ML프로젝트가 끝나고, 2월 27일부로 업스테이지 과정이 시작되었다.
실시간 강의는 ML 프로젝트 전에 들었던 자료구조 및 알고리즘 강의가 마지막이었고, Upstage 과정부터는 Upstage에서 제공하는 온라인강의를 들으며 스터디와 경진대회를 진행하는 형식으로 바뀌었다.
2주간 진행된 그룹스터디는 1주차는 Deep Learning 개론을 주제로, 2주차는 PyTorch를 주제로 한 업스테이지 강의를 들으면서 각 주차별 목표에 맞춰 다양한 난이도의 미션이 주어졌고 팀별 상황에 따라 난이도를 선택하고 수강생 미션을 수행하는 방식으로 진행되었다.
1주차 이론 : Deep Learning 개론
1주차 수업은 이활석 CTO님이 진행해주셨다.
Deep Learning 개론은 딥러닝 발전의 역사를 5단계로 설명하고 딥러닝 기술의 종류들을 설명하며 "가볍게" 시작되었다.
여기저기서 친한 수강생들로부터 앓는 소리가 나오기 시작한 건 역전파( backpropagation )부터였다.
나 또한 이전까지 개략적으로 알고 있었던 것은, "Neural Network는 feedforward를 통해 연산을 수행한 뒤 loss function를 계산하고 backpropagation을 통해 손실함수의 gradient를 계산해 가장 gradient가 큰 방향으로 이동해가며 parameter를 조절하는 방식으로 loss function을 줄여나간다." 정도였다.
이 강의에서는 계산 그래프부터 설명해주시며 덧셈 노드와 곱셈 노드에서 역전파가 수행될 때 편미분값이 어떻게 전달되는지부터 설명해주셨고, 이를 바탕으로 역전파의 기본방정식 1~4를 설명해주셨다. 어렵긴 했던 부분이라 직접 손으로 두번 이상은 써보면서 봐야 했었다. (패드에서 쓰니 수식들의 연결성이 한눈에 안 들어와서 아날로그적인 방식으로 다음과 같이...) 하지만 개인적으로 너무 재밌었다!! 특히 딥러닝 공부할 때 개인적으로 이론 공부가 재밌기도 하고, 사실 그냥 수식으로 보는 쪽이 편해서 이렇게 잘게잘게 쪼개서 수학적으로 그 원리를 공부하는 게 재미있었다. (물론 여전히 노트 필기를 보며 다시 복습을 해야 설명을 할 수 있긴 하지만)




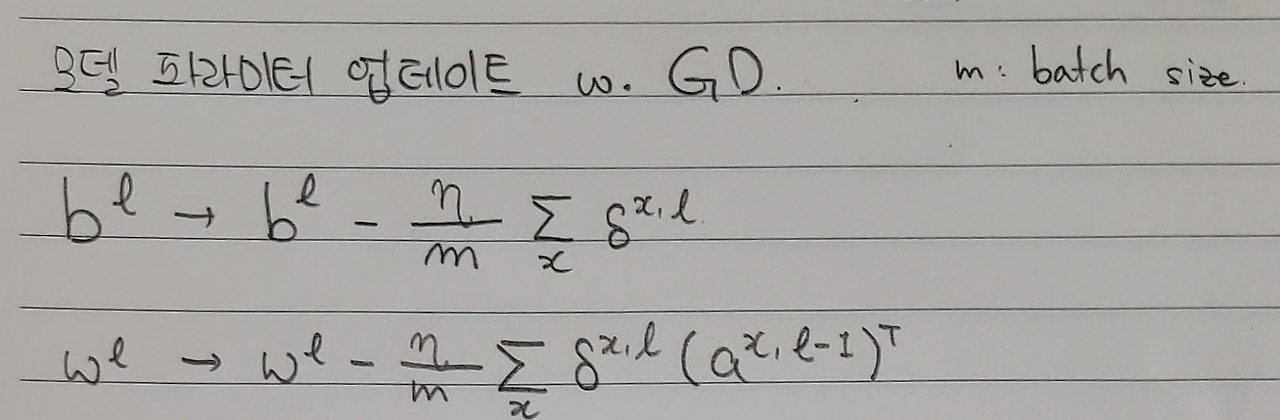
성능 고도화방법
성능 고도화 방법에서 특히 내가 집중적으로 공부한 부분은 최적화 알고리즘 부분이었다. 최적화 알고리즘은 feed forward 후 backpropagation에서 어떤 전략으로 모델의 weight를 업데이트 할 것인가를 선택하는 부분으로 다음과 같은 흐름으로 개선되어 왔고 최근에는 Adam이 많이 사용되고 있다고 하였다.
