#00_1.5개월차 후기
2023년 12월 11일 OT를 기점으로 '전역을 기다리는 병장'처럼(내 모습을 지켜본 아버지의 비유였다.) 달력에 26번째 빗금을 쳤다. 오늘로 27일차.
그동안 실시간 강의와 엄청난 양의 온라인 강의 + 개인적으로 궁굼한 부분에 대한 추가 조사 + 한번의 개인 프로젝트 + 한번의 팀 프로젝트 (+ 원치 않게 급작스럽게 이사를 하게 된 부분까지)
분명 앉아만 있었는데 매일이 숨이 찬 나날들이었다.
후하후하 (막내 조원한테 배운 표현 ㅎㅎ)
매일 교육 내용을 정리해서 하루 한번 블로그에 정리글을 올리는 것이 소소한 목표였으나, 코드를 작성하는 테크닉이 부족하다 보니 오히려 초반 2주는 글을 쓸 엄두조차 나지 않았다. 부트캠프라는게 아무래도 수학의 정석 펴고 정의부터 읽고 한걸음한걸음 나가던 내 공부방식과 완전히 다르게 일단 요이 땅 하고 달리기부터 시작해서 우당탕탕 이리 부딪히고 저리 부딪히며 맨땅에 헤딩하듯 공부하다보니 진짜 하루하루가 어찌나 숨이 차던지. 하지만 일을 해본 경험으로 이렇게 해야 짧은 기간 안에 많이 배울 수 있다는걸 알고 있으니까.. 그저 군말 없이, 가능한 선에서 페이스 조절도 하며 어떻게든 따라가보려고 애쓰며 지나간 5주였다.
아직까지도 가장 어려운 부분인데, 나는 큰 틀을 짜놓은 뒤 세부 지식을 배치하는 방식으로 공부하고 정리하는 것을 선호하는데, 지금은 흩어져있는 지식들이 급하게 주입되고 있다보니 일단은 급하게 들은 순서대로 나열하듯 쓰는 정도로밖에 공부를 못 하고 있다는 것이다. 개인적인 욕심으로는 A5 정도 크기로 이 부트캠프 과정의 핵심 요약을 담은 핸드북을 만들어보고 싶은데, 장담은 못 하겠다. 마음 한켠에 그 욕심 잘 간직해두며 때때로 떠올리며 도전해보는 수 밖에...
어제자 공부의 흔적
전 직장 동료가 내가 공부/연구하는 방식을 보고 비주얼 충격을 받았다고 했던 말이 떠오른다...
 |
 |
 |
그래도 이제 6주차로 진입하고, 이번 주간은 통계주간이라 조금 숨 쉴 틈이 생겼다.
#01_미니 프로젝트 (2) EDA 조별 프로젝트
2024년 1월 2일 (화) 부터 1월 11일 (목) 까지 약 2주간(실질적으로는 열흘 정도) 조별로 EDA프로젝트를 진행하였다.
신정 연휴를 앞 둔 금요일 저녁, 2023년 마지막 공지와 함께 조편성 공지가 올라왔고, 2조 카톡방이 생겼다. 강사님이 데일리 미팅과 소통의 중요성을 강조하셨던지라 프로젝트를 시작하기에 앞서 우리 조는 일단 미팅은 데일리로 두 세번 정도(오전 10시에 첫 출석체크를 진행 한 후, 점심 직후, 수업이 끝나기 한시간 쯤 전) 진행하기로 논의하였다.
2024년 1월 2일 (Day 1)
첫 만남.
당연히 강사님이 선별해놓은 자료로 진행하게 될 거라 생각해서 주말동안 미리 자료를 훑어오보고 왔는데,
raw data만 봤을 때는 안 보이다가 eda를 해서 "새로운 인사이트"를 찾을 수 있는 자료를 가지고 진행하고 싶다는 한 조원의 의견을 존중하여 우리 조는 하루 정도 데이터 선정에 시간을 할애하기로 하였다.
생각보다 자료를 선별하는 과정이 어려웠다.
① 의료 바이오 정보를 제공하는 AI Hub( https://www.aihub.or.kr/ ) 등과 같은 플랫폼이 몇 군데 있었지만 개인정보 때문인지 사용신청을 해야만 사용이 가능하고 몇가지 추가적인 제약사항들이 있었다.
② (IRB 등의 문제 때문으로 추측되는데) 현실 데이터가 아닌 synthetic data가 많아서 이러한 데이터들을 제외하는 과정이 필요했다.
그 결과 우리 조는 캐글에 올라와 있는 Diabetes Health Indicators Dataset 를 사용하기로 하였다.
데이터 출처 : https://www.kaggle.com/datasets/alexteboul/diabetes-health-indicators-dataset/data
이 데이터셋에는 총 3개의 csv 파일이 제공되었다.
당뇨병 전단계를 포함해 3개 카테고리 (0 = no diabetes, 1 = prediabetes, 2 = diabetes) 로 분류한 'Diabetes_012' 자료, 동일 피험자에 대한 자료를 당뇨병 유무 binary( 0 = no diabetes, 1 = prediabetes or diabetes )로 레이블링 한 'Diabetes_binary' 자료, 그리고 'Diabetes_binary'를 당뇨병 여부에 따라 50 대 50이로 샘플링한 'Diabetes_binary_5050’ 자료.
2024년 1월 3일 (Day 2)
오전 회의.
우리 조는 'Diabetes_012' 로 분석할 경우 당뇨병 환자의 비율이 너무 적기 때문에 class imbalance 문제의 가능성을 염두에 두고 'Diabetes_binary'를 가지고 분석을 진행하기로 하였다.
또한 일반적으로 이러한 분석을 진행하기에 앞서 중복행을 제거한다는 것을 조원으로부터 배웠는데, 초보자 입장에서는 중복행을 삭제하는 부분에 의문을 가졌다. 같은 데이터를 가진 두 명 이상의 서로 다른 피험자일 수도 있지 않겠냐는 생각이 들었던 것이다. 이 질문에 대해 다른 조원이 답해 준 것은 변수 대부분이 범주형 데이터이고, 'BMI', 'MentHlth', 'PhysHlth' 등은 numerical data이긴 하나 discrete data이므로 모든 value가 겹치는 행은 유의하지 않은 데이터일 것으로 판단하는 것이 맞다는 것이었다.
