Upstage AI Lab 2기
2024년 1월 18일 (목) Day_027
Day_027 온라인 강의 : 선형회귀분석
더보기
Part.3 통계로 데이터 분석 능숙해지기
Chapter.05 선형회귀분석
| CH05_01. 단순 선형회귀분석 | 0:07:41 | 01/18 (Thu) | 1:27:04 |
| CH05_02. 다중 선형회귀분석 | 0:12:39 | ||
| CH05_03. 선형회귀의 기본적인 가정 5가지 | 0:12:39 | ||
| CH05_04. 다중 선형회귀분석 미니 프로젝트 | 0:54:05 |
CH05_01. 단순 선형회귀분석
독립변수(x)로 종속변수(y)를 예측하는 것
CH05_02. 다중 선형회귀분석
CH05_03. 선형회귀의 기본적인 가정 5가지
오차(Error) : 모집단 회귀식 (예측값 - 관측값)
잔차(Residual) : 표본집단 회귀식 (예측값 - 관측값)
- 선형성(Linearity)
- 잔차 정규성
- 독립성 (only 다중선형회귀)
- 다중공선성(Multicolinearity)
- 등분산성
CH05_04. 다중 선형회귀분석 미니 프로젝트
from sklearn import preprocessing
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from statsmodels.stats.outliers_influence import variance_inflation_factor
MinMaxScaler() : 0 ~ 1
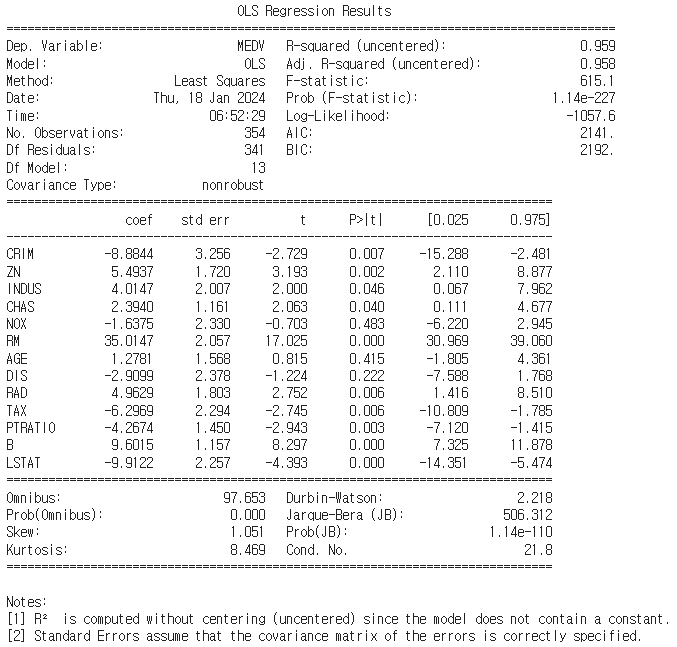
m_reg = sm.OLS(train_y, train_X).fit()
OLS(Ordinary Least Squares) Regression
min_max_scaler = preprocessing.MinMaxScaler()
scale_columns = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
df_x[scale_columns] = min_max_scaler.fit_transform(df_x[scale_columns])
train_X, test_X, train_y, test_y = train_test_split(df_x, df_y, test_size = 0.3)
m_reg = sm.OLS(train_y, train_X).fit()
print(m_reg.summary())
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(train_X.values, i) for i in range(train_X.shape[1])]
vif["features"] = train_X.columns
vif.sort_values(by='VIF Factor', ascending=False)
'Upstage AI Lab 2기' 카테고리의 다른 글
| Upstage AI Lab 2기 [Day028] 실시간 강의 - 통계(4) (0) | 2024.01.19 |
|---|---|
| Upstage AI Lab 2기 [Day026] 실시간 강의 - 통계 (3) Statistical Learning (0) | 2024.01.18 |
| Upstage AI Lab 2기 [Day026] 실시간 강의 - 통계 (2) 머신러닝의 통계적 학습 (0) | 2024.01.18 |
| Upstage AI Lab 2기 [Day026] 온라인 강의 - 기초통계 (3) 실습 (0) | 2024.01.17 |
| Upstage AI Lab 2기 [Day026] 실시간 강의 - 통계 (1) 통계 톺아보기 (0) | 2024.01.17 |