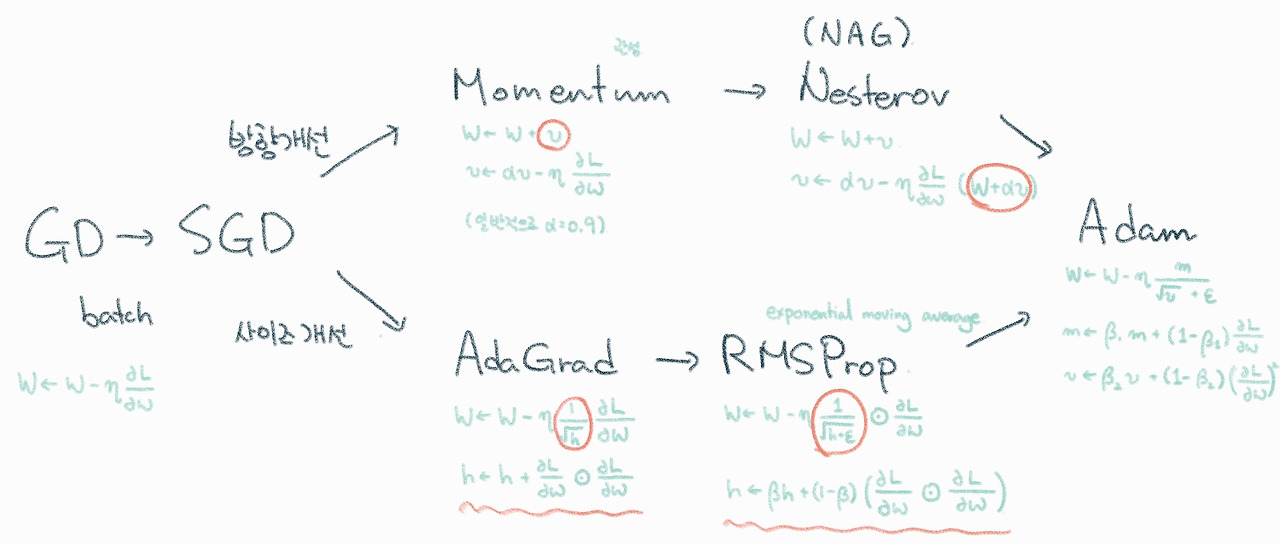
강사님에 대한 개인적 소감
사실 특강 때도 Upstage에서 오시는 강사님들이 다들 대단하다고 계속 생각했었다. 대부분의 강사님들이 상대가 알아 들을 수 있도록 내용을 잘 전달하며, 마무리로는 내용에 대한 요약도 깔끔하게 해주심으로써 강의 전달력이 완벽에 가까웠다.
그런데 Deep Learning 개론을 맡은 이활석 CTO님은 진짜... 말을 잃을 정도로 감탄의 연속이었다. 너무 설명도 쏙쏙 들어오고 내용을 전달하시는 방식이 클리어해서 너무 좋았다. (근데 함정은 너무 클리어하게 설명하셔서 내가 이해했다고 넘어가는데 다시 돌아보면 이해한 것이 아니었을 때가... ㅎㅎㅎ...)
2주차 : PyTorch
2주차 PyTorch는 Upstage AI Research Engineer이신 김윤기 강사님께서 진행해주셨다.
PyTorch 수업은 실습에 조금 더 포커스가 맞춰져 있었다. Tensor manipulation 에 대한 이론적 설명부터 시작하여 PyTorch 기본 사용법, DNN, CNN, RNN 구현과 timm을 이용한 전이학습, Wandb, 파이토치 라이트닝과 하이드라 등 추후 딥러닝 공부의 기본이 될 실습으로 주로 구성되어 있었다.
