잘 예측하는 것이 핵심일 것으로 판단하여 base model과 credit_bureau_a_2 데이터를 합친 모델에 대하여 no sampling, 10 to 1 sampling, 5 to 1 sampling을 수행하였다. 추가로 호기심에 두번째 모델에 대해서는 1 to 1 sampling도 실행해보았다.
실험 결과 일단 내가 분석하여 추가한 컬럼들이 상단에 올라오는 것을 확인하였으며, 다운샘플링이 효과가 있을 것이란 가설은 어느 정도 효과가 있었다고 판단하였다. 특히 다운샘플링한 부분과 credit bureau a_2까지 분석을 추가한 것이 다른 조와 우리 조의 차별점이었다. 다만 아쉬운 것은 프로젝트 기간 중 submission이 막히는 바람에 실제 리더보드 상 점수나 등수를 확인 할 수 없었다는 점이 아쉽다.
| AUC score | Base model | 2nd model (credit bureau a_2 added) | |||||
| no sampling | 10 to 1 | 5 to 1 | no sampling | 10 to 1 | 5 to 1 | 1 to 1 | |
| train | 0.8464 | 0.8454 | 0.8463 | 0.8597 | 0.8564 | 0.8602 | 0.8689 |
| valid | 0.8296 | 0.8326 | 0.8248 | 0.8448 | 0.8471 | 0.8417 | 0.8394 |
