특강 #01. [AD] Anomaly Detection 대회 특강
강사 : 신종선 (마키나락스)
일자 : 2024년 6월 18일 (화)
MakinaRocks : 제조업 도메인
제조업에서 발생하는 문제들에 대한 이상 탐지 및 최적화, 강화학습.
센서데이터 : 정형 & 시계열 데이터
MLOps for all (https://mlops-for-all.github.io/en/)
ML Engineer를 위한 MLOps(https://mlops-for-mle.github.io/tutorial/)
정상 데이터와의 유사도에 따라 Novelty Detection, Anomaly Detection, Out of Detection.
- "이상"을 정의하는 정도에 따라 달라짐.
시계열 데이터에서 이상치를 통계모델로 찾기는 어려움
대회 소개
대회 데이터 : 25만 row, 55 columns
fault가 난 run을 찾는 문제로 정의
simulator에서 나온 데이터 (real world data는 아님)
fault 0 은 정상, 1은 비정상
50여개 센서로부터 얻어진 데이터
학습데이터는 모두 정상 데이터만 존재
현실에서도 고장 데이터는 극히 드물다.
Unsupervised learning 으로 접근하길 기대함
고도화된 모델을 쓰진 않아도 성능이 나오더라
시도해보면 좋을 것들
1. 데이터 분석 : t-SNE Scatterplot
데이터 분석을 먼저 시작하면서 얻어지는 인사이트도 있다.
모델링보다 데이터 기반 인사이트 → 전처리 → 성능 향상 폭 ↑
유의할 것 : Run 단위로 정상/비정상이 나뉨
2. 다양한 모델
- 전통적인 모델 : PCA, SUM, KNN 등
전통적인 모델로도 성능이 꽤 괜찮음.
- Autoencoder + LSTM layer
- Anomaly Detection Library도 많음
설령 결과가 안 좋더라도 배우는 게 있을 것이다.
실적용 사례
어떻게 시스템을 구성했고, MLOps적 특성
- 레이저 드릴 장비의 이상탐지
범용적 모델로는 안 되더라. 공정, 장비에 따라 특화된 모델이 있음
특화모델 → 학습 → 배포의 싸이클
일반적 DL/ML과 다름
운영중인 공정에 적용하려면.... 이상데이터도 적고 시의성도 프로젝트마다 다를 수 있음
그리고 성능 재현이 안 될 수도 있다.
해결방안 : 싸이클을 빠르게 만들자! (빠르게 분석/재학습/배포 + MLOps)
실시간으로 데이터가 쌓임.
고장이 나서 중단되면 거대한 손실 ∴ 실시간성이 중요
이상 시 alert가 전송되는 방식.
이상을 사전에 탐지하여 고장을 방지할 수 있도록 함
Autoencoder unsupervised learning
(이상탐지에서 많이 학습하는 방식)
복원 오차가 0으로 잘 수렴하는지.
복원 오차를 Anomaly score로 계산
구글에서 정의한 MLOps level
Level 0 → Level 1 추가된 개념 : pipeline
실험과 배포의 pipeline이 같게 표준화된 pipeline. (Docker 또는 Kubernetes)
표준화가 필요한 이유 : 성능 재현이 가능해야함
누가 실행해도 같은 결과가 나오고 성능 재현이 가능해야 함. (회사 입장에서 매우 중요!)
MLOps Level 1 : Training Pipeline
Kubeflow Pipline Run ↔ MLflow Run
잘 만들어 두면 학습부터 배포까지 기록이 잘 됨.
mlflow 에 model registry
배포는 Seldon Core
MLOps : Kubeflow → MLflow → Seldon Core
오알람을 줄이니 성능이 올라감
싸이클이 느리면 성능개선이 느려지더라.
dashboard 를 좀 더 직관적으로 만들었더니 만족도가 높아짐
Boyd's OODA Loop
하나의 싸이클을 완벽하게 도는 것보다 자유롭게 왔다갔다 할 수 있는게 고도화시킬 수 있는 방향
(i.e. 제출 횟수를 늘려라......)

마음가짐 :
해를 거듭할수록 취업시장에서 요구하는 능력이 높아지고 경쟁도 치열해짐.
그럼에도 불구하고 열심히 공부하고 있음에 존경스럽다.
기업에서 요구하는게 많다.