그 중 내가 특히 관심있게 공부한 부분은 CNN구현과 Tensorboard와 Wandb였다.
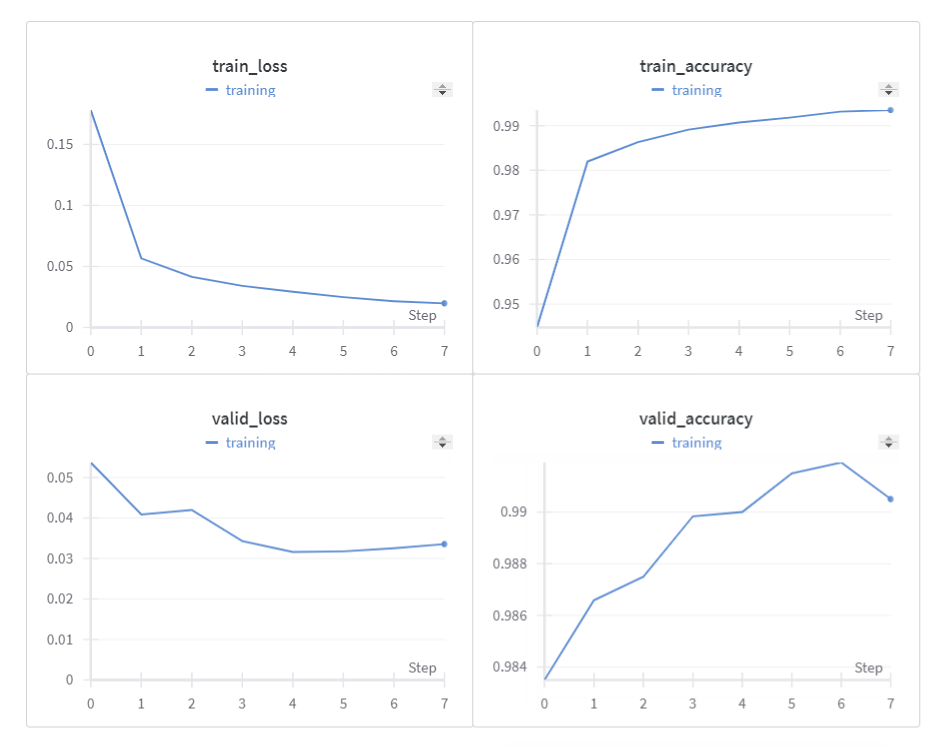


Epoch [39 / 100], Train Loss : 1.7316, Train Acc : 0.7298
Epoch [39 / 100], Valid Loss : 1.8127, Valid Acc : 0.6478
Early stopping at epoch 39
Valid max accuracy : 0.6564
Custom CNN test accuracy : 0.6494
수강생 미션
1주차 수강생 미션
목표
- 딥러닝의 기본기 이해 및 구현 능력 습득
- 실무에서의 딥러닝 적용 능력 향상
- 현대 딥러닝 아키텍처와 트렌드 이해
난이도 (하) :
- Pytorch Template(https://github.com/victoresque/pytorch-template)을 이용하여 MNIST를 분류하는 MLP 모형 만들기
- Pytorch 공식 튜토리얼 문서의 컴퓨터 비전 전이 학습을 이해하고 각 줄에 대한 주석 달기
(https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html)
난이도 (중) :
- Convolutional Neural Networks를 직접 구성하여 99% 이상의 성능을 내는 MNIST 분류기 만들기
- Recurrent Neural Networks (RNN or LSTM or GRU)를 직접 구성하여 98% 이상의 성능을 내는 MNIST 분류기 만들기
- Albumentation (https://albumentations.ai/) 라이브러리를 이용하여 MNIST 데이터를 증강하여 99.5% 이상의 성능을 내는 MNIST 분류기 만들기
난이도 (상) :
- Convolution과 Activation 레이어만을 활용하여 MNIST 분류기 만들기
- Semi-supervised learning을 이용한 MNIST 분류기 만들기 (참고 자료:
https://blog.est.ai/2020/11/ssl/, https://github.com/rubicco/mnist-semi-supervised)
2주차 수강생 미션
목표
- Pytorch를 이용하여 다양한 딥러닝 모델 구현에 필요한 tensor 연산을 자유자재로 할 수 있다.