| test | 0.8290 | 0.8268 | 0.8313 | 0.8442 | 0.8416 | 0.8467 | 0.8413 |



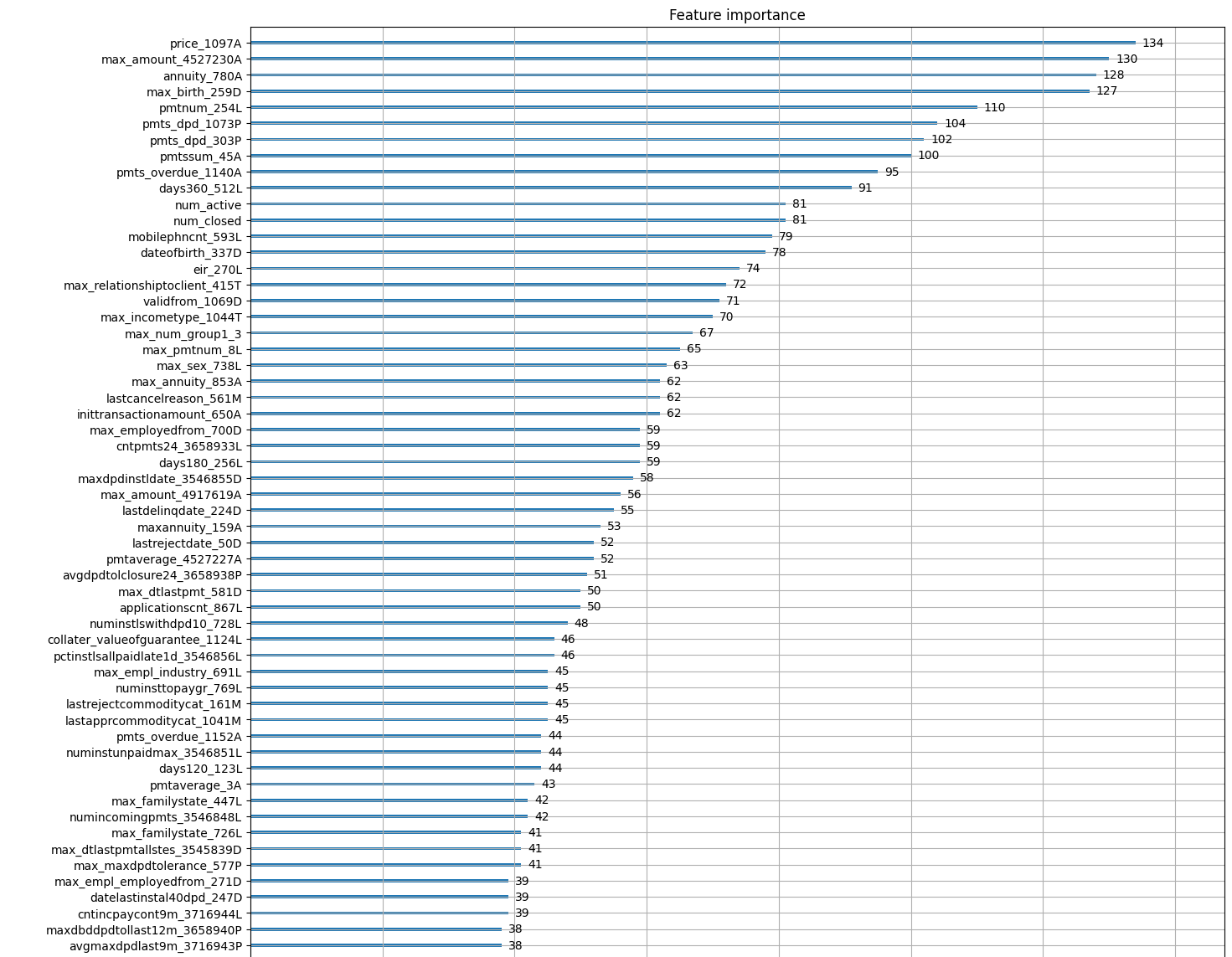
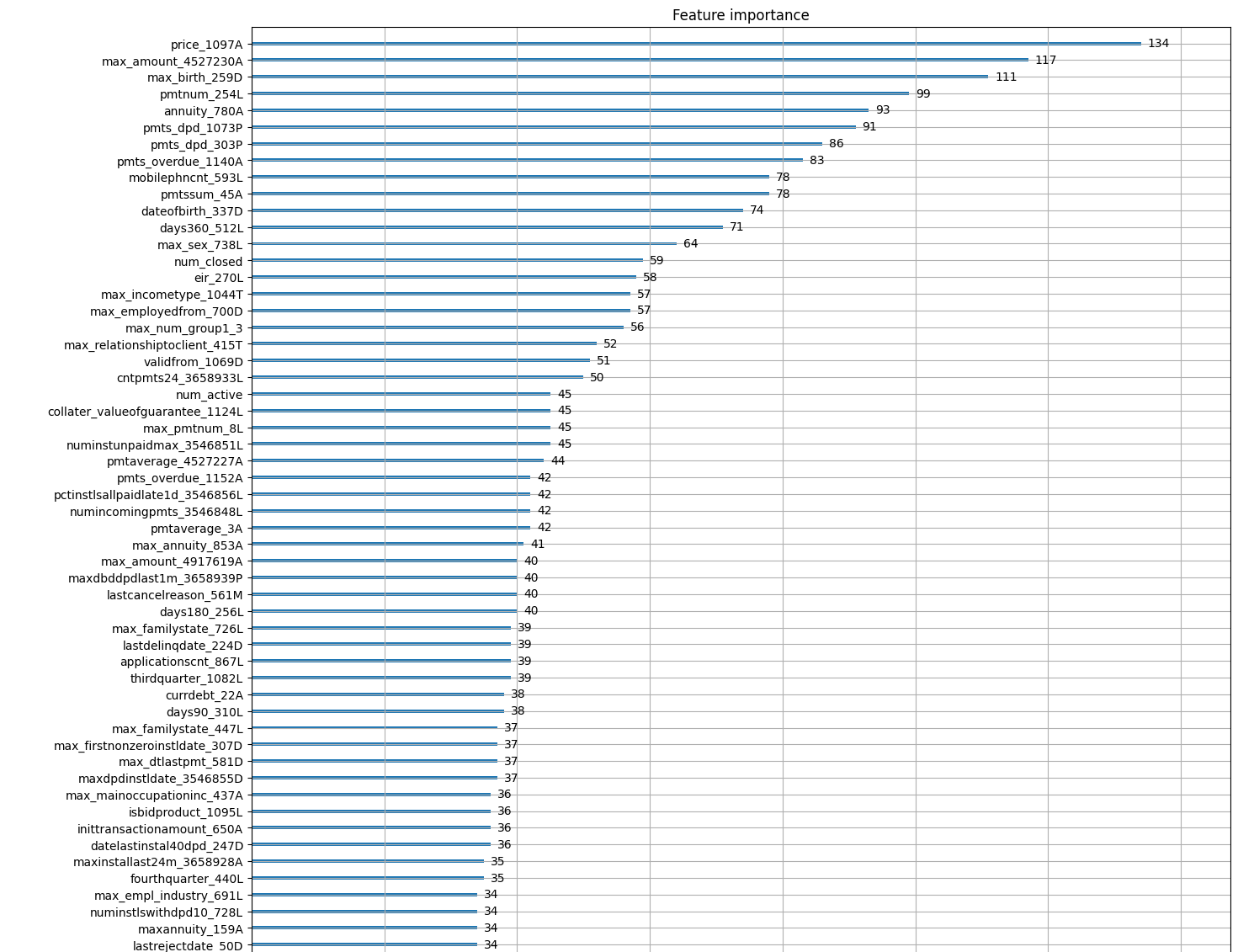

해당 프로젝트를 통해 무엇을 배울 수 있었고, 어떻게 성장할 수 있었다 하는 등의 내용도 소제목으로 분류하여 추가하시는 것을 권장
'패스트러너 기자단 4기' 카테고리의 다른 글
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #06_미니 프로젝트 - Upstage 경진대회 #1 (0) | 2024.04.04 |
|---|---|
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #05_그룹스터디 (1) 첫번째 그룹세미나 (0) | 2024.03.18 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #03_2개월차 후기 (0) | 2024.02.10 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #02_미니 프로젝트 (2) EDA 조별 프로젝트 (+ 1.5개월차후기) (0) | 2024.01.18 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #01_미니 프로젝트 (1) 크롤링 실습 (0) | 2024.01.04 |