특강 #02. [OCR] Intro to OCR & LA API Practice 특강
강사 : 김다현 (Upstage)
일자 : 2024년 6월 13일 (목)
OCR과 LA의 차이
언제 OCR 또는 LA를 쓰면 좋은지
REST API : API 사용의 패러다임
개발자가 직접 다 구현하지 않고 원하는 URL endpoint를 넣어 원하는 기능을 사용함
client -> HTTP -> URL (endpoint) -> server
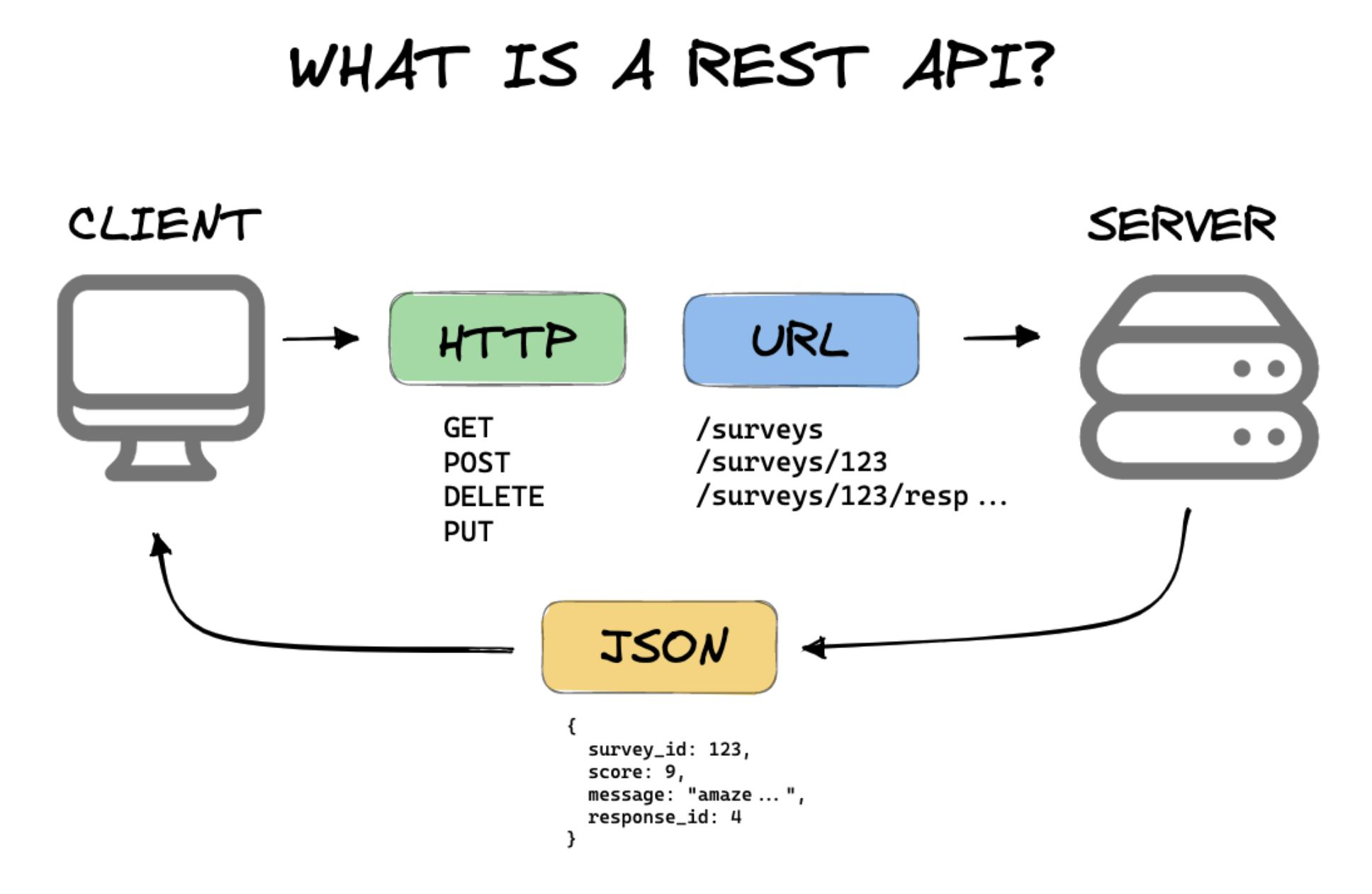
HTTP verb : 요청에 해당하는 동사. API 기능을 한 단계 추상화
GET (read), POST (create), DELETE, PUT & PATCH (update)
Body message - optional
Request에 대한 status code
400 번대 - 클라이언트 측 문제
500 번대 - 서버쪽 문제. (내가 할 수 있는 건 없음. ㅋㅋ)
OCR -> Detector -> Recognizer
기업 - 서류 작업
cURL - command line으로
구글 OCR 포맷과 같은 형식으로도 받을 수 있음 (캐릭터 단위로 읽음)
cURL은 보통 테스트용으로 쓰임
params = {"schema" : "google"}
보통은 python requests를 이용함
multi-threading(concurrent) - API 마다 호출 횟수 제한 있을 수 있음
재시도 코도는 LA 실습에 있음
for 문도 too many request 에 걸릴 수 있어서 time.sleep(1)
bounding box 좌표를 바꿔줌
API 결과상 신뢰도가 낮은 건 표시 x
conf_high_prediction
conf_high_print_cnt
confidence 가 같이 출력되는 것이 장점
(6/11에 모델 업데이트 됨)
내가 원하는 기능이 이미 API로 구현되어 있는지 알고 있는게 좋음
LA (Layout Analyzer)
OCR은 몇 번째 문단, 몇 번째 문장인지 인식하지 못함
문서가 복잡하면 (예를 들어 표가 포함된 경우) OCR 만으론 부족
예를 들어 논문 같은 two column의 경우..