- 기본적인 딥러닝 모델들을 직접 구현하여 학습 및 추론할 수 있다.
- 다양한 라이브러리에 구현되어 있는 딥러닝 모델을 손쉽게 사용할 수 있고, 구현 과정에서 생기는 다양한 에러들을 해결할 수 있다.
난이도 (중) :
- PyTorch를 기반으로 만들어진 다른 라이브러리 스터디 (예시: mmpretrain, timm)
- PyTorch Template과 Aihub 의 데이터 하나를 선정하여 간단한 분류 모델 만들어보기
우리 조는 1-2주차 미션을 결합하여 UCI repository에서 학습하고 싶은 데이터로 CIFAR-10 dataset (https://www.cs.toronto.edu/~kriz/cifar.html)을 선택하여 CustomDataset 클래스를 생성하고 DataLoader를 통해 직접 구성한 CNN을 학습시키는 것을 목표로 하였다.
처음에는 conv layer 두 층으로 시작하여 성능을 체크하며 conv layer를 늘려가는 방식으로 작업해보았다. from scratch로 작업한 이유는 코드 필사도 겸해서 진행하고 싶어서였으며, 기초부터 어떻게 변화가 생기는지 확인하고 싶었기 때문이다.
Valid max accuracy 0.6172에서 시작해 7층의 conv layer와 dropout_ratio = 0.3까지 적용하여 Valid max accuracy 0.6865 를 달성하였지만 생각보다 CNN의 구조가 복잡해지는 정도 대비 성과가 미미한 이유가 궁금해졌다.




이에 대해 조장님을 통해 멘토님께 질문해본 결과 다음과 같은 답변을 얻었다.
- 위에서 말씀하신 것처럼, 5x5커널 1개와 3x3 커널 2개는 같은 receptive field를 가집니다. 같은 receptive field에 더 적은 파라미터를 쓸 수 있기 때문에 계산면에서 더 효율적이고, 3x3 필터 사이에 activation function을 넣음으로써 nonlinearity를 더할 수 있습니다. 두개의 3x3 커널이 계산적으로 효율적이기도 하고, non linearity를 더하는 것도 좋지만 성능 개선을 무조건 보장하는 것은 아니니 이 부분을 주의하셔야 합니다.
여기서 조금 더 확실하게 이해하고 싶어 VGG 논문으로 빠지게 되었다.
VGG 논문 : Simonyan, Karen, and Andrew Zisserman. "Very Deep Convolutional Networks for Large-Scale Image Recognition." arXiv preprint arXiv:1409.1556, 2014. 9
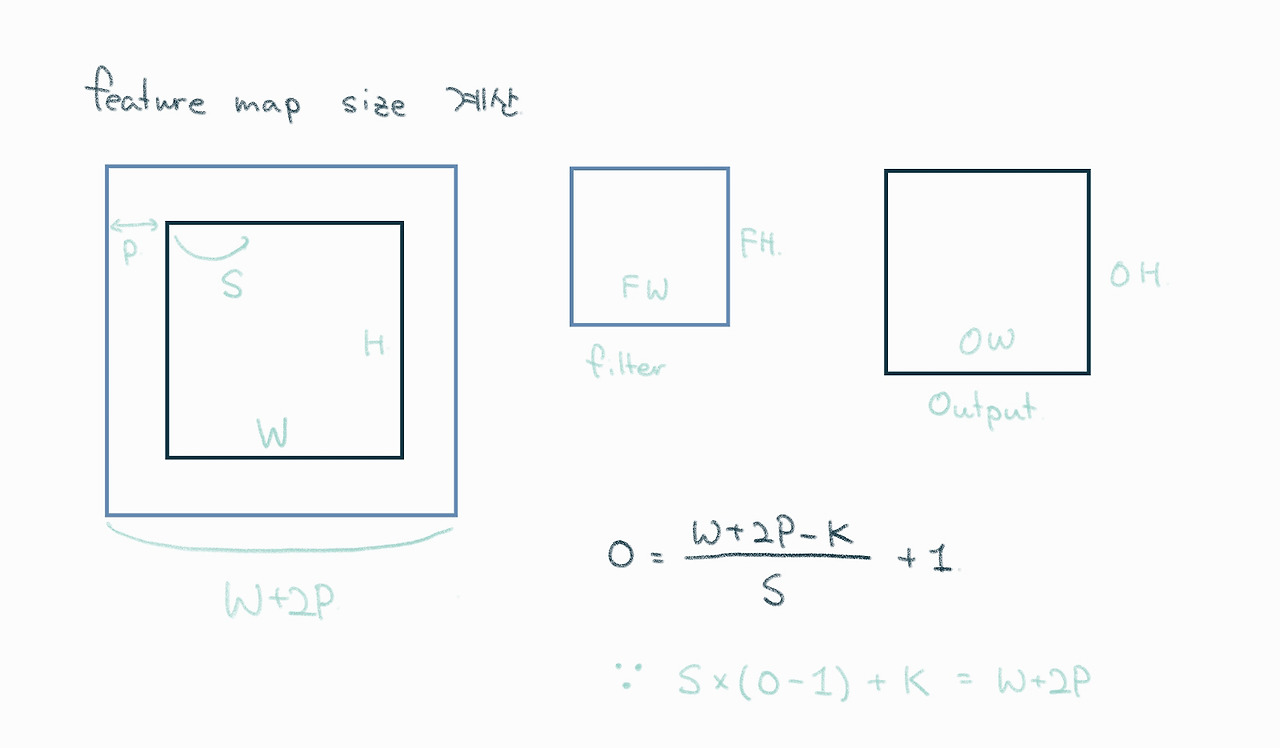
VGG architecture의 기본은 input 224 x 224 RGB 에 대해 only 3x3 kernels (stride 1, padding 1) 만을 이용하여 아주 deep하게 conv layer를 짜본다는 개념으로 바탕으로 하였다. 이렇게 하면 MaxPool 없이 Conv. layer의 input과 output channel 을 C로 고정하면 3x3 conv 3층은 7x7 conv 1층의 receptive field는 같은데 parameter는 3(3^2xC^2) = 27C^2 vs. 7^2C^2 = 49C^2 로 훨씬 적은 수의 파라미터로 연산량에 대한 부담이 줄어들 뿐 아니라 conv layer 사이에 활성화 함수를 추가할 수 있어 비선형성을 더 줄 수도 있다는 장점이 생긴다는 것이다.
