#00_1개월차후기
'네? 방금 뭐가 지나간거죠?' 하는 마음으로 쏜살같이 흘러가버린 4주였다.
부트캠프를 지원하기 직전까지 자료구조를 공부한다고 (python도 제대로 못 쓰면서) java를 공부하고 있었다.
부트캠프 지원시 코딩테스트를 봐야한대서 부랴부랴 java랑 python을 왔다갔다 하면서 공부를 했는데 될 턱이 있나. 동시에 프랑스어와 스페인어 처음 배우면서 DELE를 준비해야하는 상황같았다.
부트캠프 시작 직전까지도 전공 관련 원고작성 의뢰랑 번역업무를 처리하다 보니 아직 python을 위한 뇌가 활성화가 되지 않은 채 부트캠프를 시작해버렸다. numpy 명령어였는지, pandas 명령어였는지 헷갈려 죽겠는 와중에 java의 여파로 줄마다 ;를 찍는 습관이 남은 채 그렇게 정신없이 2주가 지났는데 갑자기 개인 프로젝트를 해야한다고.... (네? 어떻게요?)
심지어 API활용하는 방법이나 DB 사용이나 Flask 사용은 제대로 숙지도 안 된 채 개인프로젝트를 진행했다.
일단은 크롤링부터 익숙해지자, 그러고 API랑 DB사용이랑 Flask를 익히자.
(그리고 API, DB, Flask는 안드로메다로.....)
#01 개인 프로젝트 : 크롤링 실습
크롤링이라는 개념이야 알고는 있었지만 구현해보는 것도 처음이었고 selenium과는 아예 초면이었다.
급작스럽게 마주한 개인프로젝트에 너무 당황했었다. 기억나는대로 코드를 치고, 에러가 뜨고, 다시 검색해서 코드를 고치고, 진짜 엉망진창이었다. 이 스크린샷은 제출용으로 정리한 폴더이고 원래는 버전만 6까지 가고, 휴지통도 가득 채웠다.

만들고자 했던 프로그램은 ICML에서 매년 주최하는 컨퍼런스에 제출된 페이퍼들의 제목, 저자, 그리고 초록까지 모두 스크랩 한 뒤 초록으로부터 학습과정을 거쳐 연도별 키워드간 네트워크 변화를 보여주는 자료를 만들고 싶었으나 초짜에게는 너무도 멀고 험한 길이었다.
원래 목표
1. 매년 컨퍼런스가 진행된 시점인 2004년부터 2023년까지 연도별로 페이퍼의 제목, 저자, 초록 크롤링
2. 연단위로 초록에 대한 러닝을 통해 키워드간 네트워크 도식화
3. 연도별 키워드간 도식의 변화 구현
4. 슬랙으로 전달하기
실질적으로는.... 전부 실패한 셈.

작업시작