LLM 시대라 LA가 더 중요해짐. 최근 중요성이 더 커짐.
layout 보존을 위해...
번외로 data curation 말고도 RAG에도 활용 가능
HTML 형식으로 표현
(개인적 소감 : 오 아이디어 대박이다)
구조적인 정보가 살아있는 텍스트를 이용하기 유리함.
룰기반이 어렵다보니 LA 상품이 나오게 된 것 같다.
폰트 크기도 인식하고 그것에 대해 추가 작업도 가능
(초반에 publaynet 기반으로 작업하기는 했음)
arxiv_qa 데이터
hugging_face : map이 잘 구현되어 있음.
num_proc : 멀티 프로세싱
request status에 대응해서
response.raise_for_status() : 에러 발생시 except로 넘어감
API 없이 개발은 어려운 생태계가 됨.
LA의 기반도 OCR이다.
Document Understanding이라는 분야가 있음.
- 문서 이해를 Q&A로 끌고 오는 분야
LA 모델의 성능평가는 어떻게?
진짜 잘 평가하려면 test set 구축이 잘 되어야 함.
정형화된 벤치마크는 없음.
아직 performance saturation은 잘 안 된 것 같다.
조언 : 기술이 빠를수록 근간이 되는 걸 놓치지 않아야 넘어지지 않을 수 있다.
특강 #03. [RecSys] Overview of RecSys & The Concepts of Uninteresting Items 특강
강사 : 김윤기 (Upstage)
일자 : 2024년 6월 14일 (금)
Uninteresting Items 개념을 소개하고자 함. -> 성능 향상에 도움됨
(강사님 개인 : 석사 추천시스템, 기존에도 추천팀 소속)
| recommendation technique | ||
| recommendation approach | heuristic-based | model-based |
| content-based | TF-IDF | News recommendation |
| collaborative | Item-based collaborative filtering | Matrix factorization |
| hybrid | ensemble | |
아직 평가하지 않은 아이템에 대한 선호도를 추론
1. content-based filtering
평가했던 item과 유사한 item 추천
필요한 것 : Item profiles, User profiles, similarity metrics
Item profiles : text 로 표현 됨. description, review 등. TF-IDF
User profiles : 평가했던 모든 items의 TF-IDF의 평균 벡터
similarity metrics : cosine or Pearson correlation
장점 : 직관적
한계점 :
1. limited content analysis - 이미지와 비디오에 대한 profile을 정의하기 어려움
2. overspecialization : 좋아할 "가능성"이 있는 건 추천 어려움
3. New user problem : 평가했던 item이 없는 상황에 추천 어려움
2. collaborative filtering
유사한 취향을 가진 이웃들을 찾기
1. 선호 아이템이 겹치는 유저를 찾기
2. 이웃들이 선호한 상품을 추천해주기
- user-based / item-based : 이웃을 item side 에서 찾을지, user side 에서 찾을지
User-based collaborative filtering
user c 의 itme s 에 대한 평가를 추론
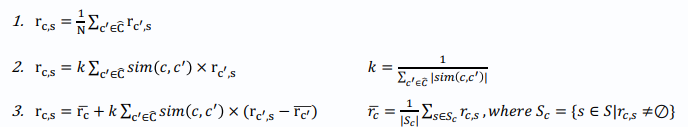
두 번째 평가 metric의 단점 : 유저마다 평점의 평균이 다름
세 번째 metric : 유저마다 평점의 평균이 다름을 반영한 metric
이웃은 어떻게 구하는가? n개 아이템, n-dim의 vector로 similarity 계산
Item-based collaborative filtering
기준이 item이 됨. 축이 달라짐.