데이터셋 크기 : 총 229,474명에 대한 21개 feature (no diabetes : 194,377 / diabetes : 35,097)
(데이터 개요 : https://hyj89han.tistory.com/74)
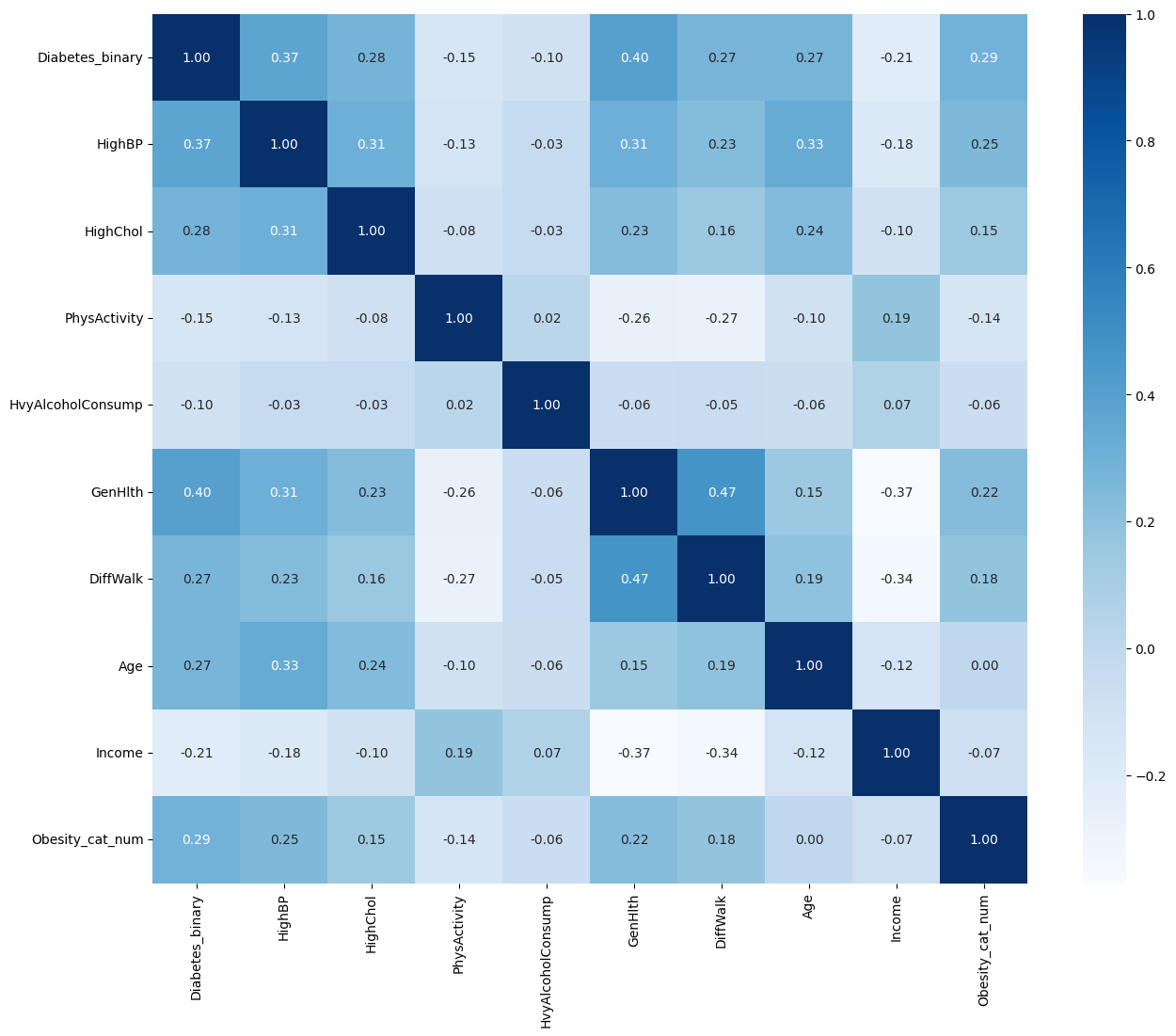
이 데이터를 바탕으로 어떤 요인들이 당뇨에 영향을 미치는지 보기위해 간단한 barplot과 correlation heatmap을 출력해보았다. barplot을 바탕으로 당뇨환자와 당뇨가 없는 경우 차이가 보이는 변수들을 간략하게 체크할 수 있었다. correlation heatmap은 전체 변수들에 대해 분석하였는데, 이는 당뇨에 대한 영향력 뿐만 아니라 상호간 경향성이 비슷한 변수들은 생략해야 될 것으로 생각하였기 때문이었다.
diabetes_binary = pd.read_csv('.\data\diabetes\diabetes_binary_health_indicators_BRFSS2015.csv')
df_diabetes_binary = diabetes_binary.astype(int)
df_diabetes_binary = df_diabetes_binary.drop_duplicates()
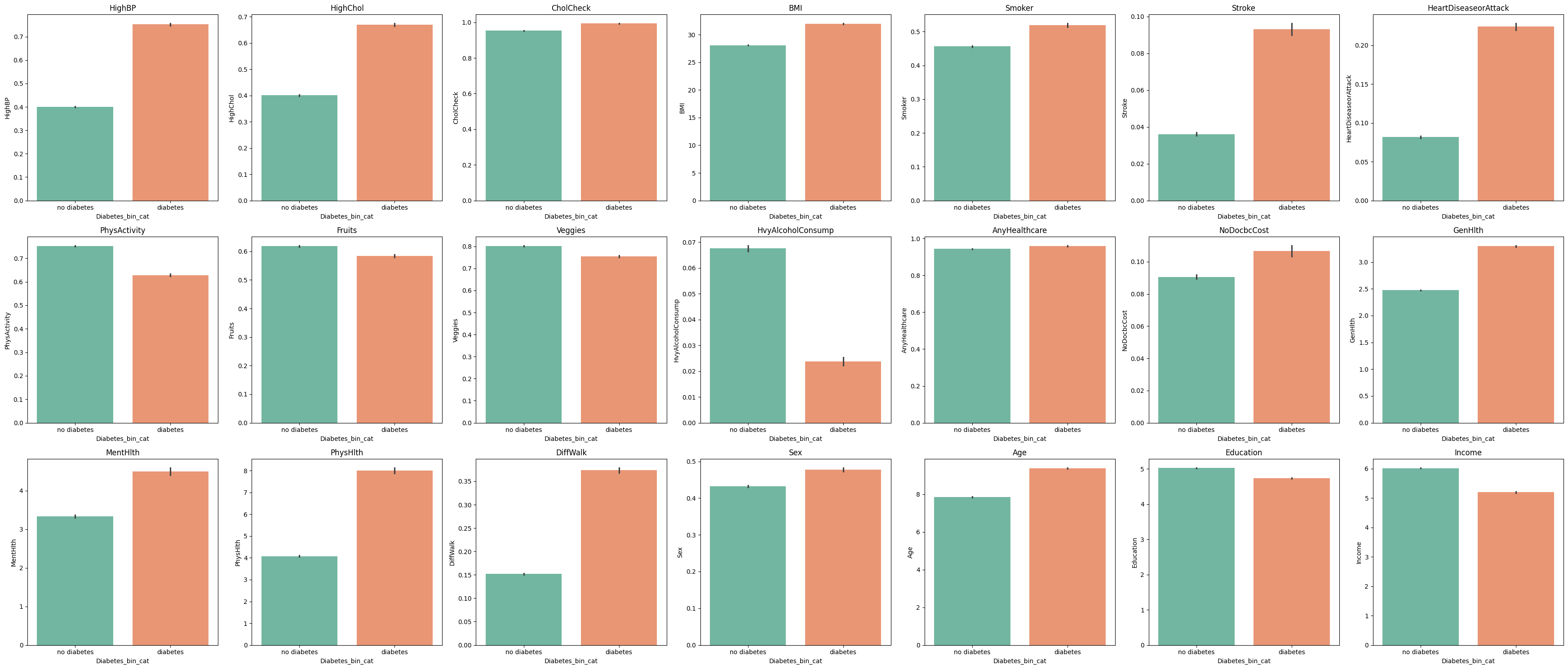
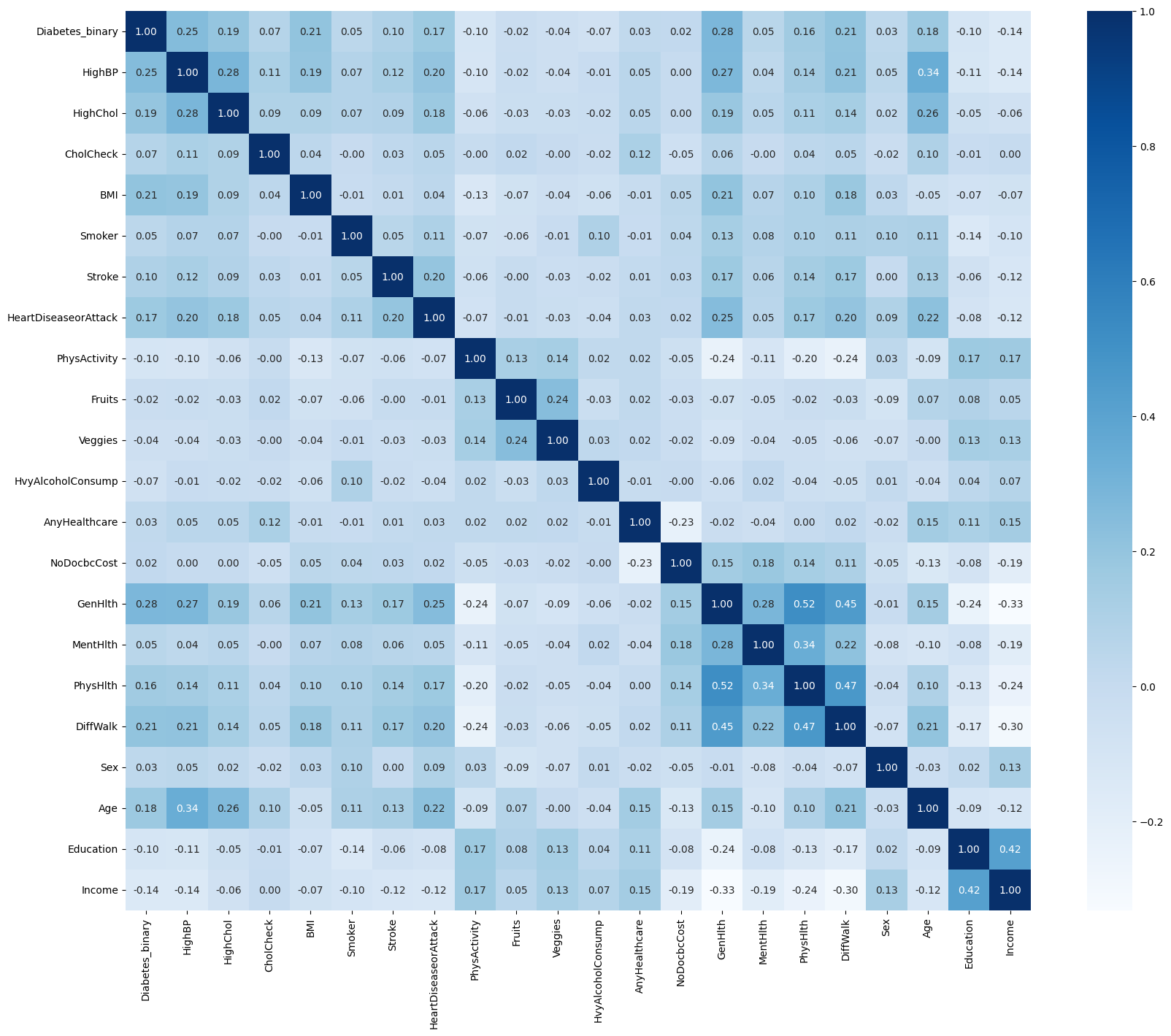
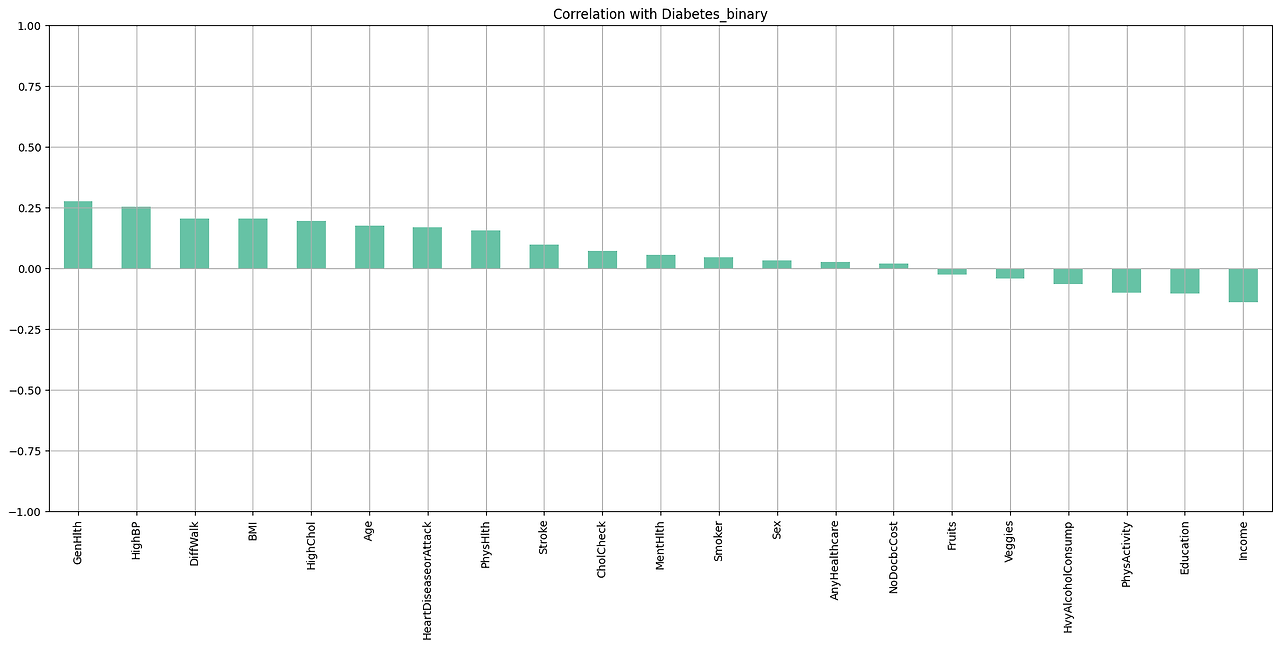