아직 크롤링이 익숙하지 않은 관계로 일단 2023년 페이퍼들의 제목과 저자를 크롤링하는 연습부터 하고 연도범위를 확장하기로 했다. 페이퍼 초록도 테스트 삼아 한건 크롤링해보는 것부터 시작해보았다.
직면한 문제점
1. paper를 리스트업 해둔 페이지의 주소 서식이 다름
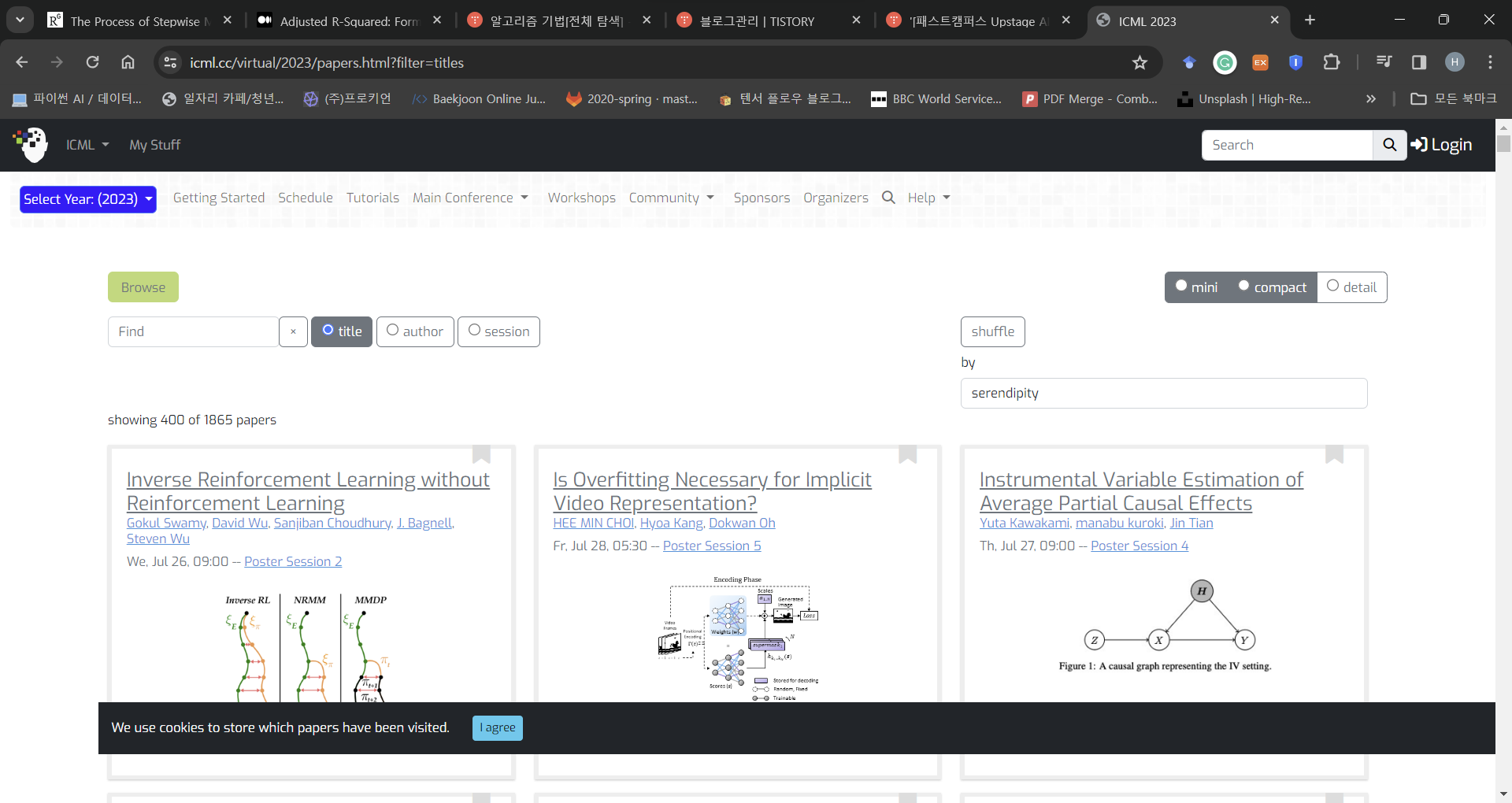
2023년도 컨퍼런스의 페이퍼 리스트업 주소가 https://icml.cc/virtual/2023/papers.html?filter=titles
이니 연도 부분만 f-string을 이용해서 2004년부터 for문으로 불러올 수 있을 줄 알았다. 체크도 해보지 않고 for문을 돌렸는데 2020년 이전 컨퍼런스 페이퍼 리스트의 주소는 형식이 달랐다. 내 능력으로 커버할 수 없는 부분이라 2020년 이전은 쿨하게 포기하기로 했다.
2. Dynamic Web Page
이 부분이 진짜 골치가 아픈 부분이었다.
일단 bs4만으로는 크롤링이 안되고, 페이퍼 리스트로 접근하는데 로딩이 오래 걸려서 wait를 걸어놓지 않으면 아무것도 크롤링이 안 되었다.
wait = WebDriverWait(browser, 60)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'pp-card')))
그리고 가장 큰 문제는 icml 페이지 자체에서 한번에 로딩되는 페이퍼 갯수를 400개로 제한해두어서 전체 리스트를 가져오는 것까지는 역시 능력의 한계로 포기해두었다. 하지만 진짜 문제는 400개만 가져오기로 한다고 해도 shuffle - serendipity 필터가 자체적으로 걸려있어서 접근할때마다 랜덤으로 400개의 페이퍼가 로딩된다는 것이었다. 그래서 코드를 테스트하기 위해 실행할때마다 결과가 누적이 안되고 계속 새로고침하는 셈이라 다음안으로 넘어가려면 타협안이 필요했다. 결국 제목, 저자, url을 크롤해와서 csv로 저장한 뒤, 초록 크롤링은 csv에 저장한 url을 가지고 작업하기로 수정했다.

이 다음단계는 csv로부터 url을 가져와서 400개 페이퍼의 초록을 모두 크롤링하고 바로 키워드 분석을 해서 csv의 Keywords 컬럼에 추가하고 싶었는데, 또 Dynamic 웹페이지가 말썽이었다.