Model-based
★ Matrix Factorization (행렬 분해)
why? rating matrix is very sparse
모델 기반의 방법론을 가장 많이 쓰게 됨
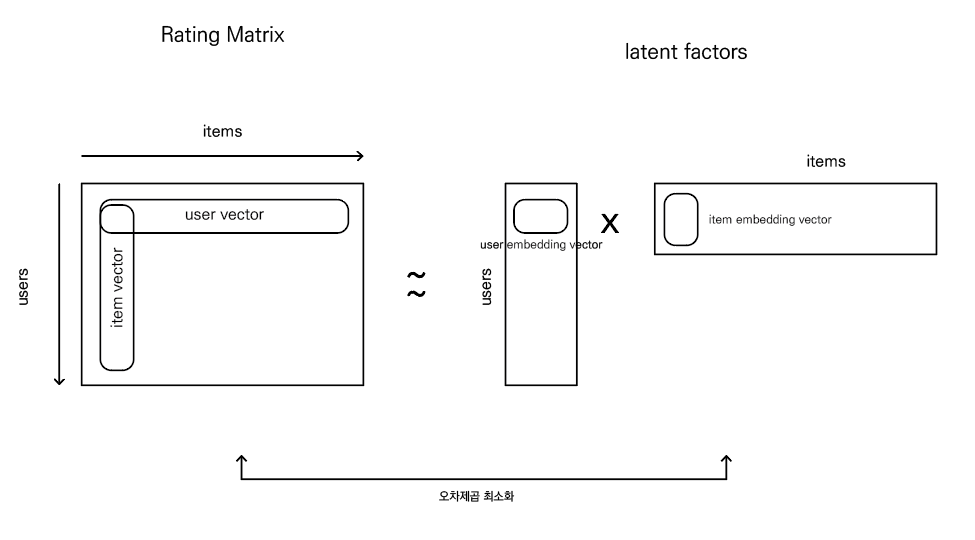
how to train? SGD or Alternating Least Square
( Alternating Least Square 란? user 먼저 업데이트한 후, item 업데이트 하는 방식으로 순차적으로 반복)
학습 자체가 모든 item에 대해 업데이트 할 때, 모든 유저에 대한 모든 요소가 계산에 들어감
한계점 :
1. 결국 cold start problem for both new user and new item
2. Data sparsity of rating matrix - 1% 안되는 경우가 허다함 -> implicit feedback으로 완화 -> 구매를 한 것을 선호한다고 유추
(explicit feedback : rating 점수가 명료)
BPR loss
implicit - 클릭한 것과 클릭하지 않은 것의 차를 최대화 하는 방향으로 loss function 을 정의
RecSys 전반에서의 이슈 :
1. personalization (popularity bias) - 대부분의 경우 more popular -> more preferred (popularity와 personalization 사이의 tradeoff)
2. item fairness - 예를 들어 광고하는 입장에서 user에게 노출되는 정도에 bias가 생김
3. diversity - 다양성이 떨어지면 만족도가 떨어질 수 있음
사용자 만족도는 높이고 provider 입장에서도 fair 해야 함
content-based 는 heuristic만 설명했는데, 어떤 contents (예. 뉴스 추천 vs. 멀티미디어 추천) 를 쓰느냐에 따라 모델 부분이 달라짐.
Part 2. The concept of Uninteresting Item
- implicit에도 허용 가능?
explicit feedback & collaborative filtering일 경우 가장 큰 이슈는 data sparsity
user 의 preference 중 의미있는 추론은...
존재를 몰라서 or 존재를 알지만, 선호하지 않아서 ?
-> 존재를 알지만, 선호하지 않아서 -> uninteresting item의 개념
이걸 학습에 활용하겠다.
굳이 rating을 했다면 either 높은 점수 or 낮은 점수
기존에는 0으로 채워서 학습시킴
사용 전 선호도 (pre-use preference) -> 어떻게 찾죠?
★step 1 : rating이 있는 건 1로 채움 (왜? rating이 있다는 건 post-use preference가 있다는 뜻이니까)
step 2 : pre-use preference를 추론
step 3 : pre-use preference가 낮은 건 0으로 채움
핵심 : pre-use preference와 post-use preference를 구분한다.
-> item 간 유사도 계산이 더 정확해짐
이웃의 정의가 달라짐
theta% 를 zero inject 할 것인가 -> parameter
pre-use preference가 낮은 건 잘라내면서 연산 정확도 up
theta에 민감하지 않음
왜 theta 가 99.7까지인지? metric에 답이 있음. top5가 0.3%에 해당
zero-injection -> collaborative filtering에 다 적용할 수 있음
SVD++ -> rating matrix 를 다 1로 바꾼 방법
즉, 0과 1로만 행렬을 채운 경우
PureSVD는 빈칸을 0으로 채움
-> 최종 추천에서 uninteresting item을 제거해주는 방식으로만
최종 추천 결과에서 filtering만 해줬는데 성능 개선이 있었음. (흥미롭..)
nDCG - 추천 현업에서 많이 쓰는 metric. ranking에 대한 가중치가 있는 metric
MRR은 최근에 잘 사용 안함.
position bias -> nDCG를 높이는게 중요. 선호도에 맞게 상위 노출이 중요함.
어떤식으로 활용 가능할까? rate가 높은 item에 대해 content 정보를 반영하는 방법도 있을 듯
@n의 n값이 커질 때 왜 점수가 올라가는지
-> nDCG recall은 n이 커질수록 높아지는 경향이 있음
precision은 n에 따른 경향은 없는 편
추천시스템에서 사용되는 데이터의 기간
-> 기간을 fix하지 않을 수도 있고, 최근으로 한정할 수도 있음
--> 도메인 특성에 따라 달라질 수 있음.
예) 최근 꺼에 더 weight -> sequential modeling을 하기도
3. Application of Uninteresting Items
① How to impute missing ratings?
Lee, Youngnam, et al. "How to impute missing ratings? Claims, solution, and its application to collaborative filtering."
https://dl.acm.org/doi/pdf/10.1145/3178876.3186159
Item vector와 user vector를 오토인코더 방식으로 학습시키고 latent embedding vector z와 uninteresting item 점수와 concat 해서 MLP layer에 넣어서 rating을 계산
pre-use preference 값 자체를 그대로 사용
-> 왜? pre-use preference 가 잘 예측이 되어있어야 된다는 문제의 여지가 있음.
0점으로 채우는게 맞는가? ->에 대한 연구도 있음
-> item, user, mean 으로 채운 경우가 성능이 더 높게 나온다는 경우도 있었음.