하지만 두집단간의 평균 차이를 그려주는 barplot과 correlation은 유의하지 않은 변수를 제거하는데 사용할 수는 없기 때문에 통계학적으로 정확한 용도는 기억이 안 났지만 어렴풋한 기억을 바탕으로 categorical 변수들( 'GenHlth', 'Age', 'Education', 'Income', 'BMI', 'MentHlth', 'PhysHlth' )에 대해서는 카이제곱 검증을 binary 변수들에 대해 간단한 로지스틱 회귀를 진행해보았다. 이를 바탕으로 가장 중요도가 높은 변수들을 선택하거나 유의하지 않은 변수들을 제거할 수있을 것으로 기대했으나, 카이제곱 검증 결과 모든 변수에 대해 p_value 0.05 이하로 나와서 변수 선택에 대한 정보를 얻을 수 없었다.
(두 집단 간 평균 차이에 대한 유의미성을 검증하는 의미에서 t-test도 실행해보았으나 옳은 접근이 아니라는 조원의 피드백이 있었다. 이부분은 나중에 통계 공부를 보충함으로써 조금 더 보완해보려 한다.)
오후 강사님 피드백.
선택한 데이터셋의 research questions가 명확하기 때문에 XGBoost로 feature importance를 추출한다든가, 혹은 linear model을 학습시켜 당뇨병을 예측하는 머신러닝 모델까지 발전시켜야 할 수도 있을 것 같다는 피드백을 받았다.
다만 이 데이터셋은 class imbalance가 심하지 않아서 class imbalance에 따른 별도의 처리는 필요 없을 것이라고 조언해주셨다.