처음 돌렸을때는 한시간이 훨씬 넘게 걸렸는데 결국 400개 중 태그가 잘못된 페이지들이 있거나 로딩이 너무 오래 걸려서 크롤링이 안 된 페이지들이 있어서 초록 리스트가 urllist csv와 길이가 맞지 않았다. 일단 태그가 잘못되어 있는 경우에 대해 if-else 문으로 수습해보았다.
def get_abstract(url) :
time.sleep(3)
browser = webdriver.Chrome()
browser.get(url)
time.sleep(3)
wait = WebDriverWait(browser, 60)
wait.until(EC.presence_of_element_located((By.ID, 'abstractExample')))
soup = BeautifulSoup(browser.page_source, 'html.parser')
abstract_element = soup.find('div', {'id': 'abstractExample'})
if abstract_element.find('p') is not None :
abstract = abstract_element.find('p').text.strip()
else :
abstract = abstract_element.text.strip()
return abstract
그리고 2020년부터 2023년까지 연도별 400개씩을 모두 크롤링하려면 결국 AWS의 도움이 필요하다는 것을 받아들여야 했다. 그러나 시간관계상 AWS RDS database를 공부하다가 멈춰야 했다. 어쨌든 보여줄 수 있는 결과물을 만들어야 하니까. 이 지점으로부터 두 개의 분기점으로 나누어 작업을 진행하였다.
- a. 크롤링한 제목들로부터 연도별 워드클라우드 생성
- b. 크롤링한 urlilst에서 랜덤으로 선택하여 abstract에 접근, 키워드 추출작업 진행
# 1 - 1. 연도별 워드클라우드 생성
워드클라우드 또한 처음 써보는 상황이라 워드클라우드를 먼저 테스트 해보는 것으로 작업을 시작했다.
처음 돌려보니 stopword를 추가하지 않아 Learning, Model 등의 단어가 대문짝만하게 나왔다.
당연한 결과였다. Machine Learning 컨퍼런스이니까요.....
 |
 |
 |
 |
학습을 통해 무의미한 단어들을 제거하면 좋았겠지만 머릿속 어딘가에 숨어있는 ML 코드를 찾아낼 여유가 없었다. 일단 직관에 의존해 stopword를 추가하기로 했다.
from wordcloud import WordCloud
from wordcloud import STOPWORDS
# define stop words
stop_words = set(STOPWORDS)
exclude_words = {'learning', 'machine', 'via', 'model'}
stop_words.update(exclude_words)
이 부분을 새로 만들어 create_wordcloud.py 안의 코드에 추가하였다.
그 결과 다음과 같은 워드 클라우드를 생성하는데 성공했다.
 |
 |
 |
 |
반복되는 Graph는 자료구조로써의 Graph를 의미하는 것인지 도표로써의 Graph인지 파악할 수 없어 제거하지 않았다.
# 1 - 2. 초록 키워드 추출
키워드 추출은 nltk 라이브러리를 사용해보기로 했다.
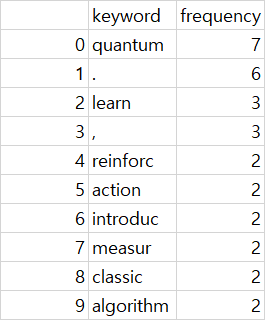
검색했던 한 웹페이지에서는 PorterStemmer()를 추천해서 실행해보았으나 다음과 같은 결과가 나왔다. 당연히 punctuation은 제거해줄 줄 알았는데... 일단 stopword와 stemmer들을 샅샅이 뜯어보며 몇번의 실험을 거쳐야 했다.
| 2023_71 | 2023_12 | 2023_114 | 2023_52 | 2023_125 | 2023_57 |
 |
 |
 |
 |
 |
 |

stemmer들은 복수형 단어를 수정해주고 -ion등의 어미들을 떼어내는 식이었기 때문에 결국 WordNetLemmatizer()를 사용하기로 정했다. 일단 급한대로 punctuation을 수동으로 stopword에 추가했고, 몇개의 단어 또한 수동으로 추가하여 다음과 같은 결과를 얻었다. 결과가 조금 아쉽긴 하지만 혼자 이 정도 단계까지 간 것에 만족하기로 했다.
| 2023_12 | 2023_52 | 2023_57 | 2023_71 | 2023_114 | 2023_125 |
 |
 |
 |
 |
 |
 |
README.md
## 파이썬 Flask
> mkdir upstage-flask-backend_re
> cd upstage-flask-backend_re
### 가상환경 구축
> python -m venv .venv
### 가상환경 activate
### windows
>.venv\Scripts\activate
### requirements.txt 생성
> pip freeze > requirements.txt
##### to test in future
> set lambda function to crawl all 400 abstracts of each year's conference
> utilize RDS to save crawled data in db
> from these crawled abstracts, extract keywords and create wordcloud
> compare wordclouds from titles vs. keywords
> try sending wordcloud images and keywords via slackbot
'패스트러너 기자단 4기' 카테고리의 다른 글
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #06_미니 프로젝트 - Upstage 경진대회 #1 (0) | 2024.04.04 |
|---|---|
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #05_그룹스터디 (1) 첫번째 그룹세미나 (0) | 2024.03.18 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #04_미니 프로젝트 (3) ML 프로젝트 (0) | 2024.03.03 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #03_2개월차 후기 (0) | 2024.02.10 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #02_미니 프로젝트 (2) EDA 조별 프로젝트 (+ 1.5개월차후기) (0) | 2024.01.18 |