② Graph-Theoretic One-Class CF -> implicit 상황
MF 방식을 그래프로 변환한 경우
Implicit feedback은 pre-use preference에 해당됨
positive graph와 candidate negative graph
seperate graph로 모델링할 수도 있고 signed graph로 모델링할 수도 있음.
GOCCF - 그래프 알고리즘이든, GCN 이든
- signed graph 자체로 추천을 잘 하는게 어려움
- separate : positive와 negative 의 결과를 어떻게 합칠까도 하나의 연구 분야
Rating Augmentation with GAN (RAGAN)
다양한 방법에 uninteresting item이라는 개념을 적용시킬 수 있다.
특강 #04. [RecSys] Introduction to News Recommendation 특강
강사 : 김윤기 (Upstage)
일자 : 2024년 6월 24일
논문 작성 flow를 이해해라
목표
① 뉴스 추천 vs. 상품추천
② 뉴스 추천 성능 향상을 위한 연구
Problem Definition
given : click log, 클릭확률을 예측하여, 클릭 확률이 높은 뉴스를 추천하는 것
user side info : 클릭로그, 체류시간
news side info : 제목, 카테고리, 본문, knowledge graph의 entities
(why knowledge graph? 고유명사는 임베딩으로 표현이 어려움.)
Challenges
1. 뉴스가 너무 많다. - 상품추천보다 어려움
2. Time-sensitive : 짧은 주기 (daily) → user feedback 부족. CF(Collaborative Filtering)기반 방법들이 효과적이지 않음.
3. Diverse User Interest
∴ 개개인의 관심사를 모델링하기 어려움.
Overview of News Recommendation
클릭 할 만한 것을 추천하는 것이 핵심
접근방법
① 클릭로그 + 제목 (① LSTUR ② NPA ③ NRMS ④ UNBERT)
② 클릭로그 + 제목 + 본문 (⑤ NAML ⑥ CAST)
③ 클릭로그 + 제목 + 본문 + 체류시간 (⑦ CPRS)
④ 클릭로그 + 제목 + knowledge graph entities (⑧ DKN ⑨ HieRec)
그렇다면, 클릭하기 전에 본문과 체류시간을 알 수가 없는데 왜 쓰는걸까?
General Framework : News Encoder, User Encoder, Prediction Layer
User's Click Logs → News Encoder → News Embedding → User Encoder → Prediction Layer
Candidate News → News Encoder → → → → → → → → → → → → → → →↑
General Training Method
cadidate news (total k+1 new items)
- 1 positive sample
- k negative samples(negative sampling in the same impression) - uninteresting item과 유사한 개념
cross-entropy loss 학습
Approach 1. 클릭로그 + 제목
① LSTUR ( Long- and Short-term User Representations )
Neural News Recommendation with Long- and Short-term User Representations
https://aclanthology.org/P19-1033.pdf
Long-term interests - user ID embedding
Short-term interests - 최근 클릭 로그 → GRU 사용
user ID embedding 이 왜 Long-term interests 일까?
클릭 로그는 바뀌어도 user ID embedding 은 변하지 않음
News Encoder - 사전학습 word embedding + CNN (context 반영) → then Attention
query - random init.
Ablation study on user encoder
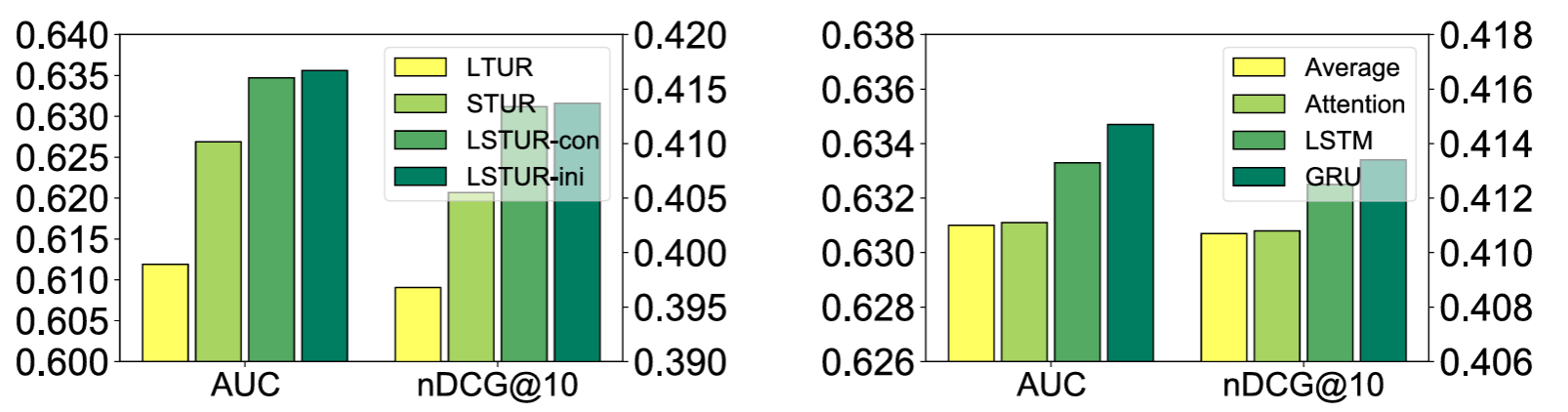
(우) 순서 정보 반영 방법 - Average, Attention, LSTM, GRU
순서 정보가 반영된 게 더 좋았다. -> short-term 모델링에 GRU를 쓴 이유인 셈.