어쨌든 EDA 프로젝트에서 가장 중요한 것은 스토리라인이기 때문에 business implication이나 research question들을 세부화하여 진행할 것을 조언해주셨다.
(나아가 CDC에서 같이 결합해서 볼 수 있는 데이터가 있는지 찾아보는 것도 추천해주셨지만 결과적으로는 이부분까지 진행하지 못 한 것이 개인적으로 아쉽다.)
내가 진행한 작업에 대한 피드백도 받았다. class imbalance가 심하지는 않지만 균등한 자료가 아니기 때문에 성능평가지표로는 accuracy가 아니라 f1-score를 써야 한다는 것이었다. 아직 과정 내에서는 수업을 진행하진 않았지만 이전에 배웠던 것을 바탕으로 나는 EDA와 로지스틱 회귀 분석을 담당하기로 하였다. 변수들을 조합해나가며 실행한 로지스틱 회귀의 성능지표를 바탕으로 유의한 변수들을 선별하고 싶었기 때문이다.
2024년 1월 4일 (Day 3)
조원들은 전날 강사님의 피드백을 바탕으로 각자 생각하는 방향대로 개별적으로 분석을 진행해보기로 하였다.
나는 이날 두가지 방향으로 작업을 진행하였는데, 하나는 EDA를 보다 세분화해서 보는 작업과, 또 하나는 로지스틱 회귀분석을 통한 변수 선택 작업이었다.
( https://hyj89han.tistory.com/72 )
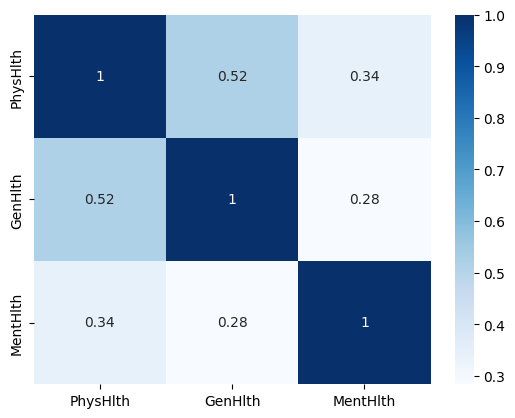
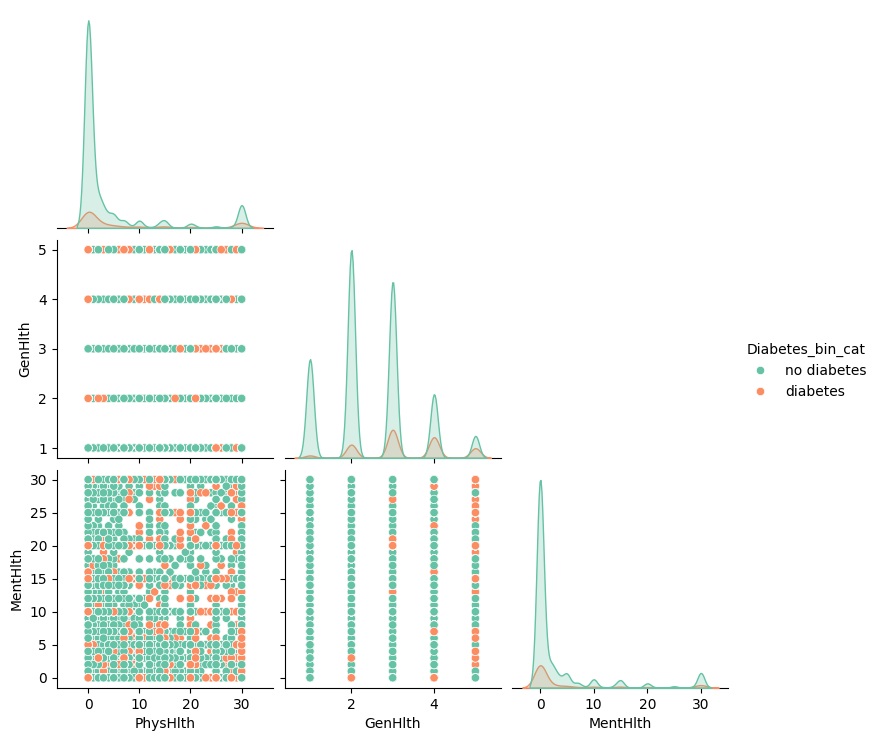
두째날 까지는 전반적인 진행방향을 파악하기 위해 조금 rough하게 전체 분포를 보았다면, 이날은 binary가 아닌 변수들 중심으로 분포를 살펴보았다. 일단 BMI에 대한 히스토그램과 Mental Health, Physical Health, General Health, Age, Education, Income에 대한 countplot을 전체/당뇨/비당뇨로 플롯해보았다.
가장 큰 문제는 Mental Health, Physical Health 응답중 0의 비율이 너무 높았다. (MentHlth : 0.663801, PhysHlth : 0.595179) 이 부분을 어떻게 처리해야하나 고민이 되었다. 또한 상관계수 히트맵으로 보나, 설문의 형태로 보나 General Health, Mental Health, Physical Health가 scatterplot 상에서도 유의한 상관관계가 보이도록 플롯 될 것으로 예상했으나 전혀 다른 결과가 나왔다. 이 부분 역시 Mental Health, Physical Health에 대해 0으로 응답한 비율이 높아서 인 것으로 판단되었다. 이 부분에 대해 어떻게 처리할 것인지 논의가 필요했다.
 |
 |
또한 엉성하게나마 로지스틱 회귀를 진행하였는데, 계속 f1 score가 0.2 언저리로 나왔다. 무언가 잘못하고 있다는 시그널이었다. 일단은 멈추고 다음날 강사님의 피드백을 받아보기로 하였다.
2024년 1월 5일 (Day 4)
강사님으로부터 로지스틱 회귀에 대한 피드백을 받았다.
내가 너무 기본적인걸 깜빡하고 있었다. 로지스틱 회귀는 너무 당연하게도 스케일의 영향을 받는다는 것이었다. 아차!
또한 f1 score가 영 시원찮게 나오는 상황에 대해 강사님은 다음과 같은 가능성들을 얘기해주셨다.
- overfitting인지 아닌지
- 차원의 저주 문제인지 (모델 사이즈에 비해, feature가 너무 많을때)
- class imbalance문제인지
- hyper-parameter 때문인지
이를 바탕으로 조금 가닥이 잡혀서 일단 로지스틱 회귀 부분은 'Diabetes_binary_5050’ 자료로 진행하기로 방향을 수정하였다. 회귀를 진행하기에 앞서 scaling을 하는 것 또한 잊지 않았다.
2024년 1월 8일 (Day 5)
발표의 가닥을 잡기 위해 가설을 무엇으로 할 것인지 한 조원이 물어봤다. 일반적으로 내가 진행했던 연구들에서는 가설을 처음부터 설정한다기보다 데이터를 분석하고 가설의 방향을 잡고, 가설의 유효성을 체크하고 가설을 업데이트하다보니 가설의 구체화 부분을 조금 미루고 있었던 듯 하다. 머릿속에 어렴풋이 품고는 있었지만 글로 구체화할 필요가 있었다. 조원의 요청사항을 기회로 가설에 대해 고민해보았다.
일단 내가 생각하고 있는 가설들은 다음과 같았다.
1. 'CholCheck'/ 'AnyHealthcare' / 'NoDocbcCost' 변수는 영향이 없을 것이다.
2. 'Stroke'/ 'HeartDiseaseorAttack' 변수는 당뇨병에 대한 설명변수보다는 당뇨병에 의한 결과일 수 있다.