원문 : “It is easy to see that a stack of two 3×3 conv. layers(without spatial pooling in between)has an effective receptive field of 5×5; three such layers have a 7×7 effective receptive field. … First, we incorporate three non-linear rectification layers instead of a single one, which makes the decision function more discriminative. Second, we decrease the number of parameters: assuming that both the input and the output of a three-layer 3×3 convolution stack has C channels, the stack is parameterised by 3(3^2xC^2) = 27C^2 weights; at the same time, a single 7×7 conv. layer would require 7^2C^2 = 49C^2 parameters, i.e. 81% more. This can be seen as imposing a regularisation on the 7×7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between)”
아래 gif는 그룹 세미나 자료 준비를 앞두고 만든 receptive field 설명 자료이다.
위 논문과 https://www.youtube.com/watch?v=lxpQZRvfnCc 이 유튜브를 참고하여 이해한 것을 새롭게 시각화해보았다.

해당 프로젝트를 통해 무엇을 배울 수 있었고, 어떻게 성장할 수 있었다 하는 등의 내용도 소제목으로 분류하여 추가하시는 것을 권장
'패스트러너 기자단 4기' 카테고리의 다른 글
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #08_미니 프로젝트 - Upstage 경진대회 #2 (0) | 2024.04.24 |
|---|---|
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #06_미니 프로젝트 - Upstage 경진대회 #1 (0) | 2024.04.04 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #04_미니 프로젝트 (3) ML 프로젝트 (0) | 2024.03.03 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #03_2개월차 후기 (0) | 2024.02.10 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #02_미니 프로젝트 (2) EDA 조별 프로젝트 (+ 1.5개월차후기) (0) | 2024.01.18 |