워드 임베딩은 CNN > LSTM, Average < Attention
★ ② NPA( neural news recommendation with personalized attention )
Wu, Chuhan, et al. "NPA: neural news recommendation with personalized attention."
https://arxiv.org/pdf/1907.05559
심플하지만 잘 작성된 논문 - 하나만 읽으라면 이걸 읽으라 추천
① 집중하는 단어가 다름, ② 관심 뉴스 다름
이전의 query random initialize 대신에 attention의 query로 user id를 쓰겠다.
(이전과 같이 key, value는 news embedding을 쓰고)
CNN으로 context 반영
Personalized Title Attention - word 레벨, 뉴스 레벨, both
vanilla - random init query
③ NRMS ( Neural news recommendation with multi-head self-attention. )
Wu, Chuhan, et al. "Neural news recommendation with multi-head self-attention."
https://aclanthology.org/D19-1671.pdf
CNN 대신 멀티헤드 어텐션 - title words, clicked news
motivation이 충분히 설명됨
멀리 떨어진 단어끼리 연관성 (CNN은 local만 보니까)
핵심 : 한 user 가 클릭한 뉴스끼리 연관성이 있다. (이전까지는 뉴스간 연관성을 보지 않음)
(query는 random init)
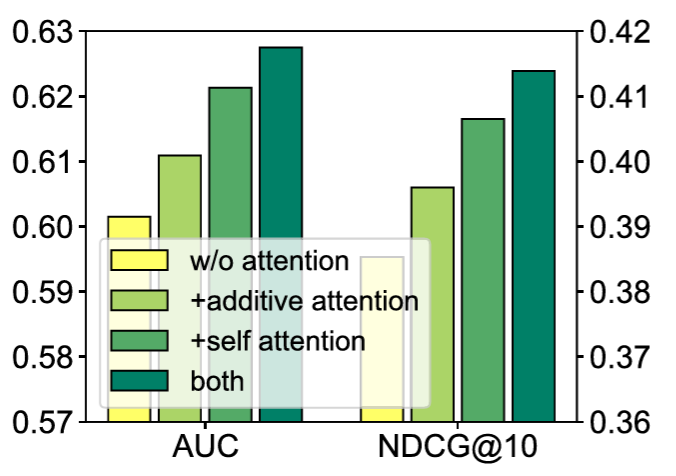
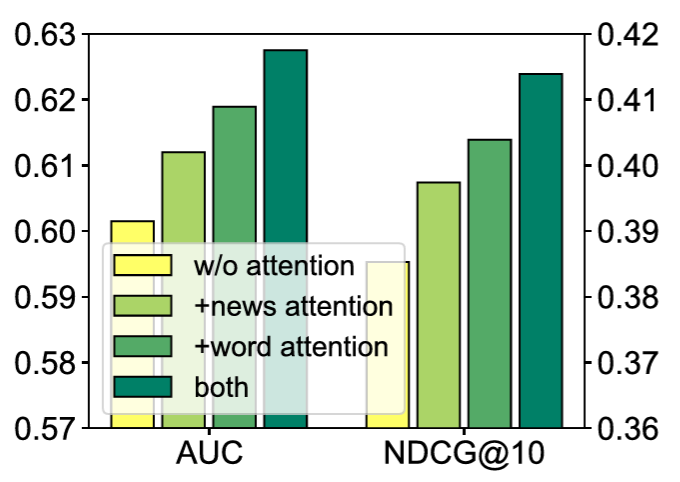
additive - 윗단의 어텐션 aggregated?
self attention은 multihead attention
단어/뉴스 간 self attention (multihead)
중요 단어/뉴스 - additive
④ UNBERT
Zhang, Qi, et al. "UNBERT: User-News Matching BERT for News Recommendation."