3. 'GenHlth' / 'MentHlth' / 'PhysHlth' 를 별도로 구분하지 않아도 될 것이다.
4. BMI의 카테고리(① 'underweight', 'healthy', 'overweight', 'obese' / ② 'not obese' / 'obese' )는 당뇨병 예측에 중요한 변수일 것이다.
5. + 어떤 변수들의 조합이 예측력을 높일 수 있을 것인가.
(https://hyj89han.tistory.com/79)
일단 영향이 없을 것 같은 변수들에 대하여 근거를 정리해보기로 하였고(1~3), BMI 자체와 당뇨병의 연관성이 생각보다 부각되지 않아 카테고리화하여 영향력을 봐야하겠다고 판단하여 새로운 방향을 추가하였다.
2024년 1월 8일~11일 (Day 5~8)
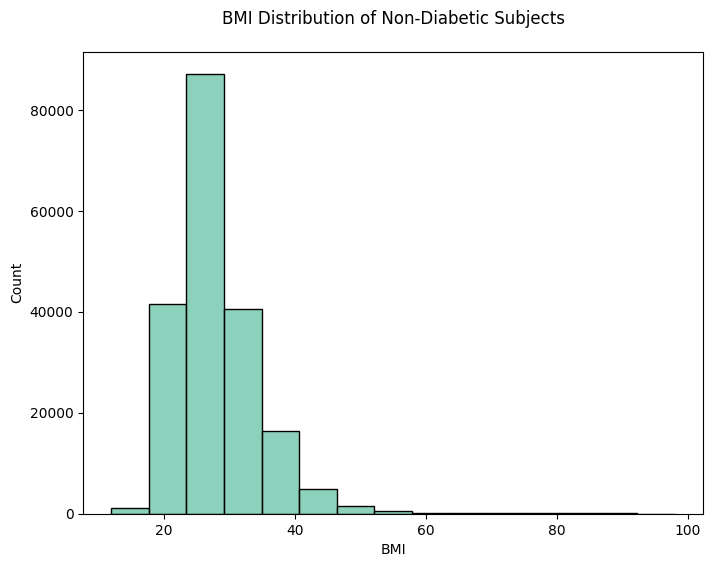
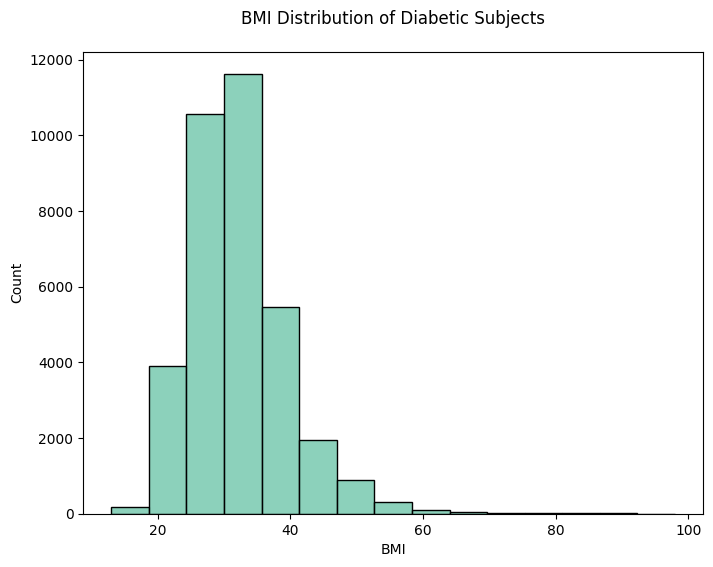
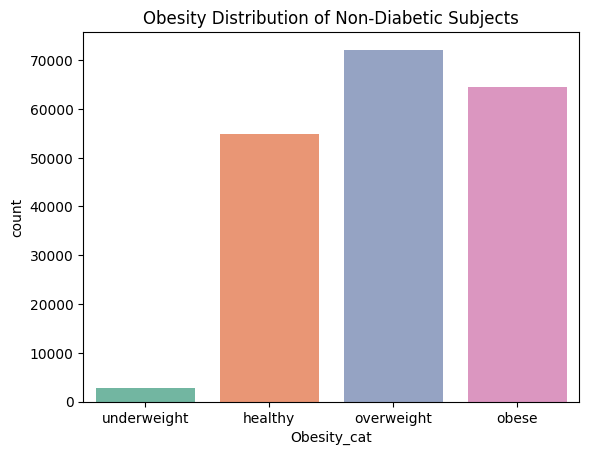
지금까지는 BMI 지수 그대로 분포를 보고 있었는데 카테고리화하여 분포를 볼 필요성을 느꼈다. CDC의 설문 자료인 만큼 비만의 기준은 CDC기준으로 하여 우선 4개의 카테고리 ('underweight', 'healthy', 'overweight', 'obese')를 추가하였고, 혹시 필요할지도 몰라서 두 개의 binary column을 더 생성하였다. 하나는 overweight 이상인 경우('overweight' or 'obese' = 1)에 대한 binary data였고, 또 하나는 obese 여부에 대한 binary data였다.
| Non-Diabetic | Diabetic |
 |
 |
 |
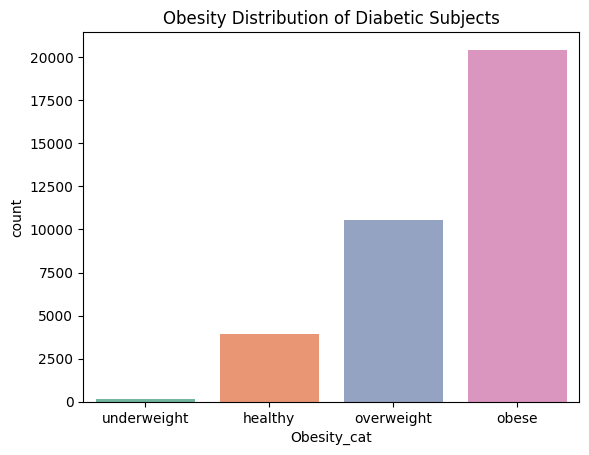 |
직접적인 BMI 분포를 볼때는 보이지 않았는데 카테고리화 하여 분포를 확인해보니 확연한 차이가 있음을 알 수 있었다.
또한 새로 방향을 잡고 로지스틱 회귀를 진행한 결과 9개 변수를 유의한 변수로 판단하였다. ['HighBP', 'HighChol', 'PhysActivity', 'HvyAlcoholConsump', 'GenHlth', 'DiffWalk', 'Age', 'Income', 'Obesity_cat_num']
9개 변수와 몇가지 hyperparameter를 튜닝한 결과 최종 f1score는 0.7611650485436894이 나왔다.
이 결과아 어느 정도 의미 있는 것인지 판단하기 어려워 강사님으로부터 피드백을 받은 결과 추천해주신 방법이 두 가지가 있었는데 그 중에서 '성능에 큰 도움이 되는 변수 하나를 빼고 성능 변화 체크하기'를 시도해보았다.
선별된 9개 변수 중에서도 hyperparameter를 튜닝하는 과정에서나, 도메인 지식을 바탕으로 보나, 'HighBP', 'HighChol', 'Obesity_cat_num'의 중요도가 가장 높은 편일 것으로 판단 되어 이 변수들을 제거한 로지스틱 회귀를 진행해보았고 그 결과 f1 score가 0.7125로 나왔다. 이를 바탕으로 9개 변수를 주요 변수로 선택하는데 무리가 없을 것으로 판단하기로 하였다.
(로지스틱 회귀를 진행한 과정에 대한 기록 : https://hyj89han.tistory.com/80)
변수 선택은 완료되었으니 이제 이를 시각적으로 어떻게 전달할 것인가에 대한 고민이 남았다.
한 조원이 educatioin과 income에 따른 당뇨병 여부를 보이고자 하는 고민이 있었고 이를 바탕으로 아이디어를 얻어 추가적인 플롯을 더 뽑아보았다.
최종결과물
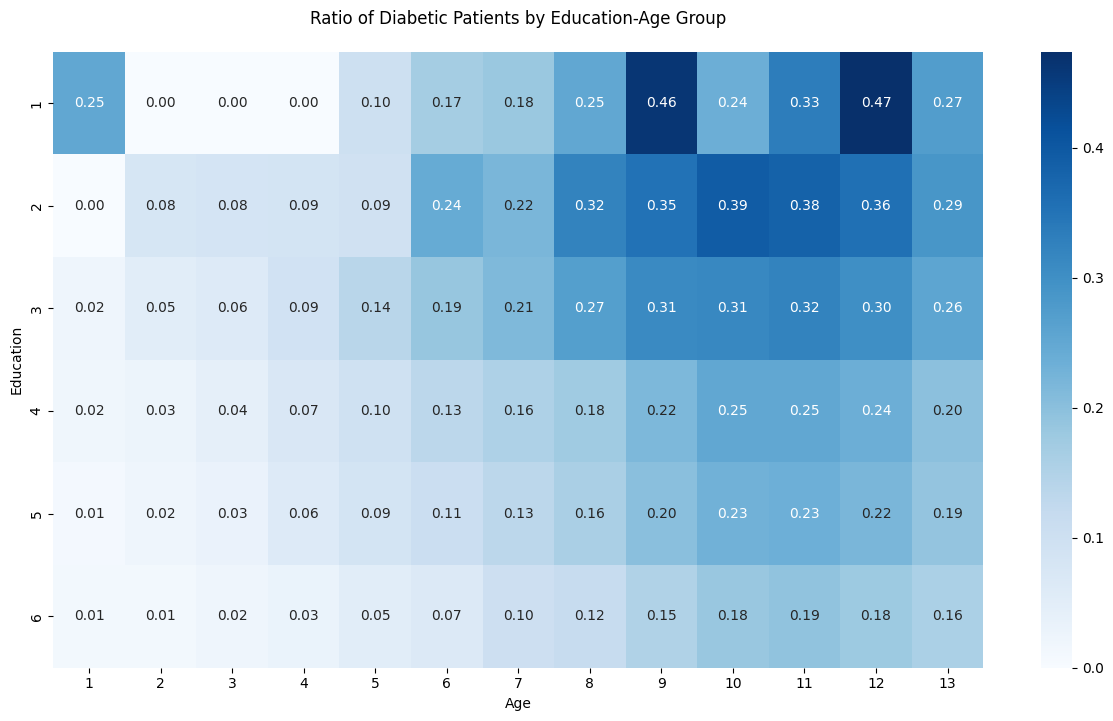
- 연령대가 높아지고 교육수준이 낮아질수록 당뇨병 환자의 비율이 높아지는 경향성을 확인할 수 있음
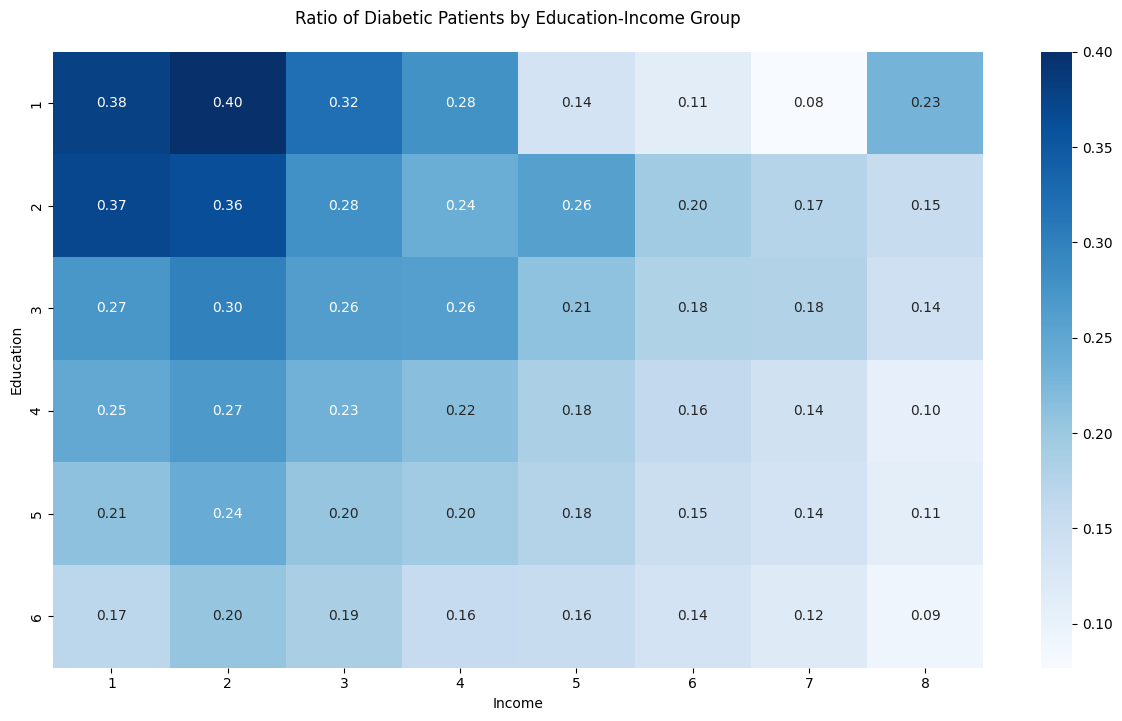
- Education이 낮고 Income이 낮아질수록 당뇨병 환자의 비율이 높아지는 경향을 확인할 수 있음
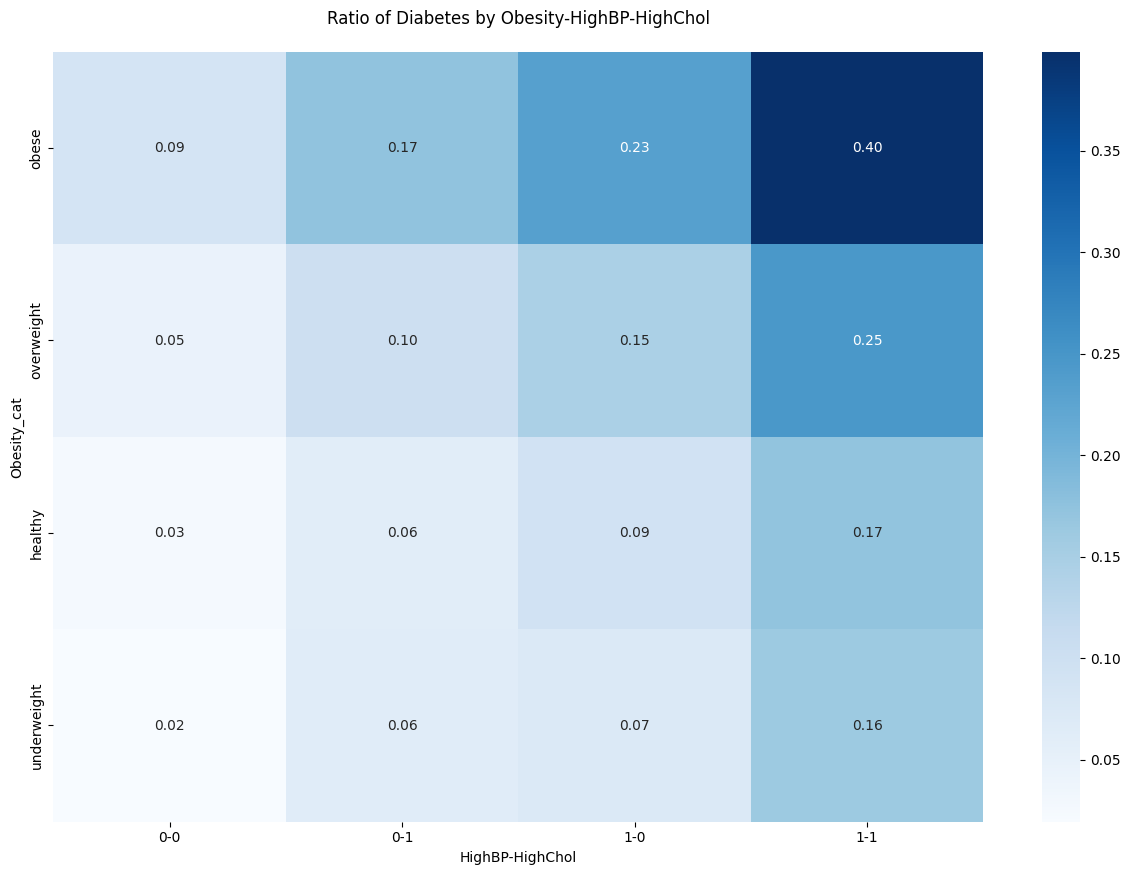
- (로지스틱 회귀 튜닝 과정에서) 'Obesity', 'HighBP', 'HighChol’가 특히 중요한 변수들로 판단되어 세 변수를 기준으로 당뇨병환자의 비율을 확인해본 결과 비만도 증가+고지혈증+고혈압의 조합으로 갈수록 당뇨병 환자의 비율이 높아지는 것을 확인 할 수 있음
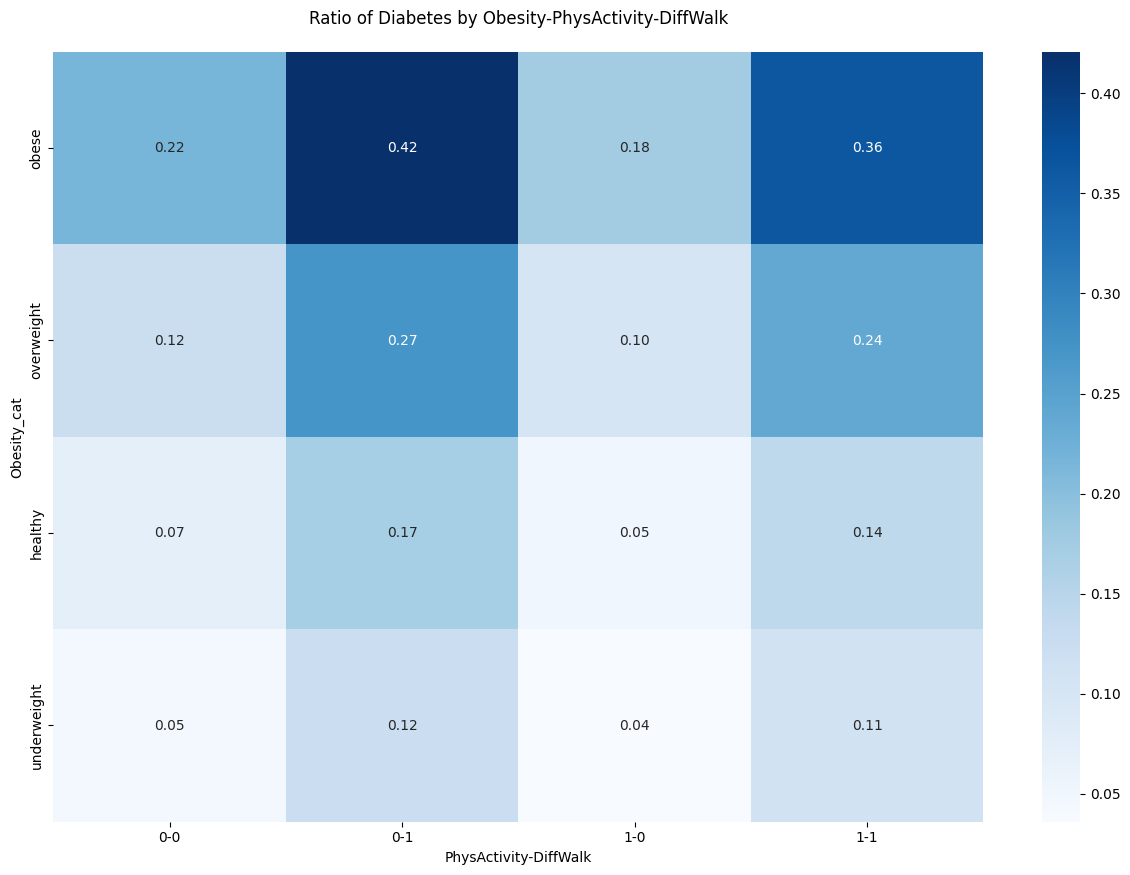
- PhysActivity의 영향은 적은 것 같음, 걷기 힘들고 비만일수록 당뇨의 비율이 높았음
- PhysActivity의 영향보다는 DiffWalk의 영향이 더 큰 것으로 보임
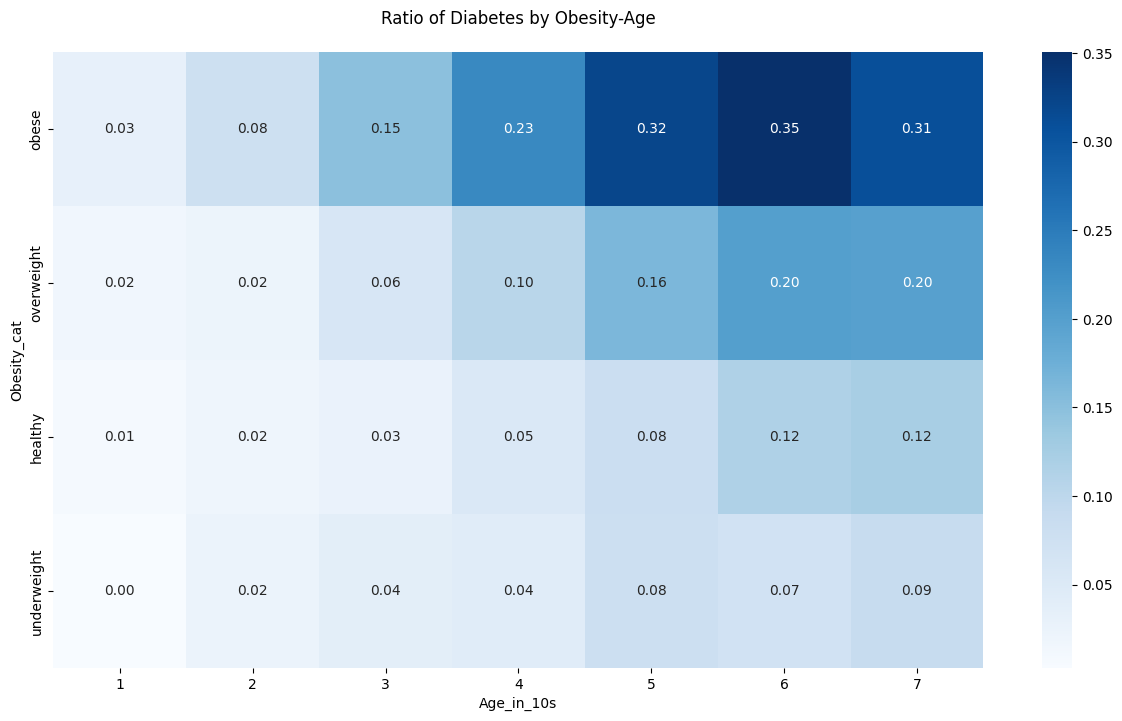
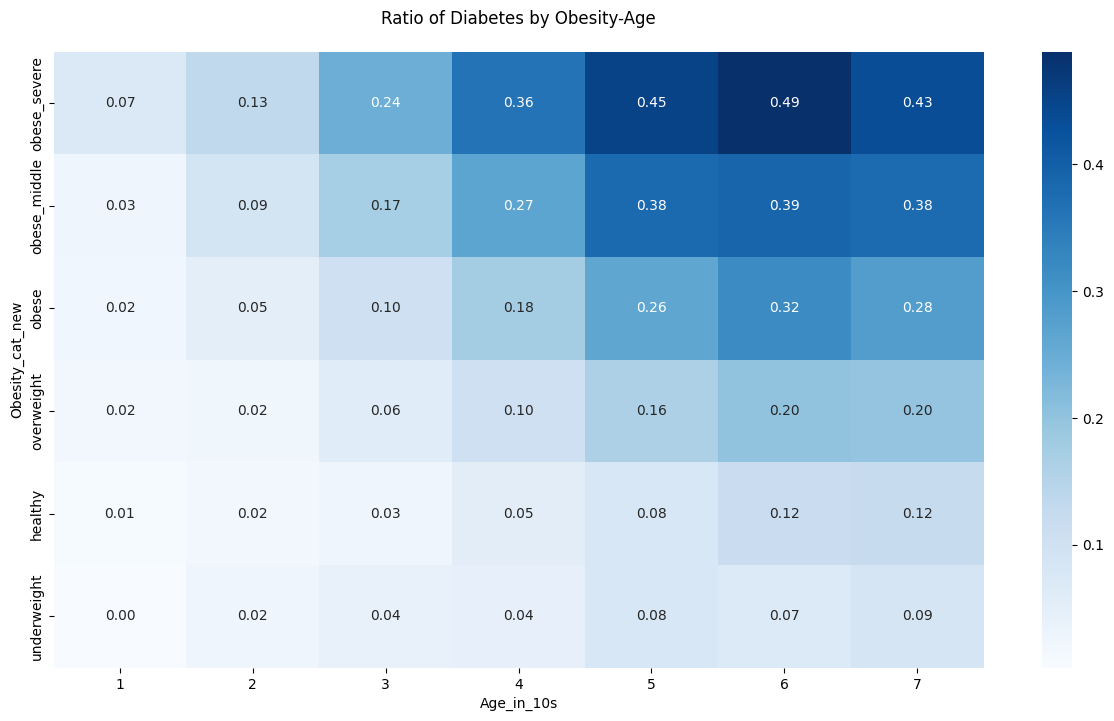
- 나이가 증가하면서 비만도도 증가하고 당뇨병 환자의 비율도 증가하는 경향을 확인할 수 있음.
코드 정리에만 3일이 넘게 걸렸던 것 같다. 아웃라인만 봐도 내 번뇌의 시간만큼 마크다운이 엄청 줄줄이 늘어나 버렸다.
과제를 마무리 하며
1. 어려웠던 점 (1)