https://www.ijcai.org/proceedings/2021/0462.pdf
기존 : user encoder와 news encoder가 별도
motivation : 기존의 방식은 pretrained word embedding의 효과가 상대적으로 작아짐
대안 : pre-trained BERT 사용
기존 : dot-product를 봄
candidate news의 word-level signal을 고려하지 않았음
제대로 된 interest를 반영하려면 word-level matching이 필요
candidate news 와 clicked news를 따로 보지 말자
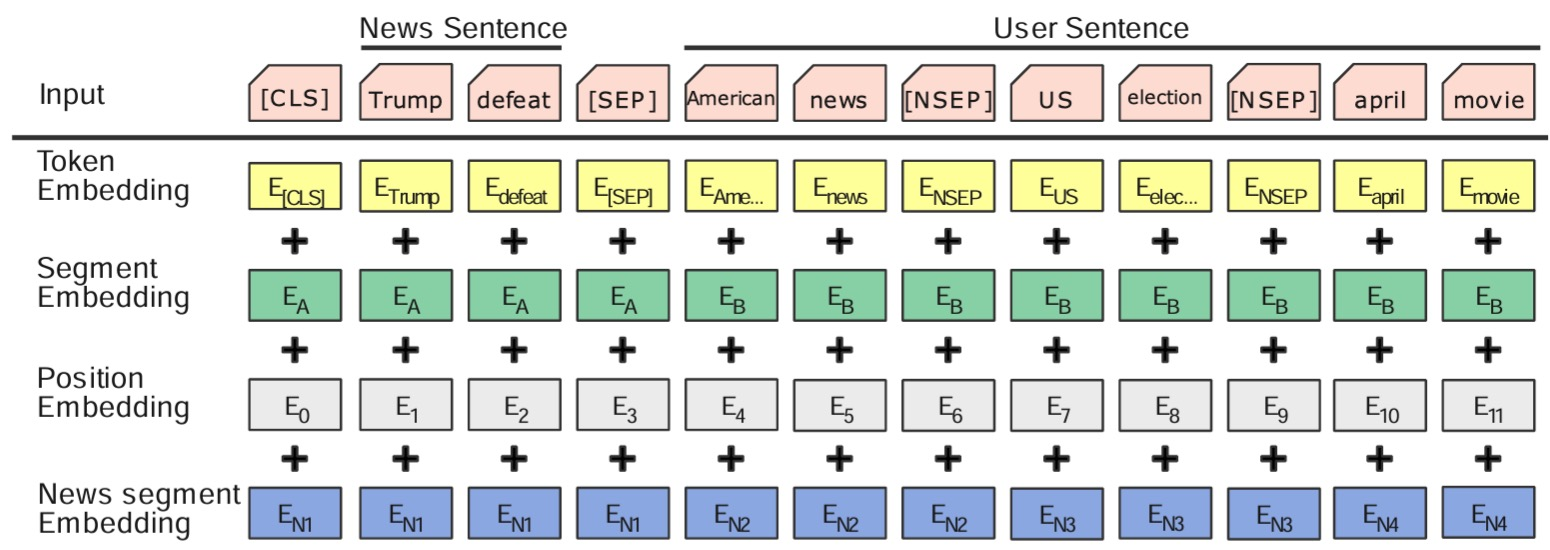
news sentence : candidate news title
user sentence : 클릭 뉴스들의 title. 뉴스간 스페셜 토큰 [NSEP] 으로 구분
news sentence 와 user sentence는 [SEP]로 구분
+ segment embedding + news segment embedding
-> candidate news 와 clicked news가 하나의 input으로 들어감
M+1개에 대해 BERT를 한번 더
(NRMS처럼 뉴스 간 연관성을 보기 위함)
word-level [CLS] - word level signal
news-level [CLS] - 기존 news-level signal
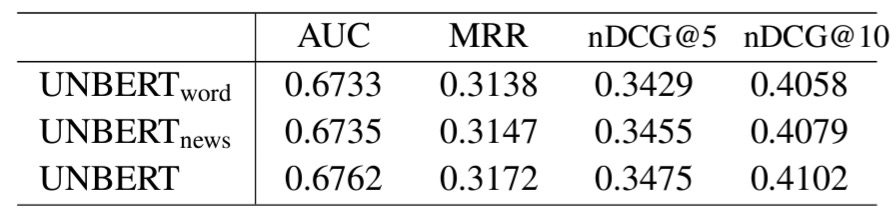
결론 : word-level & news-level 다 쓰는게 좋더라.
Approach 2. 클릭로그 + 제목 + 본문
⑤ NAML ( Neural news recommendation with attentive multi-view learning. )
Wu, Chuhan, et al. "Neural news recommendation with attentive multi-view learning."
https://arxiv.org/pdf/1907.05576
뉴스를 나타내는 다른 정보들 (예. category, title, body)
뉴스 유형마다 title, body 중요도가 다를 것.
LSTUR처럼
title, body - pretrained word embedding
queyr - random init
title과 body에서 중요한 단어가 다를 것이다. (성격이 다름)
⑥ CAST
Kim, Taeho, et al. "Is it enough just looking at the title? Leveraging body text to enrich title words towards accurate news recommendation."
https://scholarworks.bwise.kr/hanyang/bitstream/2021.sw.hanyang/188587/1/3511808.3557619.pdf
의문 : 클릭시 본문 정보를 못 보는데 왜 쓰지?
본문 정보를 NAML처럼 쓰면 안된다.
사용자에게는 배경지식이 있음
title 자체에는 배경지식이 없음
제목에 있는 단어의 추가적인 의미를 파악하기 위해 뭘 쓸 수 있을까?
왜 knowledge graph를 쓰지?
각 단어가 맥락에 따라 의미가 다를 수 있을텐데? - 본문에 가장 잘 나타나 있을 것이다.
배경지식을 본문으로부터!
candidate aware attention - 다른 분야에서도 많이 쓰는 방법
why? user interest is diverse, 그 중 candidate 뉴스와 관련 있는 것 중에서 봐야하지 않을까?