그 전까지 내가 진행했던 연구과제들은 주어진 연구목적이 명확해서 EDA는 진짜 초반에 아주 간략하게 막대그래프나 박스플롯을 찍어보는 수준의 EDA였었다. 그렇다보니 보통 EDA에만 집중하기 보다는 아주 기본이 되는 플롯들을 찍어보고 연구를 진행하다 필요한 플롯을 추가로 더 출력하는 식으로 진행했었다. 그래서 본 EDA 프로젝트를 통해 두 주나 할애하여 만들어내야 하는 결과물이 무엇인지 명확하게 감을 잡는 것이 어려웠다. 또한 보건학계와 연계하여 연구를 진행해본 적은 있어서 당뇨병과 유사한 아동 비만, 아동 활동성 등에 대한 연구를 해본 적은 있어서 본 당뇨병 자료를 읽는 것 자체는 어렵지 않았지만 보다 생물학 관점에서는 어떤 결론을 도출해내야 하는지 감을 잡기가 조금 어려웠던 것 같다. 각자의 도메인 지식으로 한정되어 자료를 보고 있는 것이 느껴지는 부분도 있었다.
2. 어려웠던 점 (2)
나 또한 아직도 판다스, 넘파이 함수를 아주 매끄럽게 사용하지는 못하지만, 한쪽으로는 AI 석사를 한 조원과 코드를 아주 깔끔하게 정리할 줄 아는 조원이 있었고 다른 한쪽으로는 거의 코딩이 처음인 조원들도 있었다. 나는 딱 그 중간 정도의 위치였는데, AI석사를 한 조원이 본인이 익숙한 과제 진행방향을 주장할 때, 코딩이 처음인 조원들은 아예 무슨 소리인지 몰라서 초반부터 팀플이 산과 바다를 향해 각자 열심히 나아가는 느낌이었다. 조용히 숨어지내고 싶었지만 이대로는 아무런 결과도 내지 못할 거란 직감에 결국 내가 나서서 교통정리를 해야 했다. 조용히 코드를 실행해보며 연구의 방향을 잡는 한 조원과는 개인적으로 dm을 주고 받으며 진행방향에 대해 논의해야 했고, 내가 궁금한 부분을 해결하는 와중에 아예 코딩이 매끄럽지 못한 다른 조원을 개인 과외하듯 체크를 해야했다. 체력적으로 많이 힘들었던 부분이었다. 하지만 덕분에 남겨지는 사람 없이, 그리고 제법 만족스러운 결과물을 낼 수 있었다. 체력적으로 엄청 많이 힘들었지만 그만큼 보람이 있었다.
3. 더 진행해보면 좋았을 것들
우리가 사용한 당뇨병 데이터셋은 미국 CDC에서 매년 진행하는 BRFSS(The Behavioral Risk Factor Surveillance System)에서 수집하는 자료로, 연단위로 데이터가 누적되기 때문에 특정 피험자에 대한 시계열 분석은 할 수는 없지만 조금 더 macro한 레벨에서의 시계열 분석이 가능한 데이터이지만 아쉽게도 거기까지 우리가 진행하지는 못했다. 후에 사이드프로젝트를 진행하게 되거나, 다른 과제를 진행하게 될때 이런 부분까지 커버할 수 있게 되면 좋겠다.
앞으로의 목표들
단기 목표
git 협업 복습하기
git에 TIL 만들기
중기 목표
(2.5년차 팔로업 검사 이후) 개인 사이드 프로젝트 시작해보기
핸드북 만들기 작업 시작해보기
장기 목표
numpy로 수식 구현해보기
3개월차부터 팀 사이드프로젝트 구상해보기
'패스트러너 기자단 4기' 카테고리의 다른 글
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #06_미니 프로젝트 - Upstage 경진대회 #1 (0) | 2024.04.04 |
|---|---|
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #05_그룹스터디 (1) 첫번째 그룹세미나 (0) | 2024.03.18 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #04_미니 프로젝트 (3) ML 프로젝트 (0) | 2024.03.03 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #03_2개월차 후기 (0) | 2024.02.10 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #01_미니 프로젝트 (1) 크롤링 실습 (0) | 2024.01.04 |