제목을 어떻게 represent할 것인가가 핵심이다보니 news encoder가 복잡함.
selection module - body 와 title top_n개 similarity
key, value - title 단어 한개. top_n개 body 단어
query - title 단어
핵심 :
1. selection module을 왜 썼는지
2. body가 context를 가장 잘 represent 하는지
결론 : selection module이 꽤 효과적이다.
Approach 3. 클릭로그 + 제목 + 본문 + 체류시간
⑦ CPRS - 체류시간 (dwell time) -> 본문이 꼭 필요한 부분
Wu, Chuhan, et al. "User Modeling with Click Preference and Reading Sa7sfac7on for News Recommendation."
https://www.ijcai.org/Proceedings/2020/0418.pdf
motivation : 클릭 로그만 쓰면 안된다. why? clickbait - 잘못 클릭한 경우
만족도를 보려면 체류시간을 봐야한다.
but 사용자마다 읽는 속도가 다름
상대적인 체류시간 personalized reading speed
user representation이 두개가 나옴. - 적절히 attention 함
최종 user representation
click score - click 확률 예측
satisfaction score - for parameter update
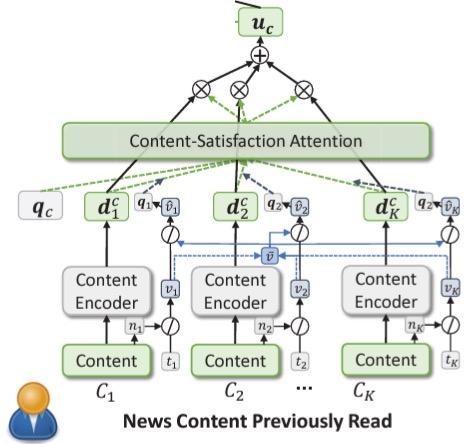
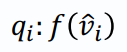
qi <- fully connected layer 로 vector 를 구함
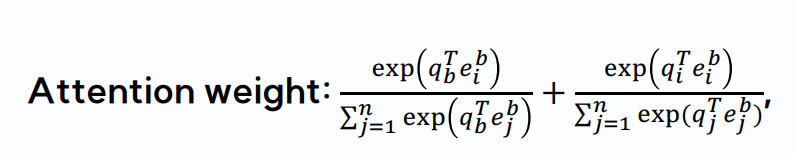
여기에 두번째 term 이 추가 됨
1. 뉴스의 길이 고려 필요
2. personalized reading speed가 더 중요
만족도 score가 user의 관심도를 반영하게 됨
title / content / satisfaction / behavior attention
Approach 4. 클릭로그 + 제목 + knowledge graph entities
⑧ DKN
Wang, Hongwei, et al. "DKN: Deep knowledge-aware network for news recommendation."
https://arxiv.org/pdf/1801.08284
motivation : 함축적인 title 때문
KCNN - news encoder
candidate news를 query로 써서 - why? candidate news와 관련있는 attention 계산위함
concat -> MLP layer
주변 entity까지 context 정보로 활용
(knowledge graph embedding 분야가 따로 있음.)
채널 3개인 CNN
⑨ HieRec
Qi, Tao, et al. "HieRec: Hierarchical user interest modeling for personalized news recommendation."
https://arxiv.org/pdf/2106.04408
motif가 완전히 다름 - user interest is diverse - topic, subtopic
기존 : 하나의 embedding으로 표현한게 문제
다양한 topic - 세분화된 subtopic
핵심 : subtopic
전체 interest로만 보는건 부족하다
news encoder
agg. title & knowledge graph의 entities
3개의 matching score (dot-product) 를 weighted sum
연구시 motivation 이 중요함
특징 : click시 시나리오가 있을 것이다.
사용할 수 있는 정보가 많을텐데 + 어느 레벨로 쓸지도
연구를 더 한다면
뉴스 추천의 정확도
워드 임베딩 부분에 초점을 맞춰볼 것 같다 - 언어모델의 성능이 많이 좋아졌기 때문에
but 이건 어디까지나 연구적인 측면
real-world application은 popularity를 사용하기도...
수강생들에게 질문 : news recommendation은 collaborative filtering이라고 볼 수 없을까?
user ID embedding, item 에 대한 embedding - interaction 정보가 반영될 여지가 있다.
- collaborative filtering의 개념도 녹아들어 있다.
LLM의 세상에서 이미 only collaborative filtering은 없는 것 같다.
'패스트러너 기자단 4기' 카테고리의 다른 글
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #11 5월 캠프콘 (0) | 2024.05.31 |
|---|---|
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #09_멘토링 (0) | 2024.05.10 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #08_미니 프로젝트 - Upstage 경진대회 #2 (0) | 2024.04.24 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #06_미니 프로젝트 - Upstage 경진대회 #1 (0) | 2024.04.04 |
| [패스트캠퍼스 Upstage AI Lab 2기 부트캠프] #05_그룹스터디 (1) 첫번째 그룹세미나 (0) | 2024.03.18 |



